clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
Berbagi GPU kelas atas atau bahkan GPU prosumer & konsumen antara banyak pengguna adalah cara paling hemat biaya untuk mempercepat pengembangan AI. Sayangnya, hingga saat ini satu-satunya solusi yang diterapkan untuk GPU kelas atas MIG/Slicing (A100+) dan memerlukan Kubernetes,
? Selamat Datang di GPU Fraksional Berbasis Kontainer Untuk Semua Kartu Nvidia! ?
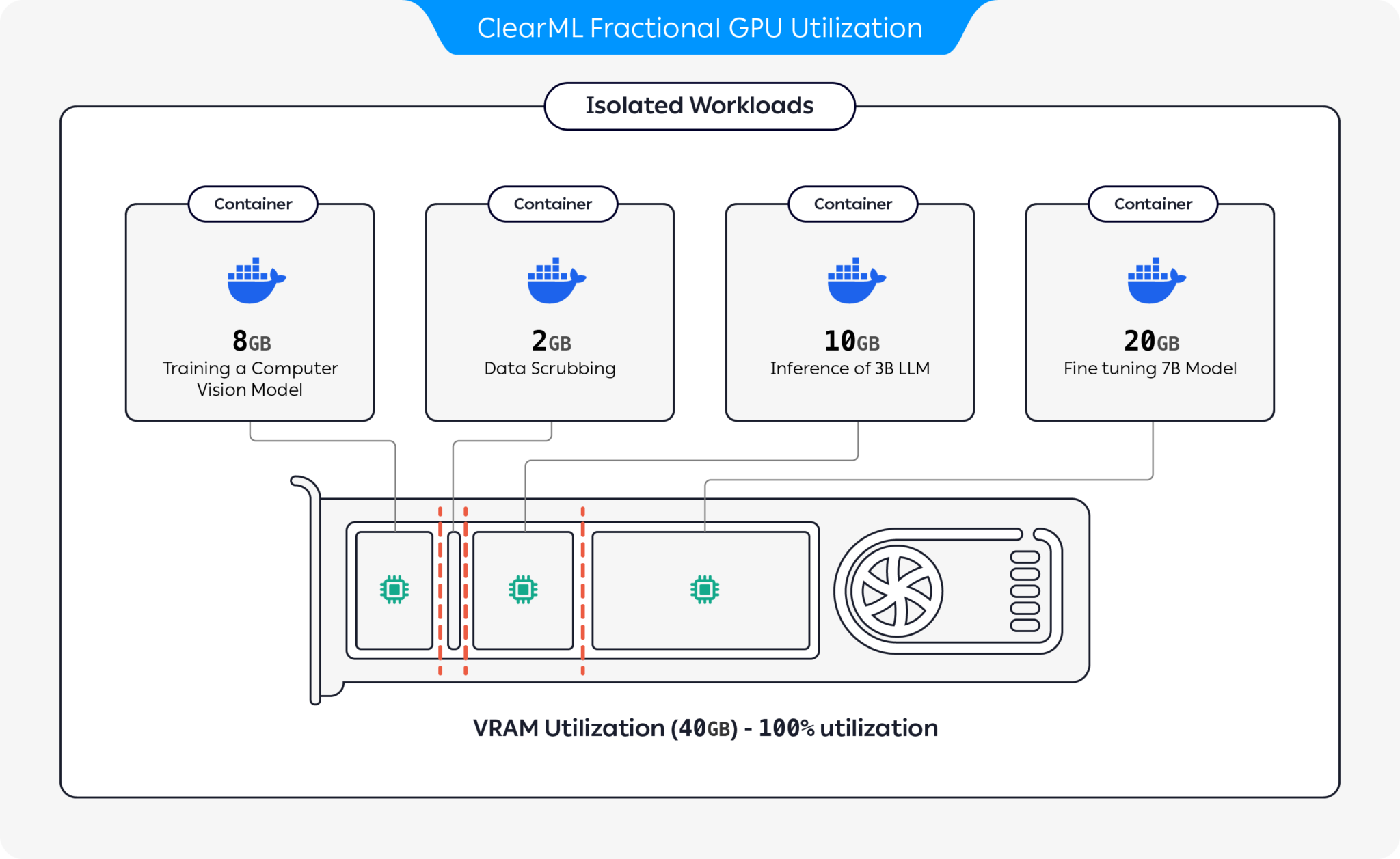
Kami menghadirkan kontainer pra-paket yang mendukung CUDA 11.x & CUDA 12.x dengan batasan memori keras bawaan! Ini berarti beberapa container dapat diluncurkan pada GPU yang sama, memastikan satu pengguna tidak dapat mengalokasikan seluruh memori GPU host! (Tidak ada lagi proses serakah yang mengambil seluruh memori GPU! Akhirnya kami memiliki opsi memori yang membatasi tingkat driver).
ClearML menawarkan beberapa opsi untuk mengoptimalkan pemanfaatan sumber daya GPU dengan mempartisi GPU:
Dengan opsi ini, ClearML memungkinkan menjalankan beban kerja AI dengan pemanfaatan perangkat keras dan kinerja beban kerja yang dioptimalkan. Repositori ini mencakup GPU pecahan berbasis kontainer. Untuk informasi selengkapnya tentang penawaran GPU fraksional ClearML, lihat dokumentasi ClearML.
Pilih wadah yang sesuai untuk Anda dan luncurkan:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashUntuk memverifikasi batas memori GPU pecahan berfungsi dengan benar, jalankan di dalam container:
nvidia-smiBerikut ini contoh output dari GPU A100:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| Batas Memori | CUDA Ver | Ubuntu Ver | Gambar Docker |
|---|---|---|---|
| 12 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
Penting
Anda harus menjalankan wadah dengan --pid=host !
Catatan
--pid=host diperlukan agar driver dapat membedakan antara proses container dan proses host lainnya saat membatasi penggunaan memori/pemanfaatan
Tip
Pengguna ClearML-Agent menambahkan [--pid=host] ke bagian agent.extra_docker_arguments Anda di file konfigurasi Anda
Bangun wadah Anda sendiri dan warisi dari wadah aslinya.
Anda dapat menemukan beberapa contoh di sini.
Kontainer GPU pecahan dapat digunakan pada eksekusi bare-metal serta POD Kubernetes. Ya! Dengan menggunakan salah satu container Fractional GPU, Anda dapat membatasi konsumsi memori Job/Pod Anda dan berbagi GPU dengan mudah tanpa takut memorinya akan crash satu sama lain!
Berikut ini template POD Kubernetes sederhana:
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] Penting
Anda harus menjalankan pod dengan hostPID: true !
Catatan
hostPID: true diperlukan untuk memungkinkan driver membedakan antara proses pod dan proses host lainnya ketika membatasi penggunaan memori/pemanfaatan
Kontainer mendukung driver Nvidia <= 545.xx . Kami akan terus memperbarui & mendukung driver baru seiring dengan dirilisnya driver tersebut
GPU yang didukung : RTX seri 10, 20, 30, 40, seri A, dan Pusat Data P100, A100, A10/A40, L40/s, H100
Keterbatasan : Mesin Windows Host saat ini tidak didukung. Jika ini penting bagi Anda, tinggalkan permintaan di bagian Masalah
T : Apakah menjalankan nvidia-smi di dalam container akan melaporkan konsumsi GPU proses lokal?
A : Ya, nvidia-smi berkomunikasi langsung dengan driver tingkat rendah dan melaporkan memori GPU container yang akurat serta batasan memori lokal container.
Perhatikan pemanfaatan GPU akan menjadi pemanfaatan GPU global (yaitu sisi host) dan bukan pemanfaatan GPU container lokal tertentu.
T : Bagaimana cara memastikan Python/Pytorch/Tensorflow saya benar-benar memiliki memori terbatas?
A : Untuk PyTorch Anda dapat menjalankan:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )Contoh mati rasa:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) Q : Apakah batasan tersebut dapat dilanggar oleh pengguna?
J : Kami yakin pengguna jahat akan menemukan jalannya. Kami tidak pernah bermaksud untuk melindungi dari pengguna jahat.
Jika Anda memiliki pengguna jahat yang memiliki akses ke mesin Anda, GPU pecahan bukanlah masalah nomor 1 Anda?
T : Bagaimana cara mendeteksi batasan memori secara terprogram?
A : Anda dapat memeriksa variabel lingkungan OS GPU_MEM_LIMIT_GB .
Perhatikan bahwa mengubahnya tidak akan menghapus atau mengurangi batasan.
T : Apakah menjalankan container dengan --pid=host aman/aman?
J : Itu harus aman dan terjamin. Peringatan utama dari perspektif keamanan adalah bahwa proses container dapat melihat baris perintah apa pun yang berjalan di sistem host. Jika baris perintah proses berisi "rahasia" maka ya, ini mungkin berpotensi menimbulkan kebocoran data. Perhatikan bahwa meneruskan "rahasia" di baris perintah adalah tindakan yang salah, dan karenanya kami tidak menganggapnya sebagai risiko keamanan. Meskipun demikian, jika keamanan adalah kuncinya, edisi perusahaan (lihat di bawah) menghilangkan kebutuhan untuk dijalankan dengan pid-host sehingga sepenuhnya aman.
T : Bisakah Anda menjalankan container tanpa --pid=host ?
J : Anda bisa! Namun Anda harus menggunakan container clearml-fractional-gpu versi perusahaan (jika tidak, batas memori akan diterapkan di seluruh sistem, bukan di seluruh container). Jika fitur ini penting bagi Anda, silakan hubungi bagian penjualan & dukungan ClearML.
Lisensi untuk menggunakan ClearML diberikan untuk tujuan penelitian atau pengembangan saja. ClearML dapat digunakan untuk tujuan pendidikan, pribadi, atau komersial internal.
Lisensi Komersial yang diperluas untuk digunakan dalam produk atau layanan tersedia sebagai bagian dari solusi Skala ClearML atau Perusahaan.
ClearML menawarkan lisensi perusahaan dan komersial yang menambahkan banyak fitur tambahan selain GPU fraksional, ini termasuk orkestrasi, antrean prioritas, manajemen kuota, dasbor cluster komputasi, manajemen kumpulan data & manajemen eksperimen, serta keamanan dan dukungan tingkat perusahaan. Pelajari lebih lanjut tentang ClearML Orchestration atau hubungi kami langsung di bagian penjualan ClearML.
Beritahu semua orang tentang hal itu! #HapusMLFractionalGPU
Bergabunglah dengan Saluran Slack kami
Beri tahu kami jika ada yang tidak berfungsi, dan bantu kami melakukan debug di Halaman Masalah
Produk ini dipersembahkan oleh tim ClearML dengan ❤️


