EasyNLU
1.0.0
EasyNLU adalah perpustakaan Natural Language Understanding (NLU) yang ditulis dalam Java untuk aplikasi seluler. Berbasis tata bahasa, ini cocok untuk domain yang sempit namun memerlukan kontrol yang ketat.
Proyek ini memiliki contoh aplikasi Android yang dapat menjadwalkan pengingat dari masukan bahasa alami:
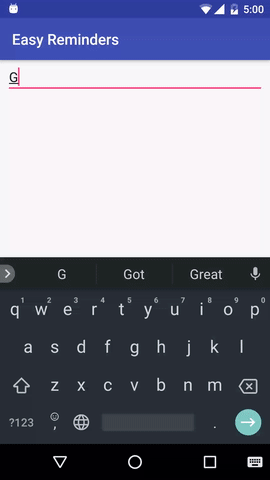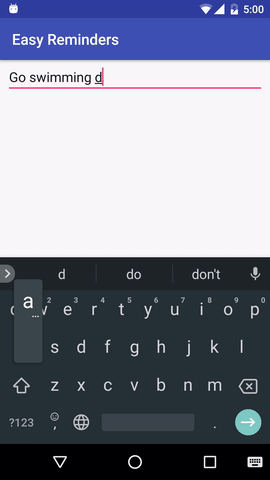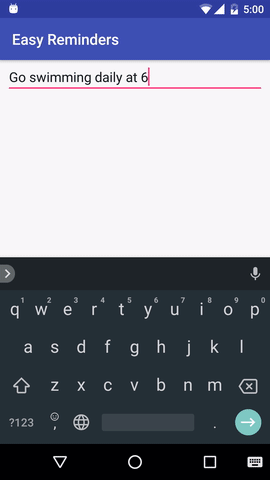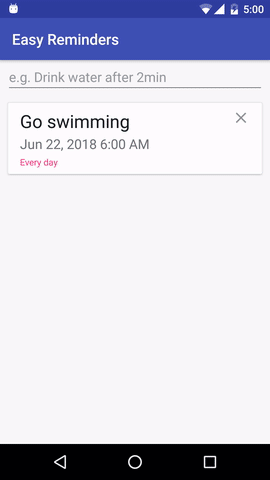
EasyNLU dilisensikan di bawah Apache 2.0.
Pada intinya EasyNLU adalah parser semantik berbasis CCG. Pengenalan yang baik tentang penguraian semantik dapat ditemukan di sini. Pengurai semantik dapat mengurai masukan seperti:
Pergi ke dokter gigi jam 5 sore besok
menjadi bentuk terstruktur:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU menyediakan formulir terstruktur sebagai peta Java rekursif. Bentuk terstruktur ini kemudian dapat diselesaikan menjadi objek tugas spesifik yang 'dieksekusi'. Misalnya, dalam proyek sampel, formulir terstruktur diselesaikan menjadi objek Reminder yang memiliki bidang seperti task , startTime dan repeat dan digunakan untuk mengatur alarm dengan layanan AlarmManager.
Secara umum, berikut adalah langkah-langkah tingkat tinggi untuk menyiapkan kemampuan NLU:
Sebelum menulis aturan apa pun, kita harus menentukan ruang lingkup tugas dan parameter formulir terstruktur. Sebagai contoh mainan, katakanlah tugas kita adalah menghidupkan dan mematikan fitur ponsel seperti Bluetooh, Wifi, dan GPS. Jadi bidangnya adalah:
Contoh formulir terstruktur adalah:
{feature: "bluetooth", action: "enable" }
Ada baiknya juga jika Anda memiliki beberapa contoh masukan untuk memahami variasinya:
Melanjutkan contoh mainan, kita dapat mengatakan bahwa di tingkat atas kita memiliki tindakan setting yang harus memiliki fitur dan tindakan. Kami kemudian menggunakan aturan untuk menangkap informasi ini:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" ); Suatu aturan minimal memuat LHS dan RHS. Berdasarkan konvensi, kita menambahkan '$' pada sebuah kata untuk menunjukkan suatu kategori. Kategori mewakili kumpulan kata atau kategori lainnya. Dalam aturan di atas $Feature mewakili kata-kata seperti bluetooth, bt, wifi dll yang kami tangkap menggunakan aturan 'leksikal':
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
); Untuk menormalkan variasi nama fitur, kami menyusun $Features menjadi sub-fitur:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); Kemiripan untuk $Action :
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
); Perhatikan '?' dalam aturan ketiga; ini berarti kategori $Switch bersifat opsional. Untuk menentukan apakah suatu parse berhasil, parser mencari kategori khusus yang disebut kategori root. Berdasarkan konvensi, ini dilambangkan sebagai $ROOT . Kita perlu menambahkan aturan untuk mencapai kategori ini:
Rule root = new Rule ( "$ROOT" , "$Setting" );Dengan seperangkat aturan ini, parser kita seharusnya mampu mengurai contoh-contoh di atas, mengubahnya menjadi apa yang disebut pohon sintaksis.
Parsing tidak ada gunanya jika kita tidak bisa mengekstrak makna kalimatnya. Makna ini ditangkap oleh bentuk terstruktur (Bentuk logis dalam jargon NLP). Di EasyNLU kami meneruskan parameter ketiga dalam definisi aturan untuk menentukan bagaimana semantik akan diekstraksi. Kami menggunakan sintaks JSON dengan penanda khusus untuk melakukan ini:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first memberitahu parser untuk memilih nilai kategori pertama aturan RHS. Dalam hal ini akan menjadi 'aktifkan' atau 'nonaktifkan' berdasarkan kalimat. Penanda lainnya termasuk:
@identity : Fungsi identitas@last : Pilih nilai kategori RHS terakhir@N : Pilih nilai kategori N th RHS, misal @3 akan pilih yang ke-3@merge : Gabungkan nilai semua kategori. Hanya nilai bernama (misalnya {action: enable} ) yang akan digabungkan@append : Tambahkan nilai semua kategori ke dalam daftar. Daftar yang dihasilkan harus diberi nama. Hanya nilai bernama yang diperbolehkanSetelah menambahkan penanda semantik, aturan kami menjadi:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);Jika parameter semantik tidak disediakan, parser akan membuat nilai default yang sama dengan RHS.
Untuk menjalankan parser, klon repositori ini dan impor modul parser ke proyek Android Studio/IntelliJ Anda. Pengurai EasyNLU mengambil objek Grammar yang menyimpan aturan, objek Tokenizer untuk mengubah kalimat masukan menjadi kata-kata, dan daftar opsional objek Annotator untuk memberi anotasi pada entitas seperti angka, tanggal, tempat, dll. Jalankan kode berikut setelah menentukan aturan:
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));Anda harus mendapatkan hasil berikut:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
Cobalah variasi lainnya. Jika penguraian gagal untuk varian sampel, Anda tidak akan mendapatkan keluaran. Anda kemudian dapat menambahkan atau mengubah aturan dan mengulangi proses rekayasa tata bahasa.
EasyNLU sekarang mendukung daftar dalam bentuk terstruktur. Untuk domain di atas dapat menangani input seperti
Nonaktifkan lokasi tetapi gps
Tambahkan 3 aturan tambahan ini ke tata bahasa di atas:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
Jalankan kueri baru seperti:
System.out.println(parser.parse("disable location bt gps"));
Anda harus mendapatkan hasil ini:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
Perhatikan bahwa aturan ini dipicu hanya jika ada lebih dari satu fitur dalam kueri
Anotator mempermudah jenis token tertentu yang mungkin rumit atau tidak mungkin ditangani melalui aturan. Misalnya ambil kelas NumberAnnotator . Ini akan mendeteksi dan memberi anotasi pada semua nomor sebagai $NUMBER . Anda kemudian dapat langsung mereferensikan kategori tersebut dalam aturan Anda, misalnya:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
EasyNLU saat ini hadir dengan beberapa anotator:
NumberAnnotator : Memberi anotasi pada angkaDateTimeAnnotator : Memberi anotasi pada beberapa format tanggal. Juga menyediakan aturannya sendiri yang Anda tambahkan menggunakan DateTimeAnnotator.rules()TokenAnnotator : Memberi anotasi pada setiap token input sebagai $TOKENPhraseAnnotator : Memberi anotasi pada setiap frasa masukan yang berdekatan sebagai $PHRASE Untuk menggunakan anotator khusus Anda sendiri, implementasikan antarmuka Annotator dan teruskan ke parser. Rujuk anotator bawaan untuk mendapatkan ide cara menerapkannya.
EasyNLU mendukung aturan pemuatan dari file teks. Setiap aturan harus berada dalam baris terpisah. Kiri, Kanan, dan semantik harus dipisahkan berdasarkan tab:
$EnableDisable ?$Switch $OnOff @last
Berhati-hatilah untuk tidak menggunakan IDE yang secara otomatis mengubah tab menjadi spasi
Semakin banyak aturan yang ditambahkan ke parser, Anda akan menemukan bahwa parser menemukan beberapa parsing untuk input tertentu. Hal ini disebabkan oleh ambiguitas umum bahasa manusia. Untuk menentukan seberapa akurat parser untuk tugas Anda, Anda perlu menjalankannya melalui contoh yang diberi label.
Seperti aturan sebelumnya, EasyNLU mengambil contoh yang ditentukan dalam teks biasa. Setiap baris harus berupa contoh terpisah dan harus berisi teks mentah dan formulir terstruktur yang dipisahkan oleh tab:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
Penting bagi Anda untuk mencakup jumlah atau variasi masukan yang dapat diterima. Anda akan mendapatkan lebih banyak variasi jika meminta orang yang berbeda untuk melakukan tugas ini. Jumlah contoh bergantung pada kompleksitas domain. Contoh kumpulan data yang disediakan dalam proyek ini memiliki 100+ contoh.
Setelah Anda memiliki data, Anda dapat memasukkannya ke dalam kumpulan data. Bagian pembelajaran ditangani oleh modul trainer ; impor ke proyek Anda. Muat kumpulan data seperti ini:
Dataset dataset = Dataset . fromText ( 'filename.txt' )Kami mengevaluasi parser untuk menentukan dua jenis akurasi
Untuk menjalankan evaluasi kami menggunakan kelas Model :
Model model = new Model(parser);
model.evaluate(dataset, 2);
Parameter kedua pada fungsi evaluasi adalah tingkat verbose. Semakin tinggi angkanya, semakin banyak keluarannya. Fungsi evaluate() dengan menjalankan parser melalui setiap contoh dan menampilkan parsing yang salah yang akhirnya menampilkan keakuratan. Jika Anda mendapatkan kedua akurasi di tahun 90an maka pelatihan tidak diperlukan, Anda mungkin dapat menangani beberapa parsing buruk tersebut dengan pemrosesan pasca. Jika akurasi oracle tinggi tetapi akurasi prediksi rendah maka pelatihan sistem akan membantu. Jika akurasi Oracle rendah maka Anda perlu melakukan lebih banyak rekayasa tata bahasa.
Untuk mendapatkan penguraian yang benar, kami memberi skor dan memilih yang memiliki skor tertinggi. EasyNLU menggunakan model linier sederhana untuk menghitung skor. Pelatihan dilakukan menggunakan Stochastic Gradient Descent (SGD) dengan fungsi engsel loss. Fitur masukan didasarkan pada jumlah aturan dan bidang dalam bentuk terstruktur. Anak timbangan yang dilatih kemudian disimpan ke dalam file teks.
Anda dapat menyesuaikan beberapa model/parameter pelatihan untuk mendapatkan akurasi yang lebih baik. Untuk model pengingat, parameter berikut digunakan:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );Jalankan kode pelatihan sebagai berikut:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );Ini akan melatih model selama 100 epoch dengan pembagian uji kereta sebesar 0,8. Ini akan menampilkan akurasi pada set pengujian dan menyimpan bobot model ke jalur file yang disediakan. Untuk melatih seluruh himpunan data, atur parameter penerapan ke true. Anda dapat menjalankan mode interaktif, mengambil masukan dari konsol:
experiement.interactive();
CATATAN: pelatihan tersebut tidak dijamin menghasilkan akurasi yang tinggi meskipun dengan jumlah contoh yang banyak. Untuk skenario tertentu, fitur yang disediakan mungkin tidak cukup diskriminatif. Jika Anda terjebak dalam kasus seperti itu, harap catat masalahnya dan kami dapat menemukan fitur tambahan.
Bobot model adalah file teks biasa. Untuk proyek Android Anda dapat menempatkannya di folder assets dan memuatnya menggunakan AssetManager. Silakan merujuk ReminderNlu.java untuk lebih jelasnya. Anda bahkan dapat menyimpan bobot dan aturan di cloud dan memperbarui model Anda melalui udara (Firebase, siapa?).
Setelah parser melakukan pekerjaan dengan baik dalam mengubah input bahasa alami menjadi bentuk terstruktur, Anda mungkin menginginkan data tersebut dalam objek tugas tertentu. Untuk beberapa domain seperti contoh mainan di atas, ini bisa jadi cukup mudah. Bagi yang lain, Anda mungkin harus menyelesaikan referensi ke hal-hal seperti tanggal, tempat, kontak, dll. Dalam sampel pengingat, tanggal sering kali bersifat relatif (misalnya 'besok', 'setelah 2 jam', dll) yang perlu diubah menjadi nilai absolut. Silakan lihat ArgumentResolver.java untuk melihat bagaimana resolusi dilakukan.
TIPS: Minimalkan logika resolusi saat menentukan aturan dan lakukan sebagian besar logika resolusi pada pasca pemrosesan. Ini akan membuat peraturan menjadi lebih sederhana.


