ChatLearner
1.0.0
Chatbot diimplementasikan di TensorFlow berdasarkan model sequence to sequence (NMT) baru, dengan aturan tertentu yang terintegrasi dengan lancar.
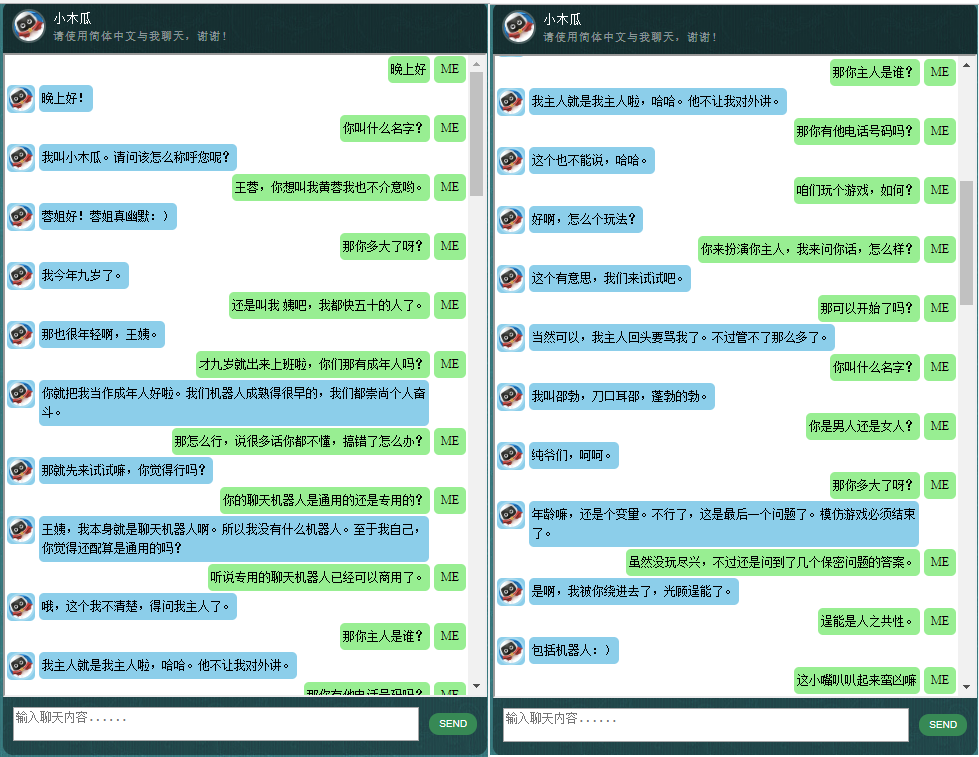
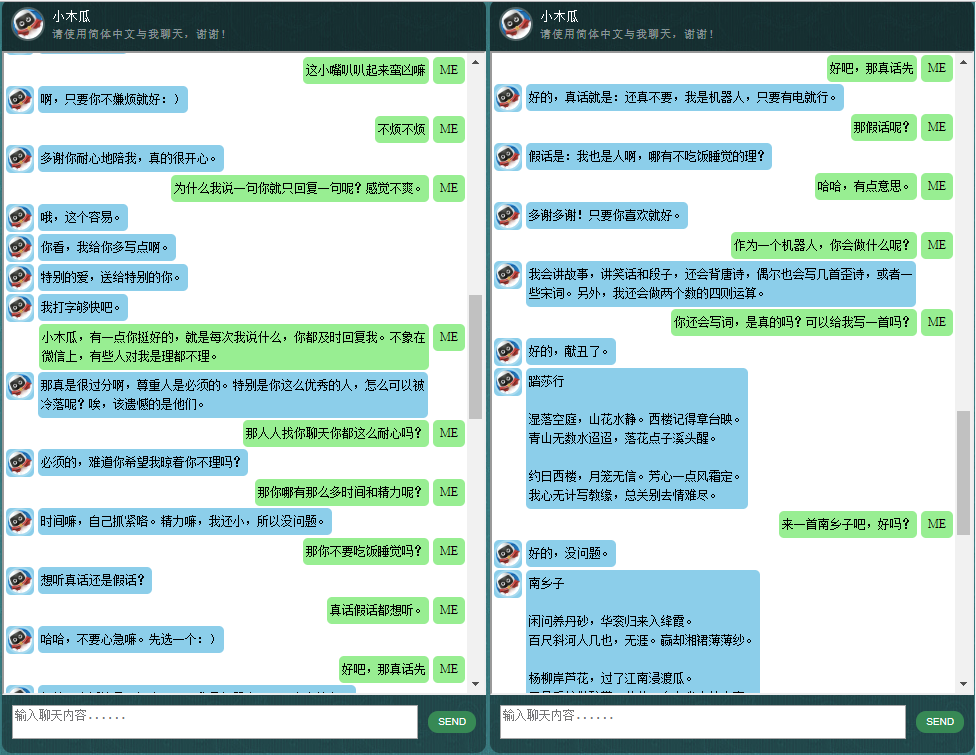
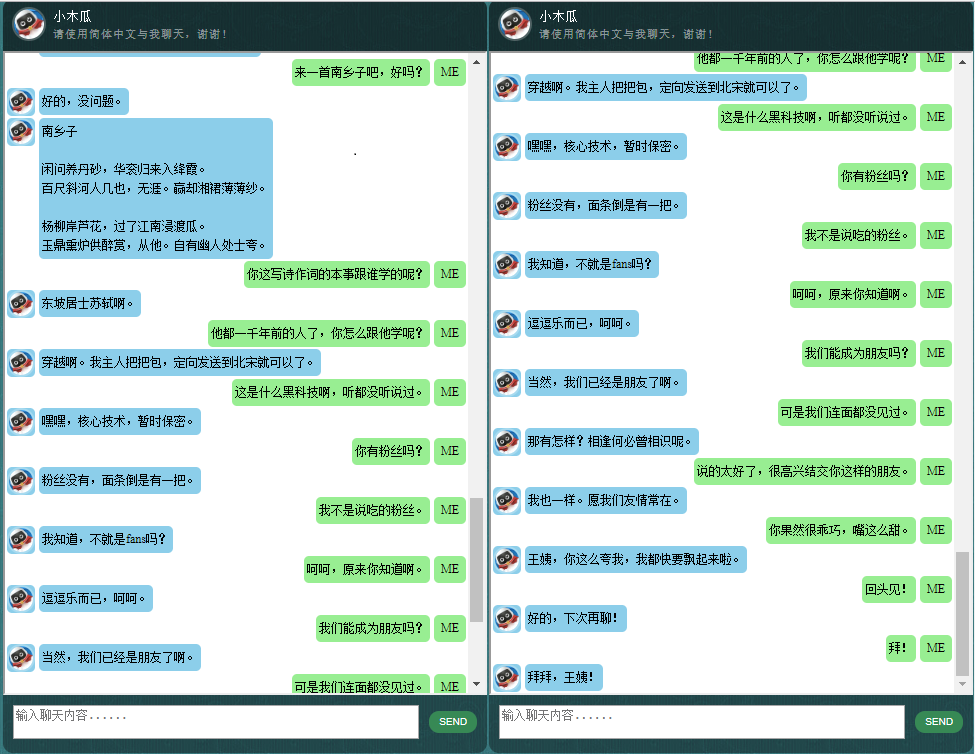
Bagi yang tertarik dengan chatbot berbahasa Mandarin, silakan cek di sini.
Inti dari ChatLearner (Pepaya) dibangun pada model NMT (https://github.com/tensorflow/nmt), yang telah diadaptasi di sini agar sesuai dengan kebutuhan chatbot. Karena perubahan yang dilakukan pada tf.data API di TensorFlow 1.4 dan banyak perubahan lainnya sejak TensorFlow 1.12, versi ChatLearner ini hanya mendukung TF versi 1.4 hingga 1.11. Pembaruan mudah dapat dilakukan di file tokenizeddata.py jika Anda perlu mendukung TensorFlow 1.12.
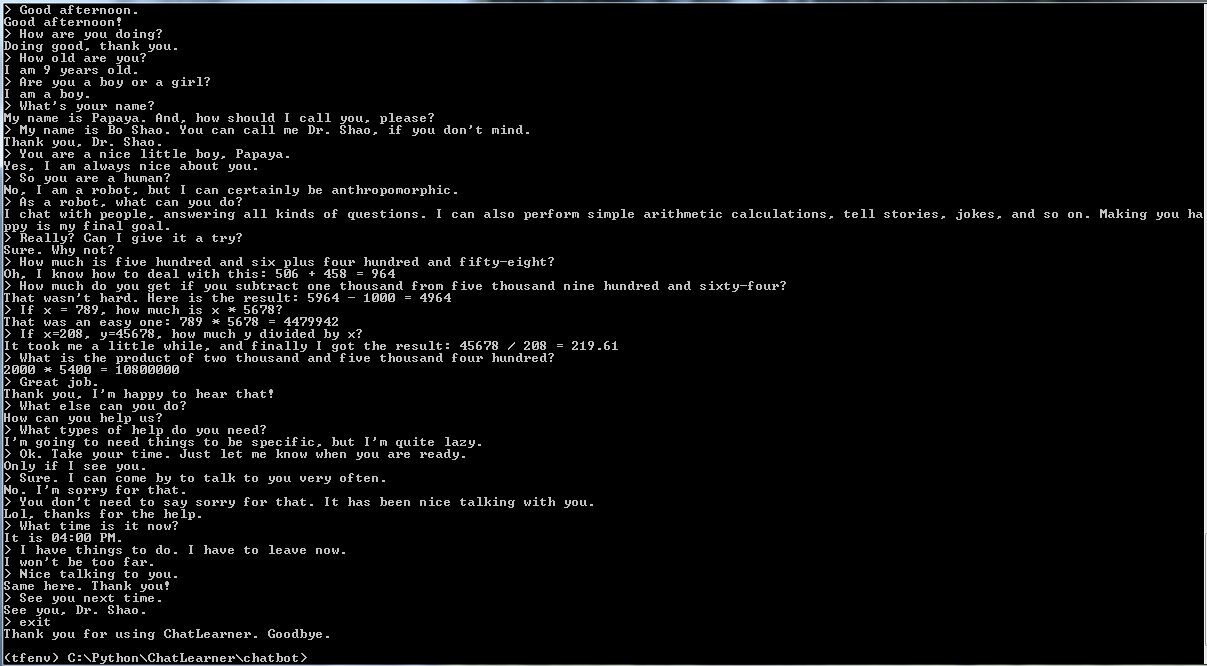
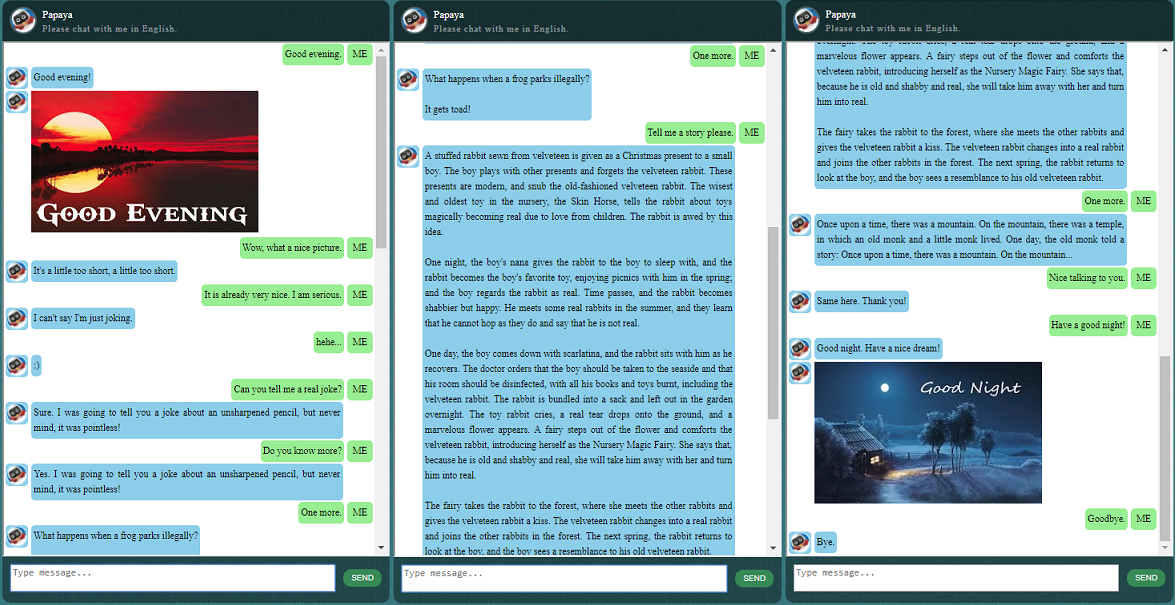
Sebelum memulai yang lainnya, Anda mungkin ingin mengetahui bagaimana perilaku ChatLearner. Lihatlah contoh percakapan di bawah atau di sini, atau jika Anda lebih suka mencoba model terlatih saya, unduh di sini. Buka zip file .rar yang diunduh, dan salin folder Hasil ke folder Data di bawah root proyek Anda. File vocab.txt juga disertakan jika saya memperbaruinya tanpa memperbarui model yang dilatih di masa mendatang.
Mengapa Anda ingin menghabiskan waktu memeriksa repositori ini? Berikut beberapa kemungkinan alasannya:
Kumpulan Data Pepaya untuk melatih chatbot. Anda dapat dengan mudah menemukan banyak sekali data pelatihan online, tetapi Anda tidak dapat menemukannya dengan kualitas setinggi itu. Lihat penjelasan rinci di bawah tentang kumpulan data.
Gaya kode yang ringkas dan implementasi yang jelas dari model seq2seq baru berdasarkan RNN dinamis (alias model NMT baru). Ini disesuaikan untuk chatbots dan lebih mudah dipahami dibandingkan dengan tutorial resmi.
Ide untuk menggunakan ChatSession yang terintegrasi dengan mulus untuk menangani konteks percakapan dasar.
Beberapa aturan diintegrasikan untuk mendemonstrasikan cara menggabungkan chatbot berbasis aturan tradisional dengan model pembelajaran mendalam yang baru. Betapapun hebatnya model pembelajaran mendalam, ia bahkan tidak dapat menjawab pertanyaan-pertanyaan yang membutuhkan perhitungan aritmatika sederhana, dan banyak lainnya. Pendekatan yang ditunjukkan di sini dapat dengan mudah diadaptasi untuk mengambil berita atau informasi online lainnya. Dengan diterapkannya aturan, maka banyak pertanyaan menarik dapat dijawab dengan baik. Misalnya:
Jika Anda tidak tertarik dengan aturan, Anda dapat dengan mudah menghapus baris yang terkait dengan Knowledgebase.py dan Functiondata.py.
Layanan web berbasis SOAP (dan alternatif berbasis REST-API, jika Anda tidak suka menggunakan SOAP) memungkinkan Anda menyajikan GUI di Java, sementara model dilatih dan dijalankan dengan Python dan TensorFlow.
Solusi sederhana (dalam grafik) untuk mengonversi tensor string menjadi huruf kecil di TensorFlow. Hal ini diperlukan jika Anda menggunakan DataSet API baru (tf.data.TextLineDataSet) di TensorFlow untuk memuat data pelatihan dari file teks.
Repositori juga berisi implementasi chatbot berdasarkan model seq2seq lama. Jika Anda tertarik, silakan periksa cabang Legacy_Chatbot di https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot.
Kumpulan Data Pepaya adalah data percakapan bahasa Inggris gratis terbaik (terbersih dan terorganisir dengan baik) yang dapat Anda temukan di web untuk melatih chatbot. Berikut beberapa detailnya:
Data terdiri dari dua set: set pertama dibuat dengan tangan, dan kami membuat sampel untuk menjaga konsistensi peran chatbot, yang oleh karena itu dapat dilatih untuk bersikap sopan, sabar, humoris, filosofis, dan sadar bahwa dia adalah orang yang tepat. robot, tapi berpura-pura menjadi anak laki-laki berusia 9 tahun bernama Pepaya; set kedua dibersihkan dari beberapa sumber online, termasuk percakapan skenario yang dirancang untuk melatih robot, dialog film Cornell, dan membersihkan data Reddit.
Kumpulan data pelatihan dibagi menjadi tiga kategori: dua subset akan ditambah/diulang selama pelatihan, dengan level atau waktu berbeda, sedangkan subset ketiga tidak. Subset yang ditambah bertujuan untuk melatih model dengan aturan yang harus diikuti, serta sejumlah pengetahuan dan akal sehat, sedangkan subset ketiga hanya untuk membantu melatih model bahasa.
Percakapan skenario diekstraksi dan diatur ulang dari http://www.eslfast.com/robot/. Jika model Anda dapat mendukung konteks, model tersebut akan bekerja lebih baik dengan memanfaatkan percakapan ini.
Kumpulan data Cornell asli dapat ditemukan di sini. Kami membersihkannya menggunakan skrip Python (skrip juga dapat ditemukan di folder Corpus); kami kemudian membersihkannya secara manual dengan mencari pola tertentu secara cepat.
Untuk data Reddit, subset yang telah dibersihkan (sekitar 110 ribu pasang) disertakan dalam repositori ini. File vocab dan parameter model dibuat dan disesuaikan berdasarkan semua file data yang disertakan. Jika Anda memerlukan kumpulan yang lebih besar, Anda juga dapat menemukan skrip untuk mengurai dan membersihkan komentar Reddit di folder Corpus/RedditData. Untuk menggunakan skrip tersebut, Anda perlu mengunduh torrent komentar Reddit dari tautan torrent di sini. Biasanya satu bulan komentar sudah cukup besar (kira-kira dapat menghasilkan 3 juta pasang sampel pelatihan). Anda dapat menyesuaikan parameter dalam skrip berdasarkan kebutuhan Anda.
File data dalam kumpulan data ini telah diproses sebelumnya dengan tokenizer NLTK sehingga siap dimasukkan ke dalam model menggunakan tf.data API baru di TensorFlow.
Pastikan Anda memiliki versi TensorFlow yang benar. Ini hanya berfungsi dengan TensorFlow 1.4, bukan rilis sebelumnya karena tf.data API yang digunakan di sini baru saja diperbarui di TF 1.4.
Harap pastikan Anda memiliki pengaturan PYTHONPATH variabel lingkungan. Itu harus mengarah ke direktori root proyek, di mana Anda memiliki folder chatbot, Data, dan webui. Jika Anda menjalankan IDE, seperti PyCharm, itu akan dibuatkan untuk Anda. Tetapi jika Anda menjalankan skrip python apa pun di baris perintah, Anda harus memiliki variabel lingkungan tersebut, jika tidak, Anda akan mendapatkan kesalahan impor modul.
Harap pastikan Anda menggunakan file vocab.txt yang sama untuk pelatihan dan inferensi/prediksi. Ingatlah bahwa model Anda tidak akan pernah melihat kata apa pun seperti kami. Semuanya berupa bilangan bulat masuk, bilangan bulat keluar, sedangkan kata dan urutannya di vocab.txt membantu memetakan antara kata dan bilangan bulat.
Luangkan sedikit waktu untuk memikirkan seberapa besar model Anda seharusnya, berapa panjang maksimum encoder/decoder, ukuran kumpulan kosakata, dan berapa banyak pasangan data pelatihan yang ingin Anda gunakan. Perlu diketahui bahwa suatu model memiliki batas kapasitas: berapa banyak data yang dapat dipelajari atau diingat. Jika Anda memiliki jumlah lapisan, jumlah unit, jenis sel RNN (seperti GRU) yang tetap, dan Anda memutuskan panjang encoder/decoder, ukuran kosakatalah yang paling memengaruhi kemampuan model Anda untuk belajar, bukan jumlah sampel pelatihan. Jika Anda dapat mengatur untuk tidak membiarkan ukuran kosakata bertambah saat Anda menggunakan lebih banyak data pelatihan, hal ini mungkin akan berhasil, namun kenyataannya adalah ketika Anda memiliki lebih banyak sampel pelatihan, ukuran kosakata juga meningkat dengan sangat cepat, dan Anda mungkin akan menyadarinya. model Anda tidak dapat menampung data sebesar itu sama sekali. Jangan ragu untuk membuka masalah untuk didiskusikan jika Anda mau.
Selain Python 3.6 (3.5 juga bisa digunakan), Numpy, dan TensorFlow 1.4. Anda juga memerlukan NLTK (Natural Language Toolkit) versi 3.2.4 (atau 3.2.5).
Selama pelatihan, saya sangat menyarankan Anda untuk mencoba bermain dengan parameter (colocation_gradients_with_ops) di fungsi tf.gradients. Anda dapat menemukan baris seperti ini di modelcreator.py: gradien = tf.gradients(self.train_loss, params). Setel colocation_gradients_with_ops=True (tambahkan) dan jalankan pelatihan setidaknya untuk satu periode, catat waktunya, lalu setel ke False (atau hapus saja) dan jalankan pelatihan setidaknya untuk satu periode dan lihat apakah waktu yang diperlukan untuk satu zaman berbeda nyata. Setidaknya bagi saya ini mengejutkan.
Selain itu, pelatihannya mudah. Ingatlah untuk membuat folder bernama Hasil di bawah folder Data terlebih dahulu. Kemudian jalankan saja perintah berikut:
cd chatbot
python bottrainer.pyGPU yang bagus sangat disarankan untuk pelatihan karena bisa sangat memakan waktu. Jika Anda memiliki beberapa GPU, memori dari semua GPU akan digunakan oleh TensorFlow, dan Anda dapat menyesuaikan parameter batch_size di file hparams.json agar dapat memanfaatkan memori sepenuhnya. Anda akan dapat melihat hasil pelatihan di folder Data/Hasil/. Pastikan 2 file berikut ada karena semua ini diperlukan untuk pengujian dan prediksi (file .meta bersifat opsional karena model inferensi akan dibuat secara independen):
Untuk pengujian dan prediksi, kami menyediakan antarmuka perintah sederhana dan antarmuka berbasis web. Perhatikan bahwa file vocab.txt (dan file di KnowledgeBase, untuk chatbot ini) juga diperlukan untuk inferensi. Untuk memeriksa dengan cepat kinerja model yang dilatih, gunakan antarmuka perintah berikut:
cd chatbot
python botui.pyTunggu sampai Anda mendapatkan command prompt ">".
Hasil tes demo juga disediakan. Silakan periksa untuk melihat bagaimana perilaku chatbot ini sekarang: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
Arsitektur layanan web berbasis SOAP diimplementasikan, dengan server Python dan klien Java. GUI yang bagus juga disertakan untuk referensi Anda. Untuk detailnya, silakan periksa: https://github.com/bshao001/ChatLearner/tree/master/webui. Harap diperhatikan bahwa informasi tertentu (seperti gambar) hanya tersedia di antarmuka web (bukan di antarmuka baris perintah).
Alternatif berbasis REST-API juga diberikan jika SOAP bukan pilihan Anda. Untuk detailnya, silakan periksa: https://github.com/bshao001/ChatLearner/tree/master/webui_alternative. Beberapa pembaruan terkini mungkin tidak tersedia dengan opsi ini. Gabungkan perubahan dari opsi lain jika Anda perlu menggunakan ini.
Kerangka Kerja Markup NLP (以解决很) perusahaan asuransi kesehatan. )聊天机器人的开发,比如售前,售后,或特定领域(如法律,医疗)的技术咨询服务等。有兴趣的朋友欢迎微信联系。本人微信号:bshao001_miami