DeepMorphy
1.0.0
DeepMorphy adalah penganalisis morfologi berbasis jaringan saraf untuk bahasa Rusia.
DeepMorphy adalah penganalisis morfologi untuk bahasa Rusia. Tersedia sebagai perpustakaan .Net Standard 2.0. Bisa:
Terminologi di DeepMorphy sebagian dipinjam dari penganalisis morfologi pymorphy2.
Grammeme (English grammeme) - arti dari salah satu kategori tata bahasa suatu kata (misalnya, past tense, singular, maskulin).
Kategori tata bahasa adalah sekumpulan tata bahasa yang saling eksklusif yang mencirikan beberapa ciri umum (misalnya, jenis kelamin, tense, kasus, dll.). Daftar semua kategori dan tata bahasa yang didukung di DeepMorphy ada di sini.
Tag (tag bahasa Inggris) - sekumpulan tata bahasa yang mencirikan kata tertentu (misalnya, tag untuk kata landak - kata benda, tunggal, kasus nominatif, maskulin).
Lemma (Bahasa Inggris lemma) adalah bentuk normal sebuah kata.
Lemmatisasi (eng. lemmatisasi) - membawa sebuah kata ke bentuk normalnya.
Leksem adalah himpunan segala bentuk satu kata.
Elemen inti DeepMorphy adalah jaringan saraf. Untuk sebagian besar kata, analisis morfologi dan lemmatisasi dilakukan oleh jaringan. Beberapa jenis kata diproses oleh praprosesor.
Ada 3 praprosesor:
Jaringan dibangun dan dilatih pada kerangka tensorflow. Kamus Opencorpora berfungsi sebagai kumpulan data. Terintegrasi ke .Net melalui TensorFlowSharp.
Grafik komputasi untuk penguraian kata di DeepMorphy terdiri dari 11 “subnet”:
Masalah perubahan bentuk kata diselesaikan dengan jaringan 1 seq2seq.
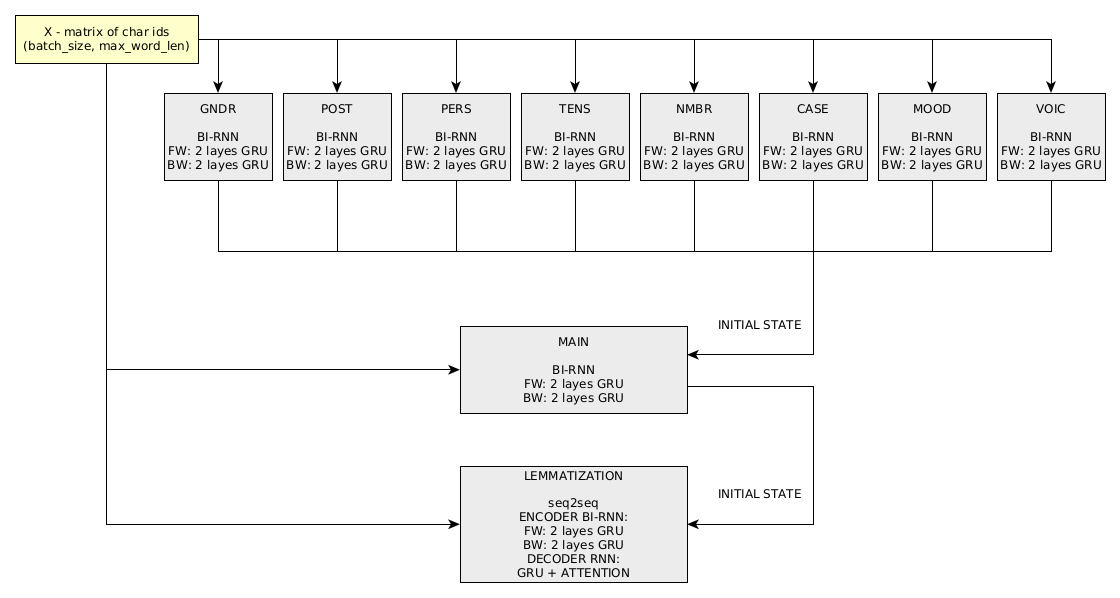
Pelatihan dilakukan secara berurutan, jaringan dilatih terlebih dahulu berdasarkan kategori (urutan tidak menjadi masalah). Selanjutnya, klasifikasi utama berdasarkan tag, lemmatisasi dan jaringan untuk mengubah bentuk kata dilatih. Pelatihan dilakukan pada 3 GPU Titan X. Metrik kinerja jaringan pada dataset pengujian untuk rilis terbaru dapat dilihat di sini.
DeepMorphy untuk .NET adalah perpustakaan .Net Standard 2.0. Satu-satunya dependensi adalah perpustakaan TensorflowSharp (jaringan saraf diluncurkan melaluinya).
Perpustakaan diterbitkan dalam Nuget, jadi paling mudah untuk menginstalnya.
Jika ada pengelola paket:
Install-Package DeepMorphy
Jika proyek mendukung PackageReference:
<PackageReference Include="DeepMorphy"/>
Jika seseorang ingin membangun dari sumber, maka sumber C# ada di sini. Rider digunakan untuk pengembangan (semuanya harus dirakit di studio tanpa masalah).
Semua tindakan dilakukan melalui objek kelas MorphAnalyzer:
var morph = new MorphAnalyzer ( ) ;Idealnya, lebih baik menggunakannya sebagai singleton; saat membuat objek, beberapa waktu dihabiskan untuk memuat kamus dan jaringan. Benang aman. Saat membuat, Anda dapat meneruskan parameter berikut ke konstruktor:
Untuk parsing, metode Parse digunakan (dibutuhkan IEnumerable dengan kata-kata untuk analisis sebagai input, mengembalikan IEnumerable dengan hasil analisis).
var results = morph . Parse ( new string [ ]
{
"королёвские" ,
"тысячу" ,
"миллионных" ,
"красотка" ,
"1-ый"
} ) . ToArray ( ) ;
var morphInfo = results [ 0 ] ;Daftar kategori tata bahasa yang didukung, tata bahasa dan kuncinya ada di sini. Jika Anda perlu mengetahui kombinasi tata bahasa (tag) yang paling mungkin, maka Anda perlu menggunakan properti BestTag dari objek MorphInfo.
// выводим лучшую комбинацию граммем для слова
Console . WriteLine ( morphInfo . BestTag ) ;Berdasarkan kata itu sendiri, tidak selalu mungkin untuk secara jelas menentukan arti kategori tata bahasanya (lihat homonim), jadi DeepMorphy memungkinkan Anda melihat tag teratas untuk kata tertentu (properti Tag).
// выводим все теги для слова + их вероятность
foreach ( var tag in morphInfo . Tags )
Console . WriteLine ( $ " { tag } : { tag . Power } " ) ;Apakah ada kombinasi tata bahasa di salah satu tag:
// есть ли в каком-нибудь из тегов прилагательные единственного числа
morphInfo . HasCombination ( "прил" , "ед" ) ;Apakah ada kombinasi tata bahasa pada tag yang paling mungkin:
// ясляется ли лучший тег прилагательным единственного числа
morphInfo . BestTag . Has ( "прил" , "ед" ) ;Mengambil kategori tata bahasa tertentu dari tag terbaik:
// выводит часть речи лучшего тега и число
Console . WriteLine ( morphInfo . BestTag [ "чр" ] ) ;
Console . WriteLine ( morphInfo . BestTag [ "число" ] ) ;Tag digunakan ketika Anda memerlukan informasi tentang beberapa kategori tata bahasa sekaligus (misalnya part of Speech dan Number). Jika Anda hanya tertarik pada satu kategori, Anda dapat menggunakan antarmuka probabilitas kategori tata bahasa objek MorphInfo.
// выводит самую вероятную часть речи
Console . WriteLine ( morphInfo [ "чр" ] . BestGramKey ) ;Anda juga bisa mendapatkan distribusi probabilitas berdasarkan kategori tata bahasa:
// выводит распределение вероятностей для падежа
foreach ( var gram in morphInfo [ "падеж" ] . Grams )
{
Console . WriteLine ( $ " { gram . Key } : { gram . Power } " ) ;
}Jika bersama dengan analisis morfologi perlu diperoleh lemma kata, maka penganalisisnya harus dibuat sebagai berikut:
var morph = new MorphAnalyzer ( withLemmatization : true ) ;Lemma dapat diperoleh dari tag kata:
Console . WriteLine ( morphInfo . BestTag . Lemma ) ;Memeriksa apakah suatu kata memiliki lemma:
morphInfo . HasLemma ( "королевский" ) ;Metode CanBeSameLexeme dapat digunakan untuk menemukan kata-kata dalam satu leksem:
// выводим все слова, которые могут быть формой слова королевский
var words = new string [ ]
{
"королевский" ,
"королевские" ,
"корабли" ,
"пересказывают" ,
"королевского"
} ;
var results = morph . Parse ( words ) . ToArray ( ) ;
var mainWord = results [ 0 ] ;
foreach ( var morphInfo in results )
{
if ( mainWord . CanBeSameLexeme ( morphInfo ) )
Console . WriteLine ( morphInfo . Text ) ;
}Jika Anda hanya membutuhkan lemmatisasi tanpa penguraian morfologi, maka Anda perlu menggunakan metode Lemmatize:
var tasks = new [ ]
{
new LemTask ( "синяя" , morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ) ,
new LemTask ( "гуляя" , morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var lemmas = morph . Lemmatize ( tasks ) . ToArray ( ) ;
foreach ( var lemma in lemmas )
Console . WriteLine ( lemma ) ;DeepMorphy dapat mengubah bentuk kata dalam leksem; daftar infleksi yang didukung ada di sini. Kata-kata kamus hanya dapat diubah dalam bentuk yang tersedia di kamus. Untuk mengubah bentuk kata digunakan metode Inflect; sebagai masukannya diperlukan enumerasi objek InflectTask (berisi kata sumber, tag kata sumber, dan tag di mana kata tersebut harus ditempatkan). Outputnya adalah pencacahan dengan formulir yang diperlukan (jika formulir tidak dapat diproses, maka null).
var tasks = new [ ]
{
new InflectTask ( "синяя" ,
morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ,
morph . TagHelper . CreateTag ( "прил" , gndr : "муж" , nmbr : "ед" , @case : "им" ) ) ,
new InflectTask ( "гулять" ,
morph . TagHelper . CreateTag ( "инф_гл" ) ,
morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var results = morph . Inflect ( tasks ) ;
foreach ( var result in results )
Console . WriteLine ( result ) ;Dimungkinkan juga untuk mendapatkan semua bentuknya untuk sebuah kata menggunakan metode Lexeme (untuk kata-kata kamus ia mengembalikan semuanya dari kamus, untuk kata-kata lain semua bentuk dari infleksi yang didukung).
var word = "лемматизировать" ;
var tag = m . TagHelper . CreateTag ( "инф_гл" ) ;
var results = m . Lexeme ( word , tag ) . ToArray ( ) ;Salah satu fitur dari algoritma ini adalah ketika mengubah bentuk atau menghasilkan leksem, jaringan dapat “menemukan” bentuk kata yang tidak ada (hipotetis), suatu bentuk yang tidak digunakan dalam bahasa tersebut. Misalnya, di bawah ini Anda mendapatkan kata “Saya akan lari”, meskipun saat ini kata tersebut tidak digunakan secara khusus dalam bahasa tersebut.
var tasks = new [ ]
{
new InflectTask ( "победить" ,
m . TagHelper . CreateTag ( "инф_гл" ) ,
m . TagHelper . CreateTag ( "гл" , nmbr : "ед" , tens : "буд" , pers : "1л" , mood : "изъяв" ) )
} ;
Console . WriteLine ( m . Inflect ( tasks ) . First ( ) ) ; 


