GenDataAttribution
1.0.0
Proyek | Kertas
Sheng-Yu Wang 1 , Alexei A. Efros 2 , Jun-Yan Zhu 1 , Richard Zhang 3 .
Universitas Carnegie Mellon 1 , UC Berkeley 2 , Penelitian Adobe 2
Di ICCV, 2023.
Meskipun model teks-ke-gambar berukuran besar mampu mensintesis gambar "baru", gambar-gambar ini tentu saja merupakan cerminan dari data pelatihan. Masalah atribusi data dalam model seperti itu -- gambar mana dalam set pelatihan yang paling bertanggung jawab atas kemunculan gambar yang dihasilkan -- adalah masalah yang sulit namun penting. Sebagai langkah awal menuju masalah ini, kami mengevaluasi atribusi melalui metode "kustomisasi", yang menyesuaikan model skala besar yang ada ke objek atau gaya contoh tertentu. Wawasan utama kami adalah bahwa hal ini memungkinkan kami membuat gambar sintetik secara efisien yang secara komputasi dipengaruhi oleh contoh konstruksi. Dengan kumpulan data baru kami yang berisi gambar-gambar yang dipengaruhi oleh contoh tersebut, kami dapat mengevaluasi berbagai algoritme atribusi data dan kemungkinan ruang fitur yang berbeda. Selain itu, dengan melatih kumpulan data, kami dapat menyesuaikan model standar, seperti DINO, CLIP, dan ViT, untuk mengatasi masalah atribusi. Meskipun prosedurnya disesuaikan dengan himpunan contoh yang kecil, kami menunjukkan generalisasi ke himpunan yang lebih besar. Terakhir, dengan mempertimbangkan ketidakpastian yang melekat pada masalah, kami dapat menetapkan skor atribusi lunak pada serangkaian gambar pelatihan.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh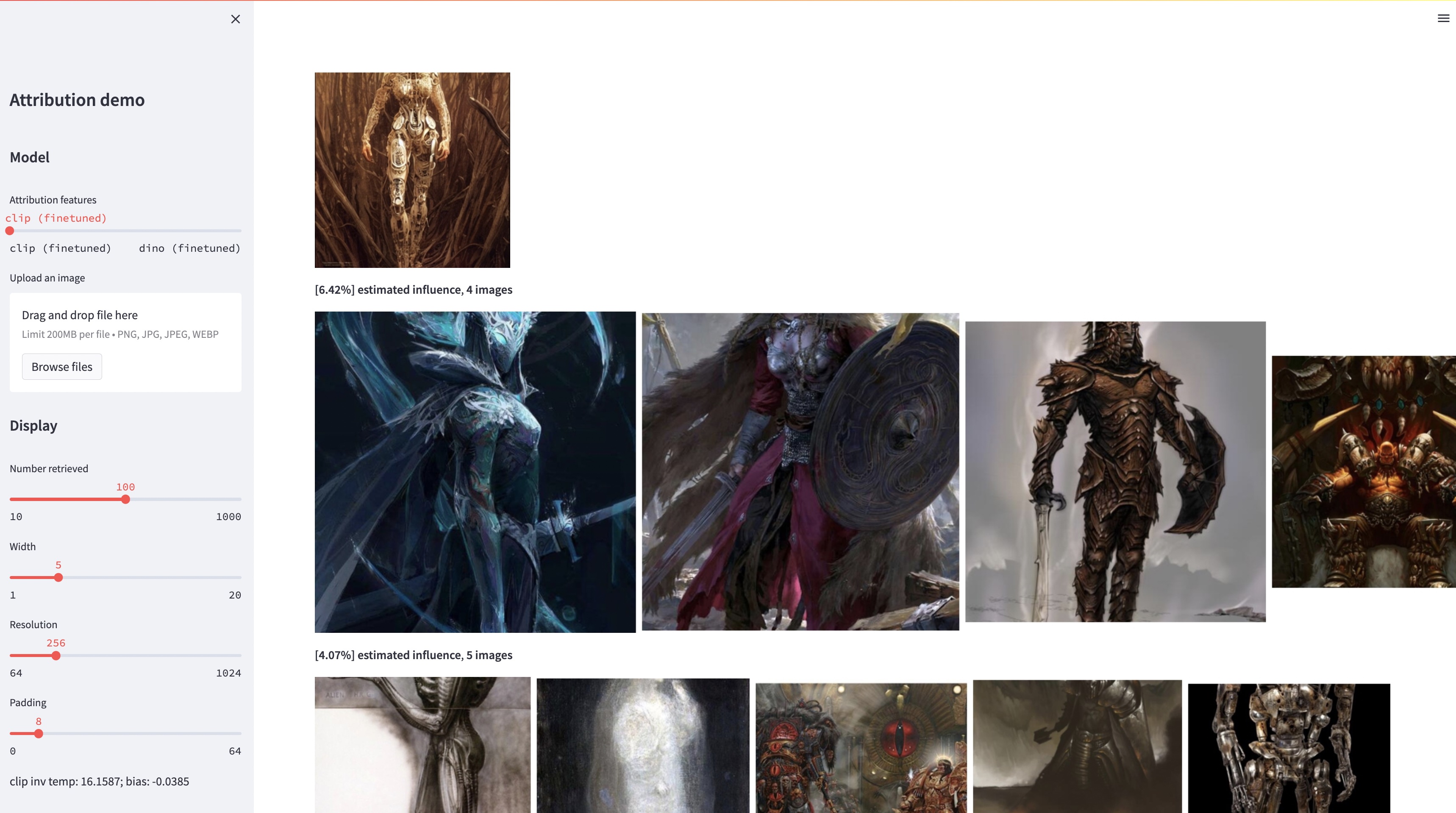
streamlit run streamlit_demo.pyKami merilis testset kami untuk evaluasi. Untuk mengunduh kumpulan data:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionKumpulan data disusun sebagai berikut:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
Semua gambar contoh disimpan dalam dataset/exemplar , semua gambar yang disintesis disimpan dalam dataset/synth , dan 1 juta gambar laion dalam png disimpan dalam dataset/laion_subset . File JSON di dataset/json menentukan pemisahan train/val/test, termasuk kasus pengujian yang berbeda, dan berfungsi sebagai label kebenaran dasar. Setiap entri di dalam file JSON adalah model unik yang telah disesuaikan. Entri juga mencatat gambar contoh yang digunakan untuk penyempurnaan dan gambar sintesis yang dihasilkan oleh model. Kami memiliki empat kasus uji: test_artchive.json , test_bamfg.json , test_observed_imagenet.json , dan test_unobserved_imagenet.json .
Setelah set pengujian, fitur LAION yang telah dihitung sebelumnya, dan bobot yang telah dilatih sebelumnya diunduh, kita dapat menghitung terlebih dahulu fitur dari set pengujian dengan menjalankan extract_feat.py , lalu mengevaluasi kinerja dengan menjalankan eval.py . Di bawah ini adalah skrip bash yang menjalankan evaluasi secara berkelompok:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh Metrik disimpan dalam file .pkl di results . Saat ini, skrip menjalankan setiap perintah secara berurutan. Silakan memodifikasinya untuk menjalankan perintah secara paralel. Perintah berikut akan menguraikan file .pkl ke dalam tabel yang disimpan sebagai file .csv :
python results_to_csv.py Pembaruan 18/12/2023 Untuk mengunduh model yang hanya dilatih pada model yang berpusat pada objek atau berpusat pada gaya, jalankan bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
Kami berterima kasih kepada Aaron Hertzmann karena telah membaca draf sebelumnya dan atas masukan yang mendalam. Kami berterima kasih kepada rekan-rekan di Adobe Research, termasuk Eli Shechtman, Oliver Wang, Nick Kolkin, Taesung Park, John Collomosse, dan Sylvain Paris, serta Alex Li dan Yonglong Tian atas diskusi yang bermanfaat. Kami menghargai Nupur Kumari atas bimbingannya dalam pelatihan Difusi Kustom, Ruihan Gao atas pembacaan bukti drafnya, Alex Li atas petunjuknya untuk mengekstrak fitur Difusi Stabil, dan Dan Ruta atas bantuannya dalam kumpulan data BAM-FG. Kami berterima kasih kepada Bryan Russell atas pendakian pandemi dan curah pendapatnya. Pekerjaan ini dimulai ketika SYW magang di Adobe dan didukung sebagian oleh hadiah Adobe dan Penghargaan Penelitian Fakultas JP Morgan Chase.


