dstoolkit km solution accelerator
V1.6

Akselerator solusi Penambangan Pengetahuan
Repositori ini berisi semua kode untuk menyebarkan solusi Penambangan Pengetahuan end-to-end berdasarkan Azure Cognitive Search.
Itu dibangun di atas layanan Azure standar seperti Functions, Web App Services, Congitive Services & Cognitive Search. Ini menyediakan jalur penerapan yang memungkinkan penyiapan jalur CI/CD dengan cepat dan mudah untuk proyek Anda.
Untuk dokumentasi terperinci silakan merujuk ke bagian dokumen dari repo yang berisi wiki solusi.
Agar berhasil menyiapkan solusi, Anda harus memiliki akses ke dan atau menyediakan hal berikut:
Peran Pemilik atau Kontributor diambil pada langganan Azure atau Grup Sumber Daya yang ditargetkan.
Silakan merujuk ke README untuk menerapkan akselerator solusi ini.
Petunjuk yang diberikan dalam semua panduan mengasumsikan Anda memiliki pengetahuan dasar tentang portal Microsoft Azure, Azure Functions, Azure Cognitive Search, Functions, Storage, dan Azure Cognitives Services.
Untuk pelatihan dan dukungan tambahan, silakan lihat:
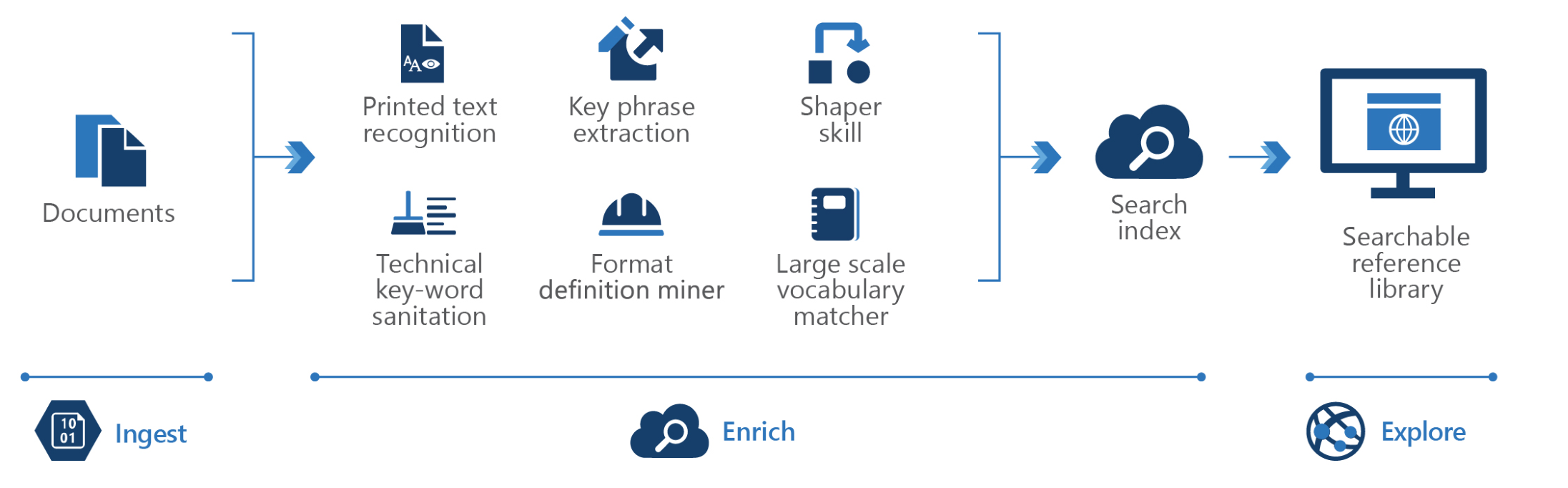
Penambangan pengetahuan (KM) adalah disiplin baru dalam kecerdasan buatan (AI) yang menggunakan kombinasi layanan cerdas untuk belajar dengan cepat dari sejumlah besar informasi. Hal ini memungkinkan organisasi untuk memahami secara mendalam dan dengan mudah mengeksplorasi informasi, mengungkap wawasan tersembunyi, dan menemukan hubungan dan pola dalam skala besar.
Penambangan Pengetahuan di Azure
Akselerator solusi KM ini bertujuan untuk memberi Anda solusi Penambangan Pengetahuan menyeluruh yang dapat diterapkan yang terdiri dari:
Dengan akselerator berbasis cloud ini Anda akan mendapatkan solusi menyeluruh dengan alat untuk menyebarkan, memperluas, mengoperasikan & memantau.
Dalam hal ini, solusinya memberikan
Akselerator solusi Knowledge Mining ini terinspirasi dari akselerator lainnya, Knowledge Mining Solution Accelerator.
Berdasarkan pengalaman lapangan, kami membangun fitur/keterampilan untuk mengatasi tantangan umum data tidak terstruktur yang berfokus pada kegunaan dan pengalaman eksplorasi data.
Di bawah ini adalah daftar singkat hal-hal penting yang perlu diperhatikan:
Indeksasi gambar yang disematkan
Normalisasi gambar :
Metadata
Konversi HTML
Ekstraksi tabel : informasi tabel biasa terjadi pada korpus data tidak terstruktur. Solusinya akan mengekstrak, mengindeks, dan memproyeksikan tabel ke penyimpanan pengetahuan khusus (opsional).
Terjemahan ": ada dua fitur terjemahan dalam solusi ini
Analisis Teks : mengekstrak Entitas (Bernama, Tertaut) dari dokumen apa pun dan teks gambar OCR.
Ekspor ke Excel : pertanyaan populer saat menjelajahi data tidak terstruktur.
UI yang Dapat Dikonfigurasi : membangun UI memakan waktu, kami ingin menghadirkan kemampuan konfigurasi UI yang hebat sehingga Anda dapat mewujudkan solusi KM baru secara tepat waktu.
Semangat akselerator solusi ini adalah skenario Content Research KM.
Namun demikian, karena arsitekturnya terbuka, Anda dapat menggunakannya sebagai landasan untuk skenario KM yang lebih terspesialisasi.
Akselerator solusi ini tidak ditargetkan ke domain apa pun meskipun ekstensibilitasnya akan memberi Anda alat untuk menjadikannya spesifik untuk domain.
Beberapa kasus penggunaan yang menginspirasi
Anda mungkin memikirkan produksi seperti akselerator untuk organisasi Anda.
Akselerator solusi ini menargetkan siapa pun yang membutuhkan
Tujuan akselerator solusi ini juga untuk memudahkan integrasi modul Ilmu Data ke dalam solusi penambangan pengetahuan Anda.
Tim Perangkat Ilmu Data telah membuat akselerator untuk beban kerja ilmu data Anda.
| Larutan | Keterangan |
|---|---|
| Keserbagunaan | Verseagility adalah perangkat berbasis Python untuk meningkatkan tugas pemrosesan bahasa alami (NLP) kustom Anda, memungkinkan Anda membawa data Anda sendiri, menggunakan kerangka kerja pilihan Anda, dan membawa model ke dalam produksi. Ini adalah komponen utama dari Microsoft Data Science Toolkit. |
| Basis MLOps | Repositori ini berisi struktur repositori dasar untuk proyek pembelajaran mesin berdasarkan teknologi Azure (Azure ML dan Azure DevOps). Nama folder dan file dipilih berdasarkan pengalaman pribadi. Anda dapat menemukan prinsip dan ide di balik struktur tersebut, yang kami sarankan untuk diikuti saat menyesuaikan proyek dan proses MLOps Anda sendiri. Selain itu, kami berharap pengguna memahami konsep pembelajaran mesin Azure dan cara menggunakan teknologi tersebut. |
| MLOps untuk DataBricks | Repositori ini berisi kerangka pengembangan Databricks untuk menyampaikan proyek Rekayasa Data apa pun, dan proyek pembelajaran mesin berdasarkan Teknologi Azure. |
| Akselerator Solusi Klasifikasi | Repositori ini berisi struktur repositori dasar untuk memberikan solusi klasifikasi untuk proyek pembelajaran mesin (ML) berdasarkan teknologi Azure (Azure ML dan Azure DevOps). |
| Akselerator Solusi Deteksi Objek | Repositori ini berisi semua kode untuk melatih model deteksi objek TensorFlow dalam Azure Machine Learning (AML) dengan penyiapan untuk pelatihan komputasi Azure, pemantauan eksperimen, dan penerapan titik akhir sebagai layanan web. Ini dibangun di atas MLOps Accelerator dan menyediakan pelatihan menyeluruh dan alur penerapan yang memungkinkan penyiapan alur CI/CD dengan cepat dan mudah untuk proyek Anda. |
Anda dapat merujuk ke dokumentasi akselerator solusi sebagai berikut:
| Topik | Keterangan | Tautan Dokumentasi |
|---|---|---|
| Prasyarat | Apa yang Anda perlukan untuk menerapkan & mengoperasikan solusinya | BACA SAYA |
| Arsitektur | Bagaimana solusinya dirancang | BACA SAYA |
| Penyebaran | Cara menyebarkan akselerator solusi ini | BACA SAYA |
| Konfigurasi | Semua yang perlu Anda ketahui tentang konfigurasi akselerator solusi | BACA SAYA |
| Ilmu Data | Integrasi dengan Ilmu Data | BACA SAYA |
| Penyebaran | Ho untuk memulai dengan menerapkan solusi | BACA SAYA |
| Pemantauan | Bagaimana memantau solusinya | BACA SAYA |
| Mencari | Bagaimana penelusuran dikonfigurasi dan dikelola | BACA SAYA |
| Telusuri & Jelajahi (UI) | Antarmuka Pengguna untuk Mencari & Menjelajahi | BACA SAYA |
Struktur penyimpanan akselerator ini adalah sebagai berikut
Kloning atau unduh repositori ini lalu navigasikan ke folder Penerapan, dengan mengikuti langkah-langkah yang dijelaskan dalam panduan penerapan.
Saat Anda menyelesaikan semua langkah, Anda akan memiliki solusi penambangan pengetahuan menyeluruh yang menggabungkan penyerapan sumber data dengan keterampilan pengayaan data dan aplikasi web yang didukung oleh Azure Cognitive Search.
Solusi ini terinspirasi dari karya asli
Kontributor inti pada akselerator solusi ini adalah
Tim sponsor perangkat ilmu data
Untuk percakapan hebat tentang Penambangan Pengetahuan dan Data Tidak Terstruktur
Proyek ini menyambut baik kontribusi dan saran. Sebagian besar kontribusi mengharuskan Anda menyetujui Perjanjian Lisensi Kontributor (CLA) yang menyatakan bahwa Anda berhak, dan memang benar, memberi kami hak untuk menggunakan kontribusi Anda. Untuk detailnya, kunjungi https://cla.opensource.microsoft.com.
Saat Anda mengirimkan permintaan tarik, bot CLA akan secara otomatis menentukan apakah Anda perlu memberikan CLA dan menghiasi PR dengan tepat (misalnya, pemeriksaan status, komentar). Cukup ikuti instruksi yang diberikan oleh bot. Anda hanya perlu melakukan ini sekali di seluruh repo menggunakan CLA kami.
Proyek ini telah mengadopsi Kode Etik Sumber Terbuka Microsoft. Untuk informasi lebih lanjut lihat FAQ Pedoman Perilaku atau hubungi [email protected] jika ada pertanyaan atau komentar tambahan.
Proyek ini mungkin berisi merek dagang atau logo untuk proyek, produk, atau layanan. Penggunaan resmi atas merek dagang atau logo Microsoft tunduk dan harus mengikuti Pedoman Merek Dagang & Merek Microsoft. Penggunaan merek dagang atau logo Microsoft dalam versi modifikasi proyek ini tidak boleh menimbulkan kebingungan atau menyiratkan sponsor Microsoft. Segala penggunaan merek dagang atau logo pihak ketiga tunduk pada kebijakan pihak ketiga tersebut.


