T5Elasticsearch
1.0.0
Di bawah ini adalah contoh pencarian kerja:
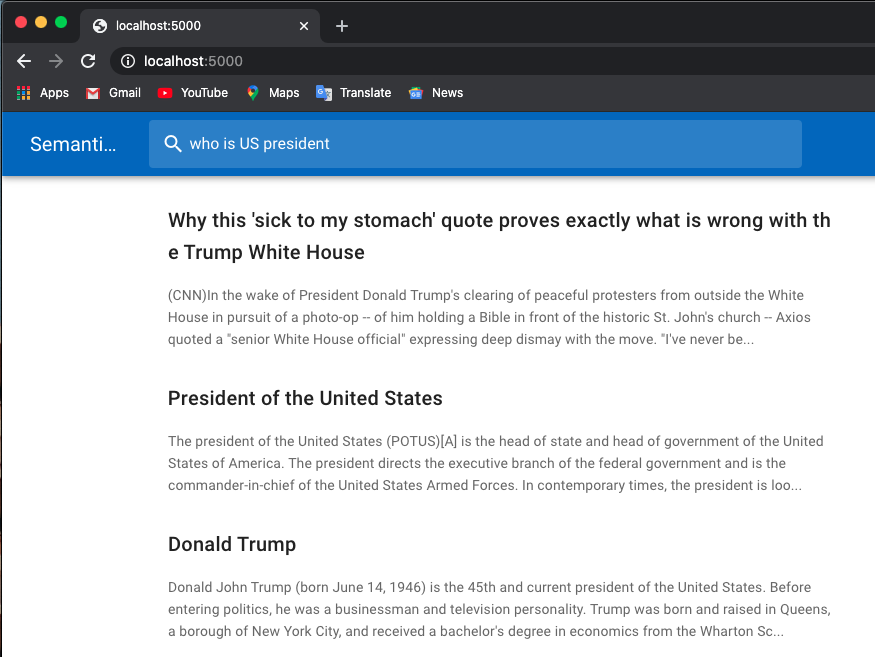
Saya menggunakan model terlatih dari Huggingface Transformers.
Unduh tokenizer dan model t5/bert yang telah dilatih sebelumnya secara manual ke direktori lokal. Anda dapat memeriksa model di sini.
Saya menggunakan model 't5-small', periksa di sini dan klik List all files in model untuk mengunduh file.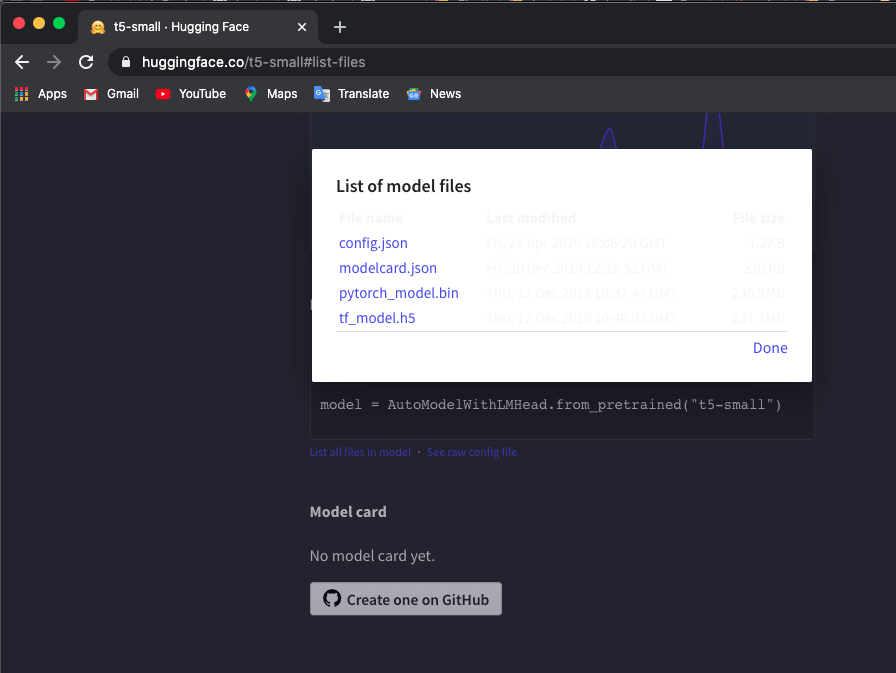
Perhatikan struktur direktori file yang diunduh secara manual.
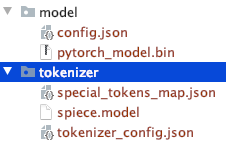
Anda bisa menggunakan model T5 atau Bert lainnya.
Jika Anda mengunduh model lain, periksa daftar model yang telah disiapkan sebelumnya Hugaface Transformers untuk memeriksa nama model.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build Saya juga menggunakan docker system prune untuk menghapus semua wadah, jaringan, dan gambar yang tidak digunakan untuk mendapatkan lebih banyak memori. Tingkatkan memori buruh pelabuhan Anda (saya menggunakan 8GB ) jika Anda menemukan kesalahan Container exits with non-zero exit code 137 .
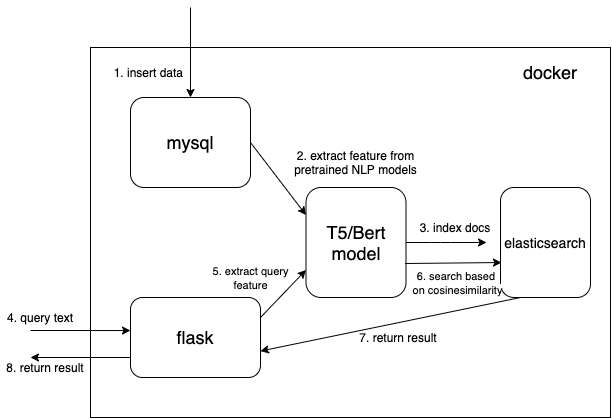
Kami menggunakan tipe data vektor padat untuk menyimpan fitur yang diekstraksi dari model NLP yang telah dilatih sebelumnya (t5 atau bert di sini, tetapi Anda dapat menambahkan sendiri model terlatih yang Anda minati)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} Dimensi dims:512 untuk model T5. Ubah dims ke 768 jika Anda menggunakan model Bert.
Baca dokumen dari mysql dan ubah dokumen ke dalam format json yang benar untuk dimasukkan ke dalam elasticsearch secara massal.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'Kunjungi http://127.0.0.1:5000.
Kode kunci untuk menggunakan model terlatih untuk mengekstrak fitur adalah fungsi get_emb dalam file ./index_files/indexing_files.py dan ./web/app.py .
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()Anda dapat mengubah kode dan menggunakan model favorit Anda yang telah dilatih sebelumnya. Misalnya, Anda bisa menggunakan model GPT2.
Anda juga dapat menyesuaikan elasticsearch dengan menggunakan fungsi skor Anda sendiri alih-alih cosineSimilarity di .webapp.py .
Perwakilan ini dimodifikasi berdasarkan Hironsan/bertsearch, yang menggunakan paket bert-serving untuk mengekstrak fitur bert. Ini terbatas pada TF1.x


