amazon bedrock rag
1.0.0
Retrieval-Augmented Generation (RAG) adalah proses mengoptimalkan keluaran model bahasa besar, sehingga merujuk pada basis pengetahuan resmi di luar sumber data pelatihannya sebelum menghasilkan respons. Model Bahasa Besar (LLM) dilatih pada data dalam jumlah besar dan menggunakan miliaran parameter untuk menghasilkan keluaran asli untuk tugas-tugas seperti menjawab pertanyaan, menerjemahkan bahasa, dan menyelesaikan kalimat. RAG memperluas kemampuan LLM yang sudah kuat ke domain tertentu atau basis pengetahuan internal organisasi, semuanya tanpa perlu melatih ulang modelnya. Ini adalah pendekatan hemat biaya untuk meningkatkan keluaran LLM sehingga tetap relevan, akurat, dan berguna dalam berbagai konteks. Pelajari lebih lanjut tentang RAG di sini.
Amazon Bedrock adalah layanan terkelola sepenuhnya yang menawarkan pilihan model fondasi (FM) berperforma tinggi dari perusahaan AI terkemuka seperti AI21 Labs, Anthropic, Cohere, Meta, Stability AI, dan Amazon melalui satu API, bersama dengan serangkaian luas kemampuan yang Anda perlukan untuk membangun aplikasi AI generatif dengan keamanan, privasi, dan AI yang bertanggung jawab. Dengan menggunakan Amazon Bedrock, Anda dapat dengan mudah bereksperimen dan mengevaluasi FM teratas untuk kasus penggunaan Anda, menyesuaikannya secara pribadi dengan data Anda menggunakan teknik seperti fine-tuning dan RAG, serta membangun agen yang menjalankan tugas menggunakan sistem perusahaan dan sumber data Anda. Karena Amazon Bedrock tidak memiliki server, Anda tidak perlu mengelola infrastruktur apa pun, dan Anda dapat dengan aman mengintegrasikan dan menerapkan kemampuan AI generatif ke dalam aplikasi Anda menggunakan layanan AWS yang sudah Anda kenal.
Basis Pengetahuan untuk Amazon Bedrock adalah kemampuan terkelola sepenuhnya yang membantu Anda mengimplementasikan seluruh alur kerja RAG mulai dari penyerapan hingga pengambilan dan augmentasi cepat tanpa harus membangun integrasi khusus ke sumber data dan mengelola aliran data. Manajemen konteks sesi sudah ada di dalamnya, sehingga aplikasi Anda dapat dengan mudah mendukung percakapan multi-turn.
Sebagai bagian dari pembuatan basis pengetahuan, Anda mengonfigurasi sumber data dan penyimpanan vektor pilihan Anda. Konektor sumber data memungkinkan Anda menyambungkan data milik Anda ke basis pengetahuan. Setelah mengonfigurasi konektor sumber data, Anda dapat menyinkronkan atau selalu memperbarui data dengan basis pengetahuan Anda dan membuat data Anda tersedia untuk kueri. Amazon Bedrock pertama-tama membagi dokumen atau konten Anda menjadi beberapa bagian yang dapat dikelola untuk pengambilan data yang efisien. Potongan tersebut kemudian diubah menjadi embeddings dan ditulis ke indeks vektor (representasi vektor dari data), sambil mempertahankan pemetaan ke dokumen asli. Penyematan vektor memungkinkan teks dibandingkan secara matematis untuk kesamaan.
Proyek ini dilaksanakan dengan dua sumber data; sumber data untuk dokumen yang disimpan di Amazon S3 dan sumber data lain untuk konten yang dipublikasikan di situs web. Koleksi pencarian vektor dibuat di Amazon OpenSearch Tanpa Server untuk penyimpanan vektor.
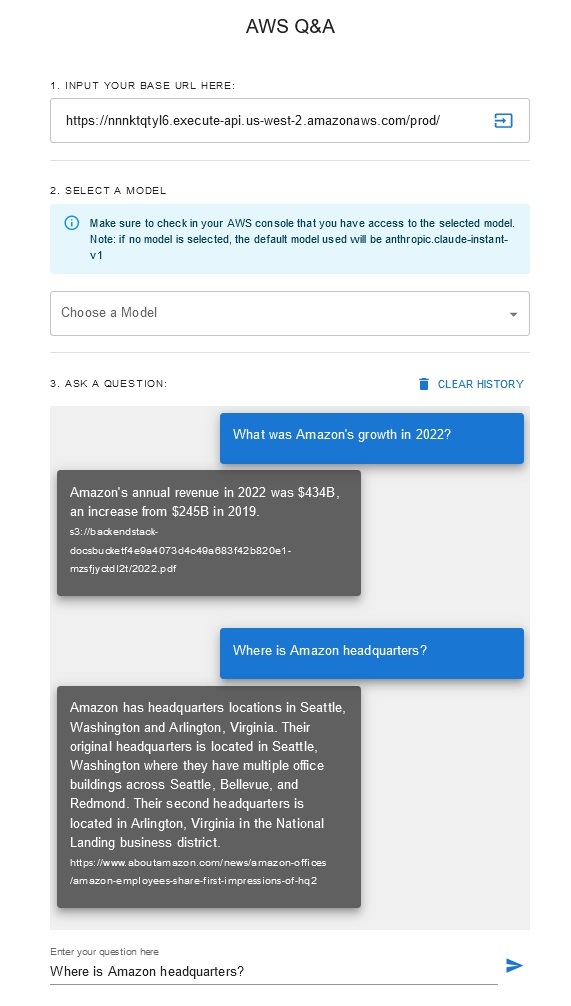
Tanya Jawab Chatbot 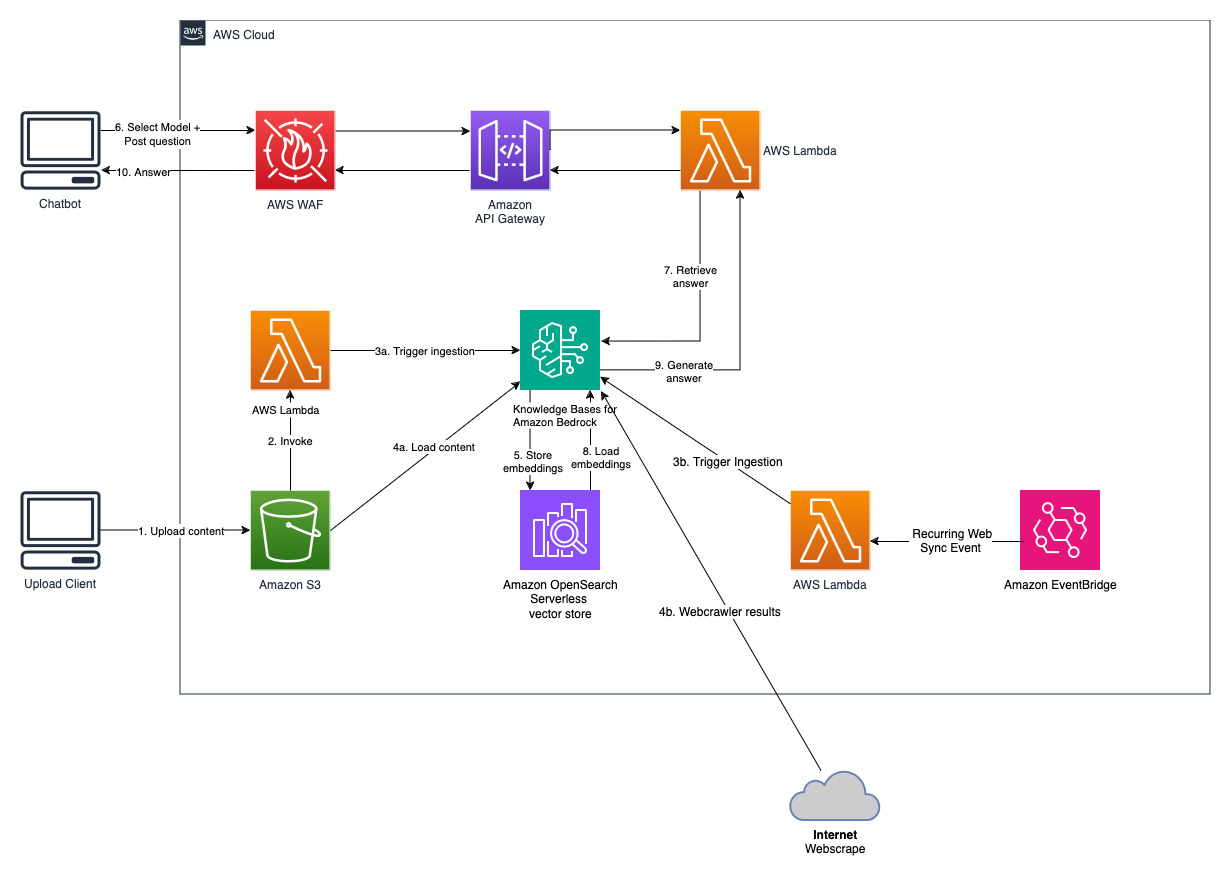
Tambahkan situs web baru untuk sumber data web 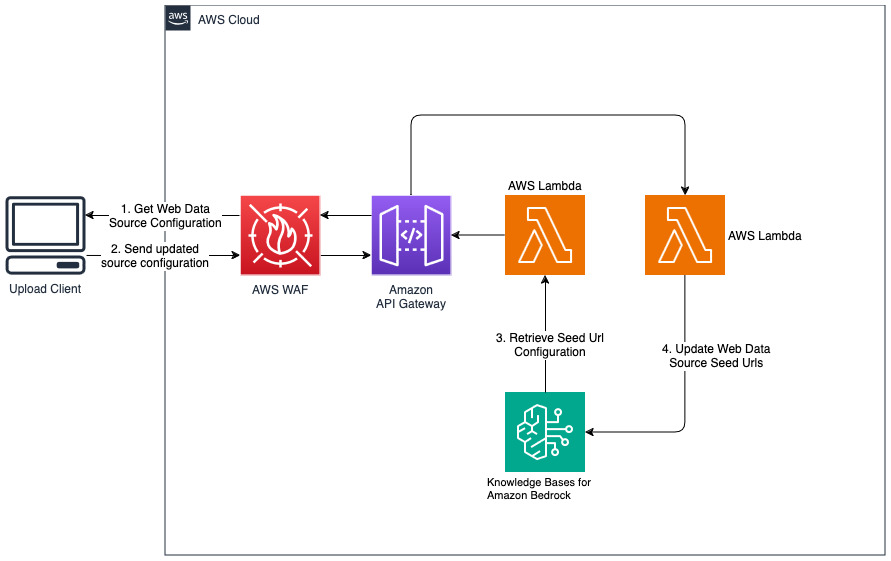
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
Berikan alamat IP klien yang diizinkan untuk mengakses API Gateway dalam format CIDR sebagai bagian dari variabel konteks 'allowedip'.
Saat penerapan selesai,
Solusi ini memungkinkan pengguna untuk memilih model dasar mana yang ingin mereka gunakan selama fase pengambilan dan pembuatan. Model defaultnya adalah Anthropic Claude Instan . Untuk model penyematan basis pengetahuan, solusi ini menggunakan Amazon Titan Embeddings G1 - Model teks . Pastikan Anda memiliki akses ke model fondasi ini.
Dapatkan laporan tahunan Amazon terbaru yang tersedia untuk umum dan salin ke nama bucket S3 yang disebutkan sebelumnya. Untuk pengujian cepat, Anda dapat menyalin laporan tahunan Amazon tahun 2022 menggunakan Konsol AWS S3. Konten dari bucket S3 akan secara otomatis disinkronkan dengan basis pengetahuan karena penerapan solusi mengawasi konten baru di bucket S3 dan memicu alur kerja penyerapan.
Solusi yang diterapkan menginisialisasi sumber data web yang disebut "WebCrawlerDataSource" dengan url https://www.aboutamazon.com/news/amazon-offices . Anda perlu menyinkronkan sumber data Web Crawler ini dengan basis pengetahuan dari konsol AWS secara manual untuk mencari konten situs web karena penyerapan situs web dijadwalkan akan terjadi di masa mendatang. Pilih sumber data ini dari Konsol Pengetahuan berdasarkan Amazon Bedrock dan mulai operasi "Sinkronisasi". Lihat Menyinkronkan sumber data Anda dengan basis pengetahuan Amazon Bedrock Anda untuk detailnya. Perhatikan bahwa konten situs web akan tersedia untuk chatbot Tanya Jawab hanya setelah sinkronisasi selesai. Harap gunakan panduan ini saat menyiapkan situs web sebagai sumber data.
Gunakan "cdk destroy" untuk menghapus tumpukan sumber daya cloud yang dibuat dalam penerapan solusi ini.


