idt
1.0.0

Alat kumpulan data gambar (IDT) adalah aplikasi CLI yang dikembangkan untuk mempermudah dan mempercepat pembuatan kumpulan data gambar yang akan digunakan untuk pembelajaran mendalam. Alat ini mencapai hal ini dengan mengambil gambar dari beberapa mesin pencari seperti duckgo, bing, dan deviantart. IDT juga mengoptimalkan kumpulan data gambar, meskipun fitur ini opsional, pengguna dapat menurunkan skala dan mengompresi gambar untuk ukuran dan dimensi file yang optimal. Contoh kumpulan data yang dibuat menggunakan idt yang berisi total 23.688 file gambar dengan berat hanya 559,2 megabita.
Saya bangga mengumumkan versi terbaru kami! ??
Apa yang berubah
Anda dapat menginstalnya melalui pip atau mengkloning repositori ini.
user@admin:~ $ pip3 install idt
ATAU
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
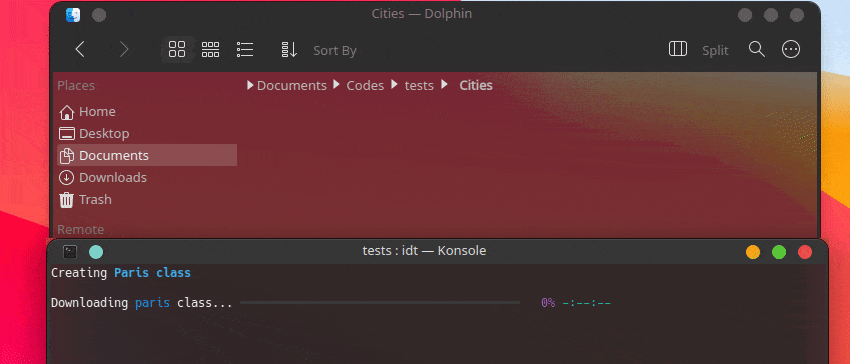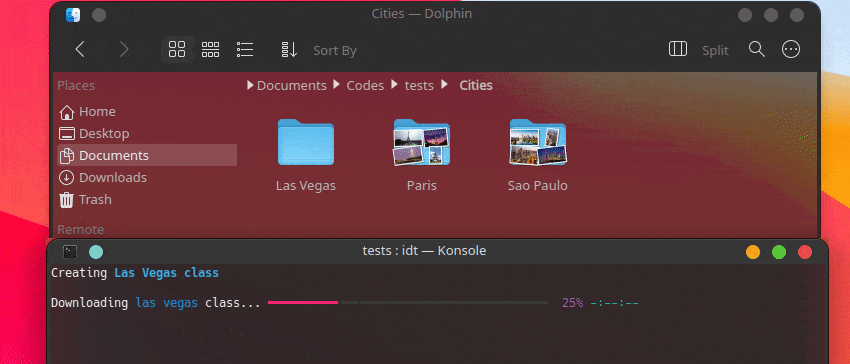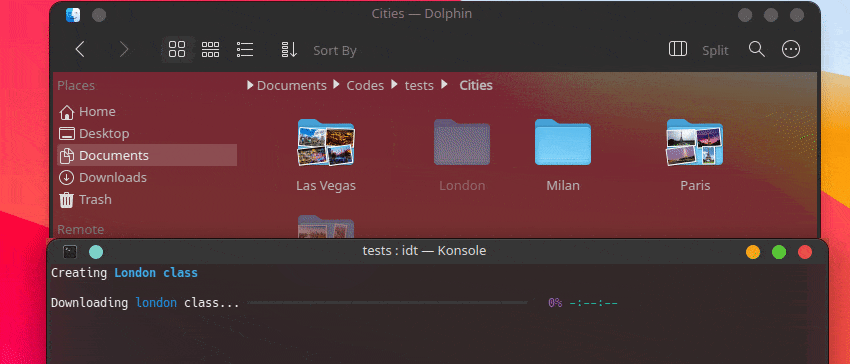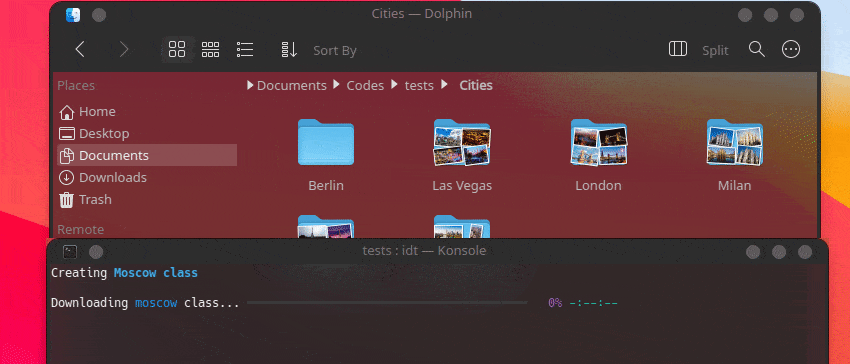
Cara tercepat untuk memulai IDT adalah dengan menjalankan perintah sederhana "jalankan". Tulis saja di konsol favorit Anda sesuatu seperti:
user@admin:~ $ idt run -i apples Ini akan dengan cepat mengunduh 50 gambar apel. Secara default ia menggunakan mesin pencari duckgo untuk melakukannya. Perintah run menerima opsi berikut:
| Pilihan | Keterangan |
|---|---|
| -i atau --masukan | kata kunci untuk menemukan gambar yang diinginkan. |
| -s atau --ukuran | jumlah gambar yang akan diunduh. |
| -e atau --mesin | mesin pencari yang diinginkan (pilihan: duckgo, bing, bing_api dan flickr_api) |
| --metode mengubah ukuran | pilih metode pengubahan ukuran gambar. (pilihan: sisi_lebih panjang, sisi_pendek, dan tanaman pintar) |
| -adalah atau --ukuran gambar | pilihan untuk mengatur rasio ukuran gambar yang diinginkan. bawaan=512 |
| -ak atau --api-key | Jika Anda menggunakan mesin pencari yang memerlukan kunci API, opsi ini diperlukan |
IDT memerlukan file konfigurasi yang memberitahukan bagaimana kumpulan data Anda harus diatur. Anda dapat membuatnya menggunakan perintah berikut:
user@admin:~ $ idt initPerintah ini akan memicu pembuat file konfigurasi dan akan menanyakan parameter dataset yang diinginkan. Dalam contoh ini mari kita membuat dataset yang berisi gambar mobil favorit Anda. Parameter pertama yang akan ditanyakan oleh perintah ini adalah nama apa yang harus dimiliki kumpulan data Anda? Dalam contoh ini, beri nama kumpulan data kita "Mobil favorit saya"
Insert a name for your dataset: : My favorite carsKemudian alat tersebut akan menanyakan berapa banyak sampel per pencarian yang diperlukan untuk memasang kumpulan data Anda. Untuk membangun kumpulan data yang baik untuk pembelajaran mendalam, diperlukan banyak gambar dan karena kami menggunakan mesin pencari untuk mengikis gambar, banyak penelusuran dengan kata kunci berbeda diperlukan untuk memasang kumpulan data berukuran baik. Nilai ini akan sesuai dengan berapa banyak gambar yang harus diunduh pada setiap pencarian. Dalam contoh ini kita memerlukan kumpulan data dengan 250 gambar di setiap kelas, dan kita akan menggunakan 5 kata kunci untuk memasang setiap kelas. Jadi jika kita mengetikkan angka 50 disini maka IDT akan mendownload 50 gambar dari setiap kata kunci yang disediakan. Jika kami menyediakan 5 kata kunci, kami akan mendapatkan 250 gambar yang dibutuhkan.
How many samples per search will be necessary? : 50Alat tersebut sekarang akan menanyakan rasio ukuran gambar. Karena menggunakan gambar besar untuk melatih jaringan saraf bukanlah hal yang layak, kita dapat memilih salah satu dari rasio ukuran gambar berikut dan memperkecil gambar kita ke ukuran tersebut. Dalam contoh ini, kita akan memilih 512x512, meskipun 256x256 akan menjadi pilihan yang lebih baik untuk tugas ini.
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1Dan kemudian pilih "longer_side" untuk metode pengubahan ukuran.
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
Sekarang Anda harus memilih berapa banyak kelas/folder yang harus dimiliki kumpulan data Anda. Dalam contoh ini, bagian ini bisa sangat pribadi, tapi mobil favorit saya adalah: Chevrolet Impala, Range Rover Evoque, Tesla Model X dan (mengapa tidak) AvtoVAZ Lada. Jadi dalam hal ini kami memiliki 4 kelas, satu untuk setiap favorit.
How many image classes are required? : 4Setelah itu, Anda akan diminta untuk memilih salah satu mesin pencari yang tersedia. Dalam contoh ini, kita akan menggunakan DuckGO untuk mencari gambar kita.
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1Sekarang kita harus melakukan pengisian formulir berulang-ulang. Kita harus memberi nama setiap kelas dan semua kata kunci yang akan digunakan untuk menemukan gambar tersebut. Perhatikan bahwa bagian ini nantinya dapat diubah dengan kode Anda sendiri, untuk menghasilkan lebih banyak kelas dan kata kunci.
Class 1 name: : Chevrolet ImpalaSetelah mengetikkan nama kelas pertama, kita akan diminta untuk memberikan semua kata kunci untuk menemukan dataset. Ingatlah bahwa kami memberi tahu program untuk mengunduh 50 gambar dari setiap kata kunci sehingga kami harus menyediakan 5 kata kunci dalam hal ini untuk mendapatkan 250 gambar tersebut. Setiap kata kunci HARUS dipisahkan dengan koma(,)
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
Kemudian ulangi proses pengisian nama kelas dan kata kuncinya hingga Anda memenuhi keempat kelas yang dibutuhkan.
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!File konfigurasi kumpulan data Anda telah dibuat. Sekarang cukup perintahkan perintah berikut dan lihat keajaiban terjadi:
user@admin:~ $ idt buildDan tunggu sementara kumpulan data sedang dipasang:
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
Pada akhirnya, semua gambar Anda akan tersedia di folder dengan nama kumpulan data. Selain itu, file csv dengan statistik kumpulan data juga disertakan dalam folder akar kumpulan data.
Karena pembelajaran mendalam sering kali mengharuskan Anda membagi kumpulan data menjadi beberapa subkumpulan folder pelatihan/validasi, proyek ini juga dapat melakukannya untuk Anda! Jalankan saja:
user@admin:~ $ idt splitSekarang Anda harus memilih proporsi kereta/valid. Dalam contoh ini saya telah memilih bahwa 70% gambar akan dicadangkan untuk pelatihan, sedangkan sisanya akan dicadangkan untuk validasi:
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: yDan itu saja! Pemisahan kumpulan data sekarang harus ditemukan dengan subdirektori train/valid yang sesuai.
Proyek ini dikembangkan di waktu senggang saya dan masih membutuhkan banyak usaha agar bebas dari bug. Permintaan tarik dan kontributor sangat dihargai, jangan ragu untuk berkontribusi dengan cara apa pun yang Anda bisa!


