MELD
1.0.0
Jika Anda tertarik dengan tes IQ LLM, lihat karya baru kami: AlgoPuzzleVQA
Kami telah merilis fitur visual yang diekstraksi menggunakan Resnet - https://github.com/declare-lab/MM-Align
Untuk baseline yang diperbarui, silakan kunjungi tautan ini: conv-emotion
Untuk mengunduh data gunakan wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
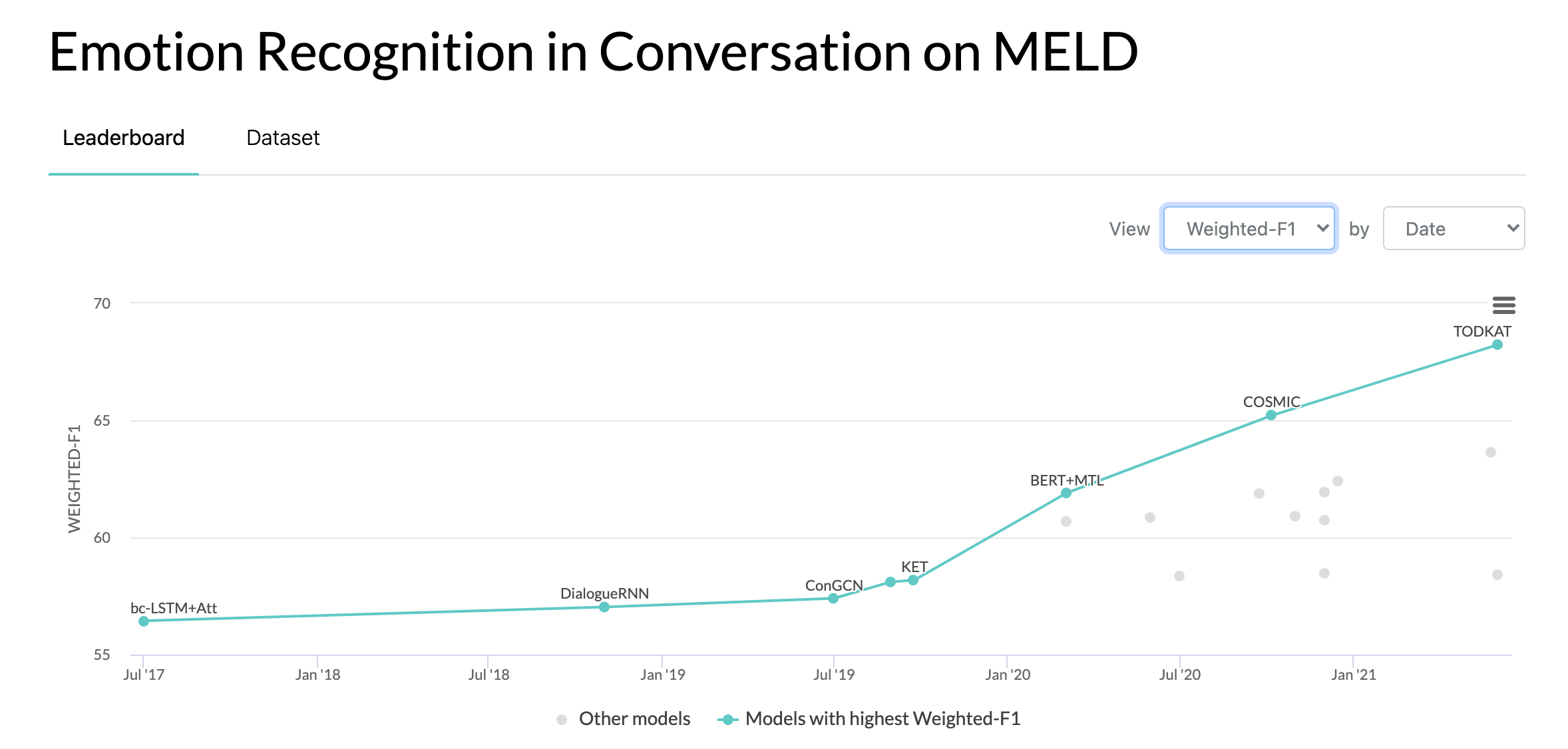
10/10/2020: Makalah baru dan SOTA dalam Pengenalan Emosi dalam Percakapan pada kumpulan data MELD. Lihat direktori COSMIC untuk kodenya. Baca makalah -- COSMIC: Pengetahuan COmmonSense untuk Identifikasi eMotion dalam Percakapan.
22/05/2019: MELD: Kumpulan Data Multimodal Multi-Partai untuk Pengenalan Emosi dalam Percakapan telah diterima sebagai makalah lengkap di ACL 2019. Makalah yang diperbarui dapat ditemukan di sini - https://arxiv.org/pdf/1810.02508. pdf
22/05/2019: Dyadic MELD telah dirilis. Ini dapat digunakan untuk menguji model percakapan diadik.
15/11/2018: Masalah di train.tar.gz telah diperbaiki.
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang, dan Panpan Wang. "Jaringan Interaktif Terinspirasi Quantum untuk Analisis Sentimen Percakapan." IJCAI 2019.
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu, dan Guodong Zhou. "Memodelkan Ketergantungan Konteks dan Sensitif Pembicara untuk Deteksi Emosi dalam Percakapan Multi-pembicara." IJCAI 2019.
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya, dan Alexander Gelbukh. "DialogueGCN: Jaringan Neural Konvolusional Grafik untuk Pengenalan Emosi dalam Percakapan." EMNLP 2019.
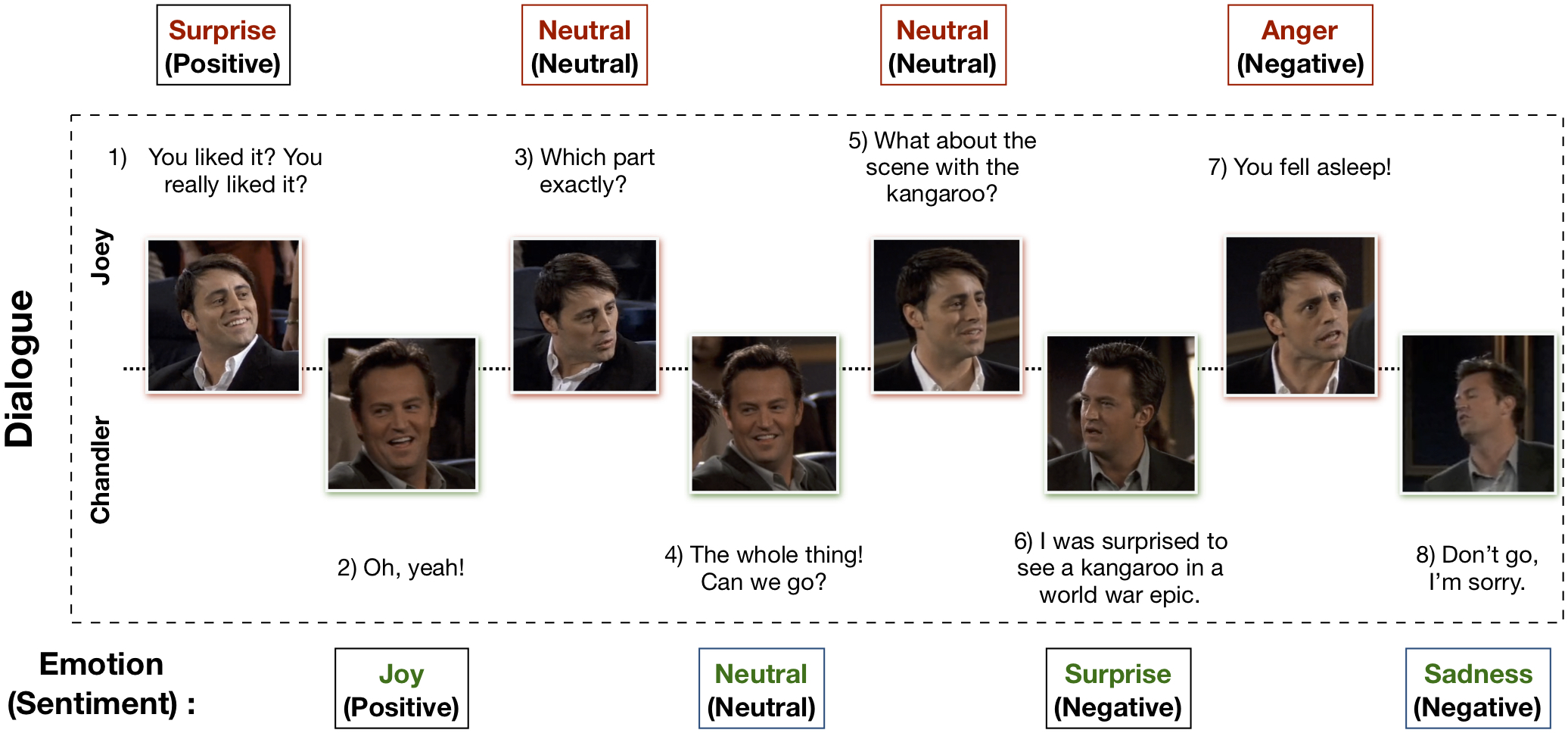
Kumpulan Data EmotionLines Multimodal (MELD) telah dibuat dengan menyempurnakan dan memperluas kumpulan data EmotionLines. MELD berisi contoh dialog yang sama dengan yang tersedia di EmotionLines, tetapi juga mencakup modalitas audio dan visual bersama dengan teks. MELD memiliki lebih dari 1400 dialog dan 13000 ucapan dari serial TV Friends. Sejumlah pembicara berpartisipasi dalam dialog tersebut. Setiap ucapan dalam dialog diberi label oleh salah satu dari tujuh emosi berikut -- Marah, Jijik, Sedih, Sukacita, Netral, Terkejut, dan Takut. MELD juga memiliki anotasi sentimen (positif, negatif, dan netral) untuk setiap ucapan.
| Statistik | Kereta | Dev | Tes |
|---|---|---|---|
| # modalitas | {a,v,t} | {a,v,t} | {a,v,t} |
| # kata-kata unik | 10.643 | 2.384 | 4.361 |
| Rata-rata panjang ucapan | 8.03 | 7.99 | 8.28 |
| Maks. panjang ucapan | 69 | 37 | 45 |
| Rata-rata # emosi per dialog | 3.30 | 3.35 | 3.24 |
| # dialog | 1039 | 114 | 280 |
| # ucapan | 9989 | 1109 | 2610 |
| # pembicara | 260 | 47 | 100 |
| # pergeseran emosi | 4003 | 427 | 1003 |
| Rata-rata durasi suatu ucapan | 3,59 detik | 3,59 detik | 3,58 detik |
Silakan kunjungi https://affective-meld.github.io untuk detail lebih lanjut.
| Kereta | Dev | Tes | |
|---|---|---|---|
| Amarah | 1109 | 153 | 345 |
| Menjijikkan | 271 | 22 | 68 |
| Takut | 268 | 40 | 50 |
| Sukacita | 1743 | 163 | 402 |
| Netral | 4710 | 470 | 1256 |
| Kesedihan | 683 | 111 | 208 |
| Kejutan | 1205 | 150 | 281 |
Analisis data multimodal memanfaatkan informasi dari berbagai saluran data paralel untuk pengambilan keputusan. Dengan pesatnya pertumbuhan AI, pengenalan emosi multimodal telah mendapatkan perhatian penelitian yang besar, terutama karena potensi penerapannya dalam banyak tugas yang menantang, seperti pembuatan dialog, interaksi multimodal, dll. Sistem pengenalan emosi percakapan dapat digunakan untuk menghasilkan respons yang tepat dengan menganalisis emosi pengguna. Meskipun ada banyak penelitian yang dilakukan mengenai pengenalan emosi multimodal, hanya sedikit yang benar-benar fokus pada pemahaman emosi dalam percakapan. Namun, pekerjaan mereka hanya terbatas pada pemahaman percakapan diadik dan oleh karena itu tidak dapat diskalakan pada pengenalan emosi dalam percakapan multi-pihak yang memiliki lebih dari dua peserta. EmotionLines dapat digunakan sebagai sumber pengenalan emosi hanya untuk teks, karena tidak menyertakan data dari modalitas lain seperti visual dan audio. Pada saat yang sama, perlu dicatat bahwa tidak ada kumpulan data percakapan multi-pihak multimodal yang tersedia untuk penelitian pengenalan emosi. Dalam pekerjaan ini, kami telah memperluas, meningkatkan, dan mengembangkan lebih lanjut kumpulan data EmotionLines untuk skenario multimodal. Pengenalan emosi secara berurutan memiliki beberapa tantangan dan pemahaman konteks adalah salah satunya. Perubahan emosi dan aliran emosi dalam rangkaian dialog membuat pemodelan konteks yang akurat menjadi tugas yang sulit. Dalam kumpulan data ini, karena kami memiliki akses ke sumber data multimodal untuk setiap dialog, kami berhipotesis bahwa hal ini akan meningkatkan pemodelan konteks sehingga memberi manfaat pada kinerja pengenalan emosi secara keseluruhan. Kumpulan data ini juga dapat digunakan untuk mengembangkan sistem dialog afektif multimodal. IEMOCAP, SEMAINE adalah kumpulan data percakapan multimodal yang berisi label emosi untuk setiap ucapan. Namun, kumpulan data ini bersifat diadik, yang membenarkan pentingnya kumpulan data Multimodal-EmotionLines kami. Kumpulan data pengenalan sentimen dan emosi multimodal lainnya yang tersedia untuk umum adalah MOSEI, MOSI, MOUD. Namun, tidak satu pun dari kumpulan data tersebut yang bersifat percakapan.
Langkah pertama berkaitan dengan menemukan stempel waktu setiap ucapan di setiap dialog yang ada dalam kumpulan data EmotionLines. Untuk mencapai hal ini, kami menelusuri file subtitle dari semua episode yang berisi stempel waktu awal dan akhir ucapan. Proses ini memungkinkan kami memperoleh ID musim, ID episode, dan stempel waktu dari setiap ucapan dalam episode tersebut. Kami memberikan dua batasan saat memperoleh stempel waktu: (a) stempel waktu ucapan dalam dialog harus dalam urutan yang meningkat, (b) semua ucapan dalam dialog harus berasal dari episode dan adegan yang sama. Batasan kedua kondisi ini menunjukkan bahwa di EmotionLines, beberapa dialog terdiri dari beberapa dialog alami. Kami menyaring kasus-kasus tersebut dari kumpulan data. Karena langkah koreksi kesalahan ini, dalam kasus kami, kami memiliki jumlah dialog yang berbeda dibandingkan dengan EmotionLines. Setelah mendapatkan stempel waktu setiap ucapan, kami mengekstrak klip audio visual yang sesuai dari episode sumber. Secara terpisah, kami juga mengeluarkan konten audio dari klip video tersebut. Terakhir, kumpulan data berisi modalitas visual, audio, dan tekstual untuk setiap dialog.
Makalah yang menjelaskan kumpulan data ini dapat ditemukan - https://arxiv.org/pdf/1810.02508.pdf
Silakan kunjungi - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz untuk mengunduh data mentah. Data disimpan dalam format .mp4 dan dapat ditemukan dalam file XXX.tar.gz. Anotasi dapat ditemukan di https://github.com/declare-lab/MELD/tree/master/data/MELD.
| Nama Kolom | Keterangan |
|---|---|
| Tuan Tidak. | Nomor seri ucapan terutama untuk merujuk pada ucapan jika versinya berbeda atau salinannya banyak dengan subset berbeda |
| Ucapan | Ucapan individu dari EmotionLines sebagai string. |
| Pembicara | Nama pembicara yang terkait dengan ucapannya. |
| Emosi | Emosi (netral, gembira, sedih, marah, terkejut, takut, jijik) yang diungkapkan penutur dalam tuturannya. |
| Sentimen | Sentimen (positif, netral, negatif) yang diungkapkan penutur dalam tuturannya. |
| Dialog_ID | Indeks dialog dimulai dari 0. |
| Ucapan_ID | Indeks ujaran tertentu dalam dialog dimulai dari 0. |
| Musim | Musim no. Acara TV Friends yang memuat ucapan tertentu. |
| Episode | Episode no. Acara TV Friends pada musim tertentu di mana ucapan tersebut berasal. |
| Waktu Mulai | Waktu mulai ujaran pada episode tertentu dengan format 'hh:mm:ss,ms'. |
| Akhir Waktu | Waktu akhir ujaran pada episode tertentu dengan format 'hh:mm:ss,ms'. |
Ada 13 file acar yang berisi data dan fitur yang digunakan untuk melatih model dasar. Berikut adalah penjelasan singkat dari masing-masing file acar.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))Ada 2 skrip python yang disediakan di './utils/':
Untuk eksperimen, semua label direpresentasikan sebagai pengkodean one-hot, indeksnya adalah sebagai berikut:
Sebagai dasar klasifikasi emosi, bobot kelas berikut digunakan. Pengindeksannya sama seperti yang disebutkan di atas. Bobot Kelas: [4.0, 15.0, 15.0, 3.0, 1.0, 6.0, 3.0].
Silakan ikuti langkah-langkah berikut untuk menjalankan baseline -
./data/pickles/baseline/baseline.py sebagai berikut:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h untuk mendapatkan teks bantuan untuk parameter../data/models/ . Silakan kutip makalah berikut jika Anda merasa kumpulan data ini berguna dalam penelitian Anda
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: Kumpulan Data Multi-Pihak Multimodal untuk Pengenalan Emosi dalam Percakapan. ACL 2019.
Chen, SY, Hsu, CC, Kuo, CC dan Ku, LW EmotionLines: Korpus Emosi Percakapan Multi-Pihak. arXiv pracetak arXiv:1802.08379 (2018).
Kumpulan Data Deteksi Emosi EmoryNLP Multimodal telah dibuat dengan menyempurnakan dan memperluas kumpulan data Deteksi Emosi EmoryNLP. Ini berisi contoh dialog yang sama yang tersedia dalam kumpulan data Deteksi Emosi EmoryNLP, tetapi juga mencakup modalitas audio dan visual bersama dengan teks. Ada lebih dari 800 dialog dan 9000 ucapan dari serial TV Friends yang ada di kumpulan data multimodal EmoryNLP. Beberapa pembicara berpartisipasi dalam dialog. Setiap ucapan dalam dialog diberi label oleh salah satu dari tujuh emosi berikut -- Netral, Gembira, Damai, Kuat, Takut, Gila, dan Sedih. Anotasi dipinjam dari kumpulan data asli.
| Statistik | Kereta | Dev | Tes |
|---|---|---|---|
| # modalitas | {a,v,t} | {a,v,t} | {a,v,t} |
| # kata-kata unik | 9.744 | 2.123 | 2.345 |
| Rata-rata panjang ucapan | 7.86 | 6.97 | 7.79 |
| Maks. panjang ucapan | 78 | 60 | 61 |
| Rata-rata # emosi per adegan | 4.10 | 4.00 | 4.40 |
| # dialog | 659 | 89 | 79 |
| # ucapan | 7551 | 954 | 984 |
| # pembicara | 250 | 46 | 48 |
| # pergeseran emosi | 4596 | 575 | 653 |
| Rata-rata durasi suatu ucapan | 5,55 detik | 5,46 detik | 5,27 detik |
| Kereta | Dev | Tes | |
|---|---|---|---|
| Menyenangkan | 1677 | 205 | 217 |
| Gila | 785 | 97 | 86 |
| Netral | 2485 | 322 | 288 |
| Tenang | 638 | 82 | 111 |
| Kuat | 551 | 70 | 96 |
| Sedih | 474 | 51 | 70 |
| Takut | 941 | 127 | 116 |
Klip video dataset ini dapat diunduh dari tautan ini. File anotasi dapat ditemukan di https://github.com/SenticNet/MELD/tree/master/data/emorynlp. Ada 3 file .csv. Setiap entri di kolom pertama file csv ini berisi ucapan yang klip videonya dapat ditemukan di sini. Setiap ucapan dan klip videonya diindeks berdasarkan nomor musim, nomor episode, id adegan, dan id ucapan. Misalnya, sea1_ep2_sc6_utt3.mp4 menyiratkan klip tersebut sesuai dengan ucapan dengan musim no. 1, episode no. 2, scene_id 6 dan ucapan_id 3. Sebuah adegan hanyalah sebuah dialog. Pengindeksan ini konsisten dengan kumpulan data asli. File .csv dan file video dibagi menjadi set pelatihan, validasi, dan pengujian sesuai dengan dataset asli. Anotasi dipinjam langsung dari kumpulan data EmoryNLP asli (Zahiri dkk. (2018)).
| Nama Kolom | Keterangan |
|---|---|
| Ucapan | Ucapan individu dari EmoryNLP sebagai string. |
| Pembicara | Nama pembicara yang terkait dengan ucapannya. |
| Emosi | Emosi (Netral, Gembira, Damai, Kuat, Takut, Gila dan Sedih) yang diungkapkan penutur dalam tuturannya. |
| Adegan_ID | Indeks dialog dimulai dari 0. |
| Ucapan_ID | Indeks ujaran tertentu dalam dialog dimulai dari 0. |
| Musim | Musim no. Acara TV Friends yang memuat ucapan tertentu. |
| Episode | Episode no. Acara TV Friends pada musim tertentu di mana ucapan tersebut berasal. |
| Waktu Mulai | Waktu mulai ujaran pada episode tertentu dengan format 'hh:mm:ss,ms'. |
| Akhir Waktu | Waktu akhir ujaran pada episode tertentu dengan format 'hh:mm:ss,ms'. |
Catatan : Ada beberapa ucapan yang kami tidak dapat menemukan waktu mulai dan berakhirnya karena beberapa ketidakkonsistenan dalam subjudulnya. Ucapan seperti itu telah dihilangkan dari kumpulan data. Namun, kami mendorong pengguna untuk menemukan ucapan yang sesuai dari kumpulan data asli dan membuat klip video yang sama.
Silakan kutip makalah berikut jika Anda merasa kumpulan data ini berguna dalam penelitian Anda
S. Zahiri dan JD Choi. Deteksi Emosi pada Transkrip Acara TV dengan Jaringan Neural Konvolusional Berbasis Urutan. Dalam Lokakarya AAAI tentang Analisis Konten Afektif, AFFCON'18, 2018.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: Kumpulan Data Multi-Pihak Multimodal untuk Pengenalan Emosi dalam Percakapan. ACL 2019.


