system design primer
1.0.0
Bahasa Inggris ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Tambahkan Terjemahan
Bantu terjemahkan panduan ini!
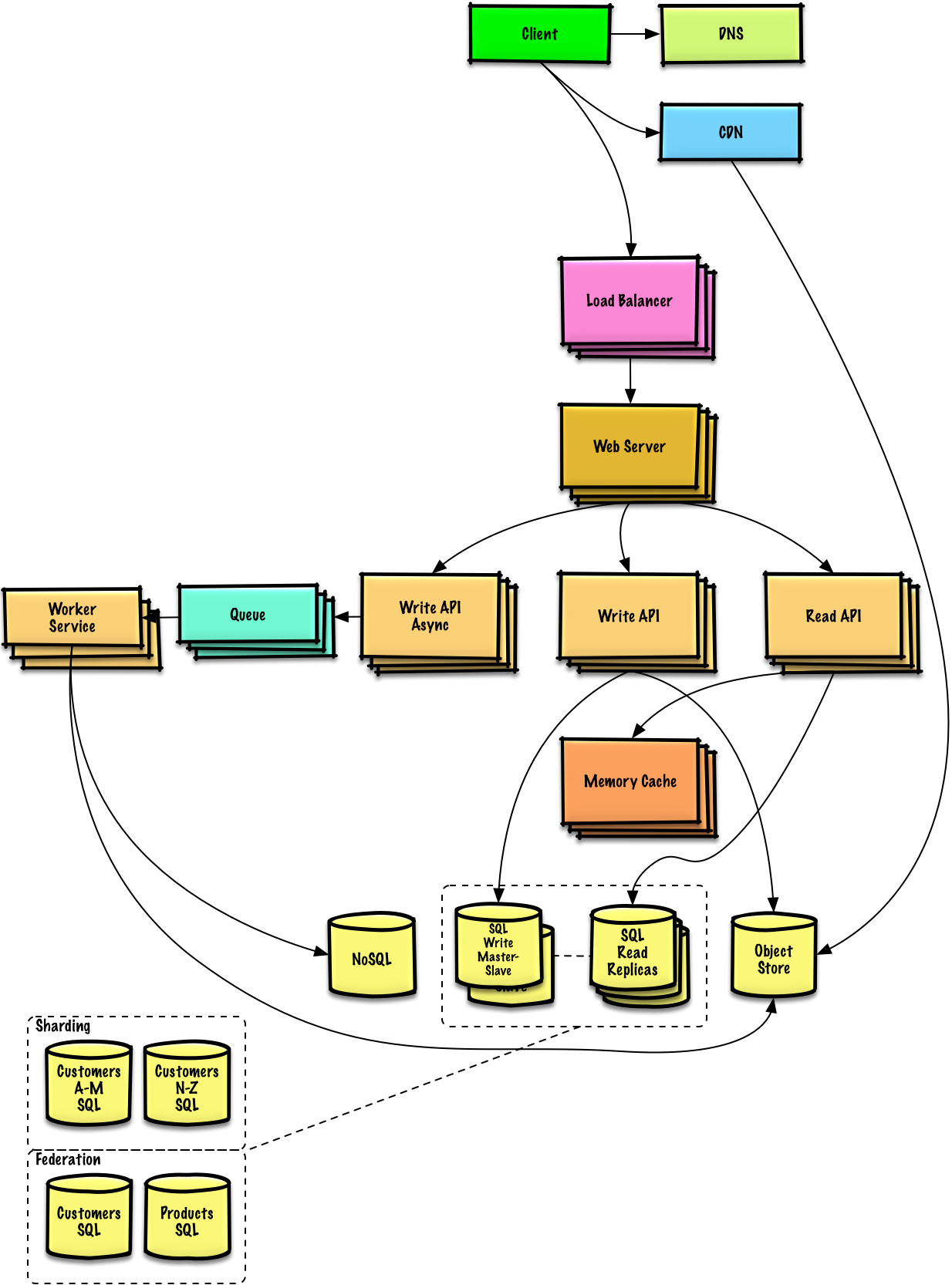
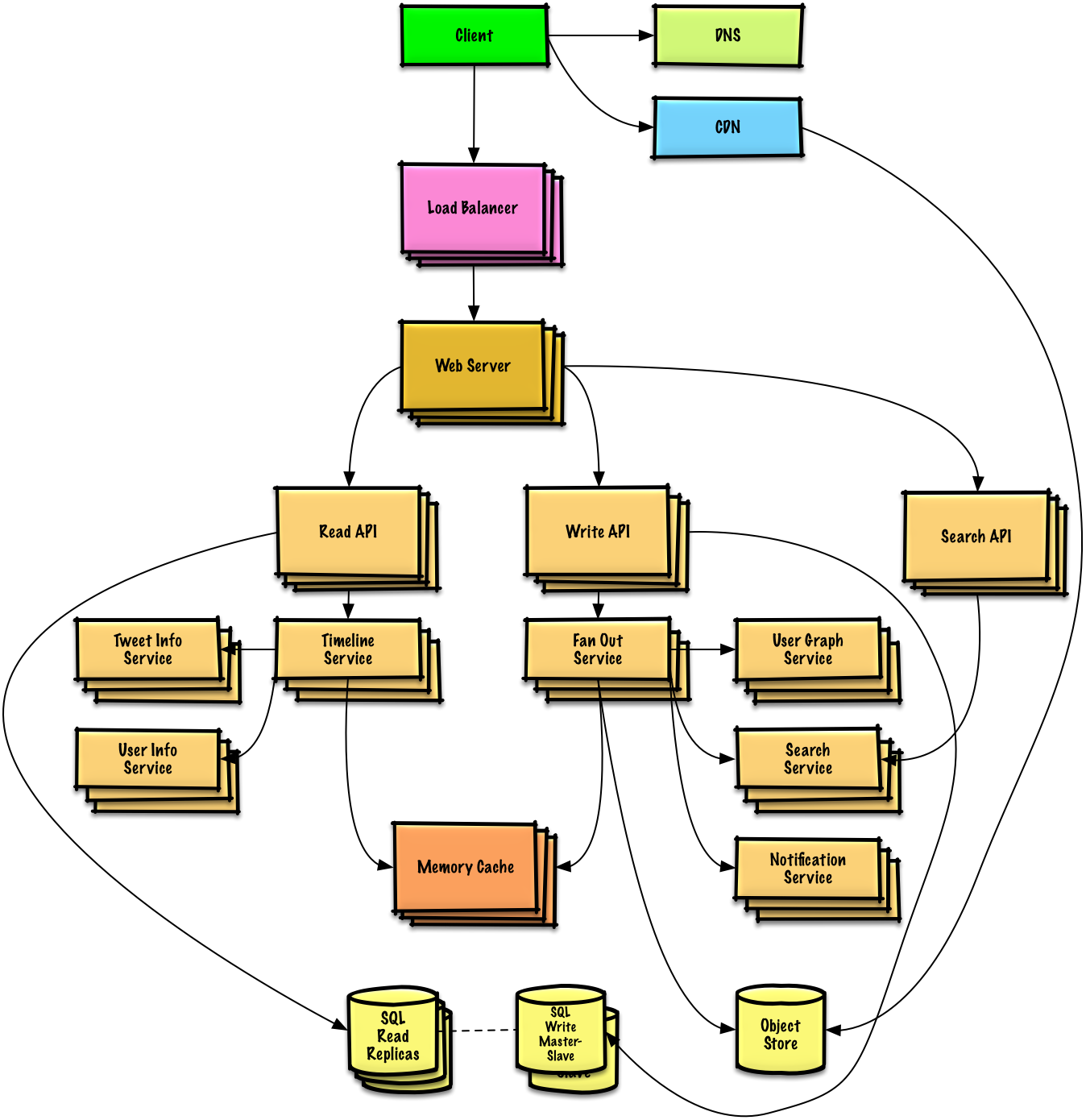
Pelajari cara merancang sistem skala besar.
Persiapan untuk wawancara desain sistem.
Mempelajari cara merancang sistem yang skalabel akan membantu Anda menjadi insinyur yang lebih baik.
Desain sistem adalah topik yang luas. Ada banyak sekali sumber daya yang tersebar di seluruh web mengenai prinsip-prinsip desain sistem.
Repo ini adalah kumpulan sumber daya terorganisir untuk membantu Anda mempelajari cara membangun sistem dalam skala besar.
Ini adalah proyek sumber terbuka yang terus diperbarui.
Kontribusi dipersilakan!
Selain coding wawancara, desain sistem merupakan komponen wajib dalam proses wawancara teknis di banyak perusahaan teknologi.
Latih pertanyaan wawancara desain sistem umum dan bandingkan hasil Anda dengan contoh solusi : diskusi, kode, dan diagram.
Topik tambahan untuk persiapan wawancara:
Dek kartu flash Anki yang disediakan menggunakan pengulangan spasi untuk membantu Anda mempertahankan konsep desain sistem utama.
Cocok untuk digunakan saat bepergian.
Mencari sumber daya untuk membantu Anda mempersiapkan Wawancara Coding ?
Lihat Sister Repo Interactive Coding Challenges , yang berisi dek Anki tambahan:
Belajar dari komunitas.
Jangan ragu untuk mengirimkan permintaan tarik untuk membantu:
Konten yang perlu dipoles sedang dalam pengembangan.
Tinjau Pedoman Berkontribusi.
Ringkasan berbagai topik desain sistem, termasuk pro dan kontra. Semuanya adalah trade-off .
Setiap bagian berisi tautan ke sumber daya yang lebih mendalam.
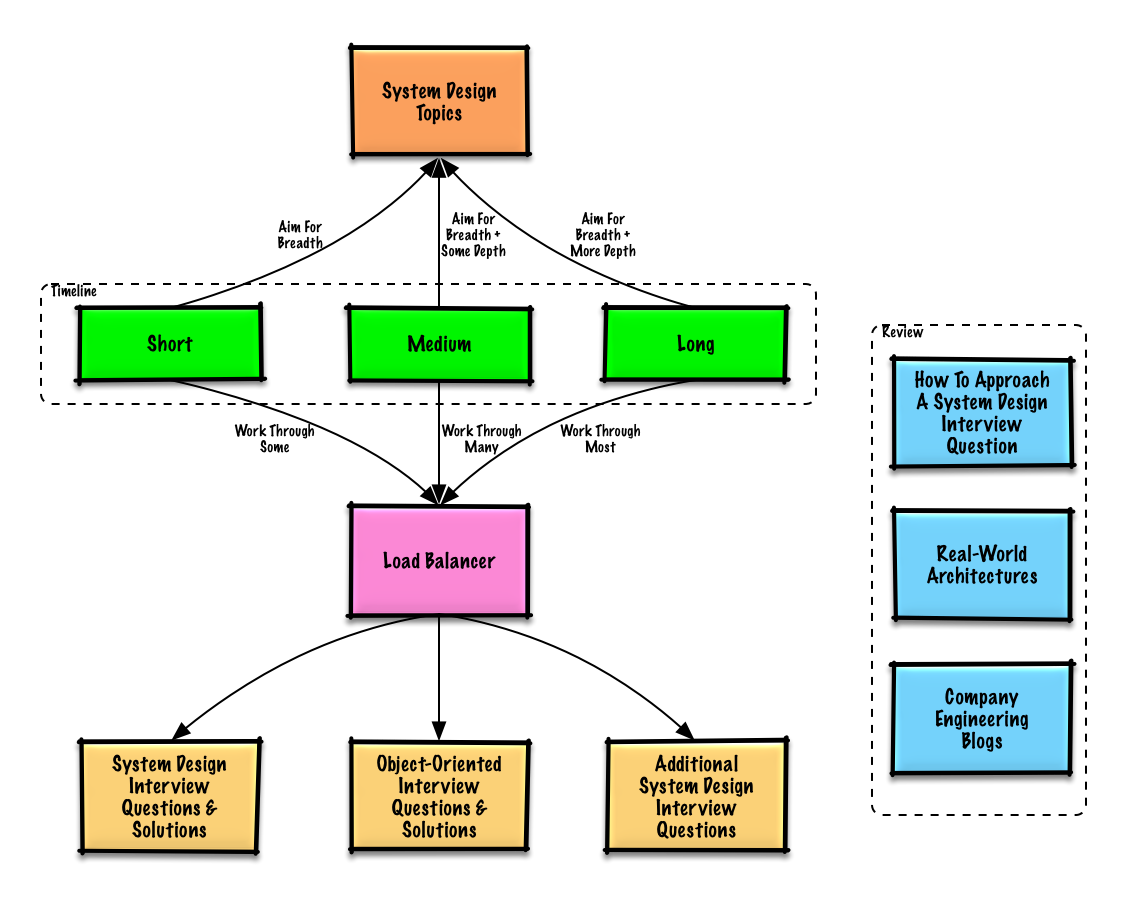
Topik yang disarankan untuk ditinjau berdasarkan jadwal wawancara Anda (pendek, sedang, panjang).
Q: Untuk wawancara, apakah saya perlu mengetahui semuanya di sini?
A: Tidak, Anda tidak perlu mengetahui semuanya di sini untuk mempersiapkan wawancara .
Apa yang ditanyakan kepada Anda dalam sebuah wawancara bergantung pada variabel-variabel seperti:
Kandidat yang lebih berpengalaman umumnya diharapkan mengetahui lebih banyak tentang desain sistem. Arsitek atau pimpinan tim mungkin diharapkan mengetahui lebih banyak daripada kontributor individu. Perusahaan teknologi terkemuka kemungkinan besar akan mengadakan satu atau lebih putaran wawancara desain.
Mulailah secara luas dan pelajari lebih dalam di beberapa bidang. Mengetahui sedikit tentang berbagai topik desain sistem utama akan membantu. Sesuaikan panduan berikut berdasarkan timeline Anda, pengalaman, posisi apa yang Anda wawancarai, dan perusahaan mana yang Anda wawancarai.
| Pendek | Sedang | Panjang | |
|---|---|---|---|
| Baca topik desain Sistem untuk mendapatkan pemahaman luas tentang cara kerja sistem | ? | ? | ? |
| Bacalah beberapa artikel di blog teknik Perusahaan untuk perusahaan yang Anda wawancarai | ? | ? | ? |
| Bacalah beberapa arsitektur dunia nyata | ? | ? | ? |
| Tinjau Bagaimana mendekati pertanyaan wawancara desain sistem | ? | ? | ? |
| Selesaikan pertanyaan wawancara desain sistem dengan solusi | Beberapa | Banyak | Paling |
| Selesaikan pertanyaan wawancara desain berorientasi objek dengan solusi | Beberapa | Banyak | Paling |
| Tinjau pertanyaan wawancara desain sistem tambahan | Beberapa | Banyak | Paling |
Bagaimana menjawab pertanyaan wawancara desain sistem.
Wawancara desain sistem adalah percakapan terbuka . Anda diharapkan untuk memimpinnya.
Anda dapat menggunakan langkah-langkah berikut untuk memandu diskusi. Untuk membantu memantapkan proses ini, kerjakan bagian pertanyaan wawancara desain sistem dengan solusi menggunakan langkah-langkah berikut.
Kumpulkan persyaratan dan cakup masalahnya. Ajukan pertanyaan untuk memperjelas kasus penggunaan dan batasannya. Diskusikan asumsi.
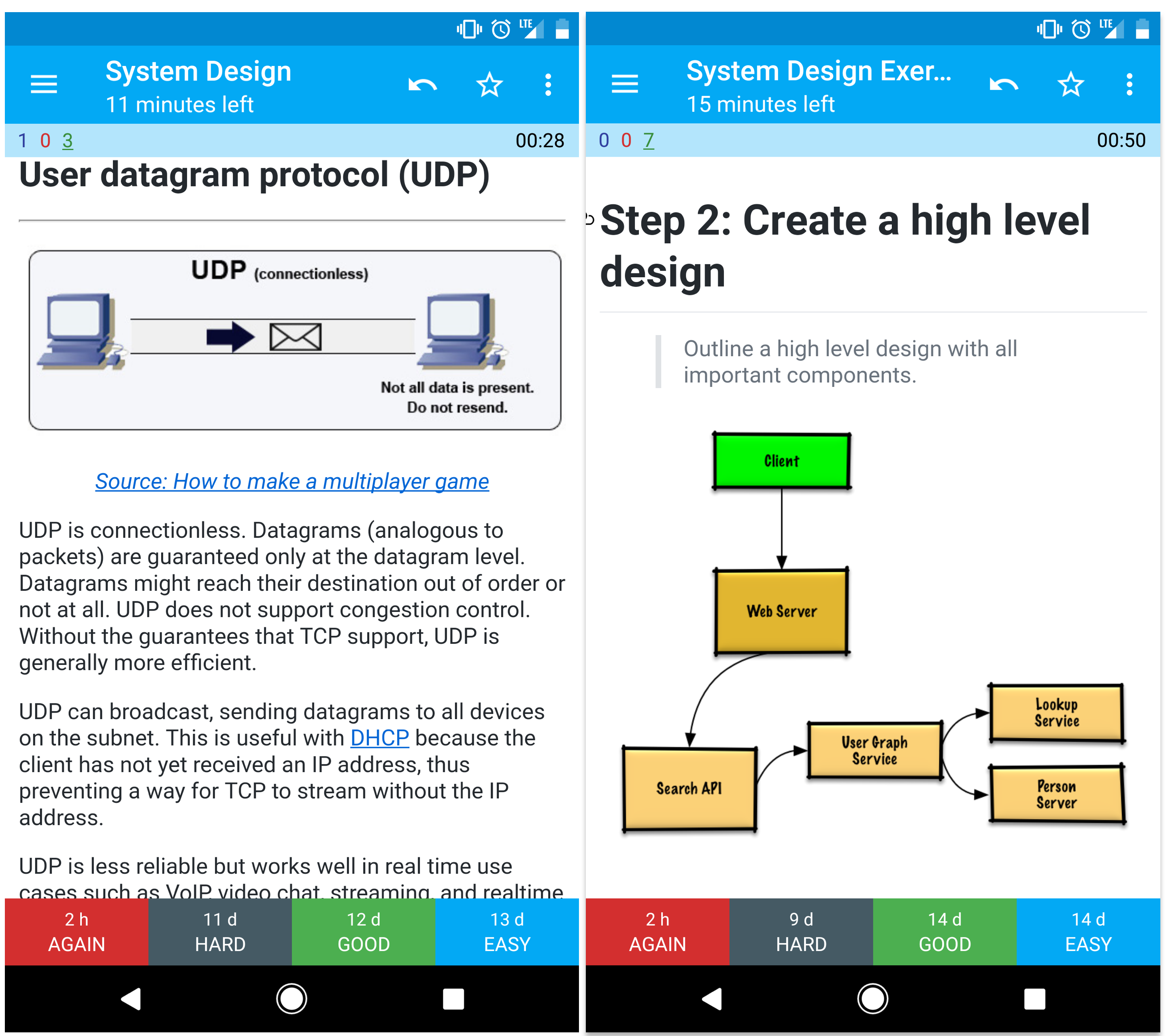
Buat garis besar desain tingkat tinggi dengan semua komponen penting.
Selidiki detail untuk setiap komponen inti. Misalnya, jika Anda diminta merancang layanan pemendek url, diskusikan:
Identifikasi dan atasi hambatan, mengingat kendalanya. Misalnya, apakah Anda memerlukan hal berikut untuk mengatasi masalah skalabilitas?
Diskusikan potensi solusi dan trade-off. Semuanya adalah trade-off. Atasi kemacetan menggunakan prinsip desain sistem yang dapat diskalakan.
Anda mungkin diminta melakukan beberapa perkiraan dengan tangan. Lihat Lampiran untuk sumber daya berikut:
Lihat tautan berikut untuk mendapatkan gambaran yang lebih baik tentang apa yang diharapkan:
Pertanyaan wawancara desain sistem umum dengan contoh diskusi, kode, dan diagram.
Solusi ditautkan ke konten dalam folder
solutions/.
| Pertanyaan | |
|---|---|
| Desain Pastebin.com (atau Bit.ly) | Larutan |
| Rancang timeline dan pencarian Twitter (atau feed dan pencarian Facebook) | Larutan |
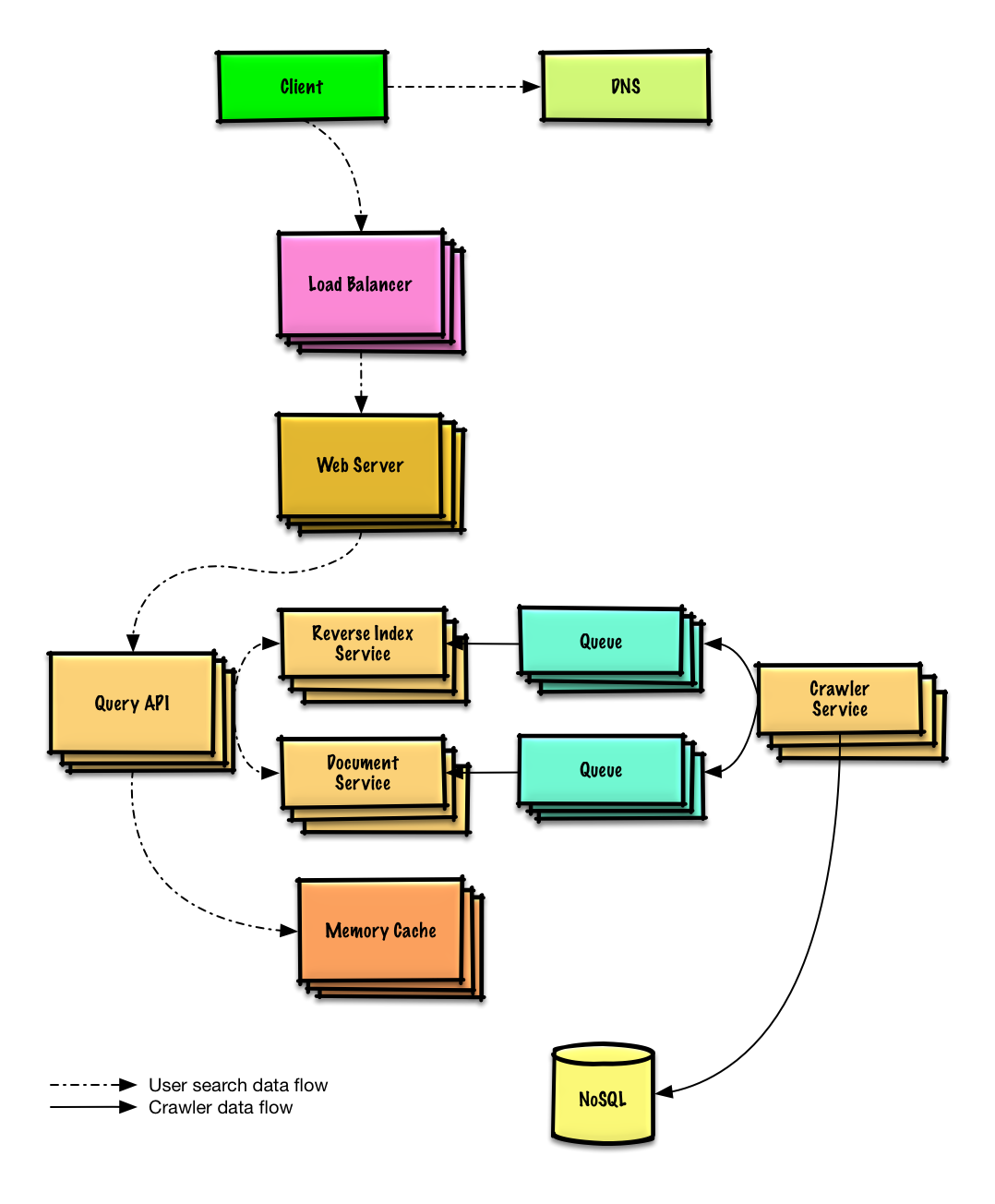
| Rancang perayap web | Larutan |
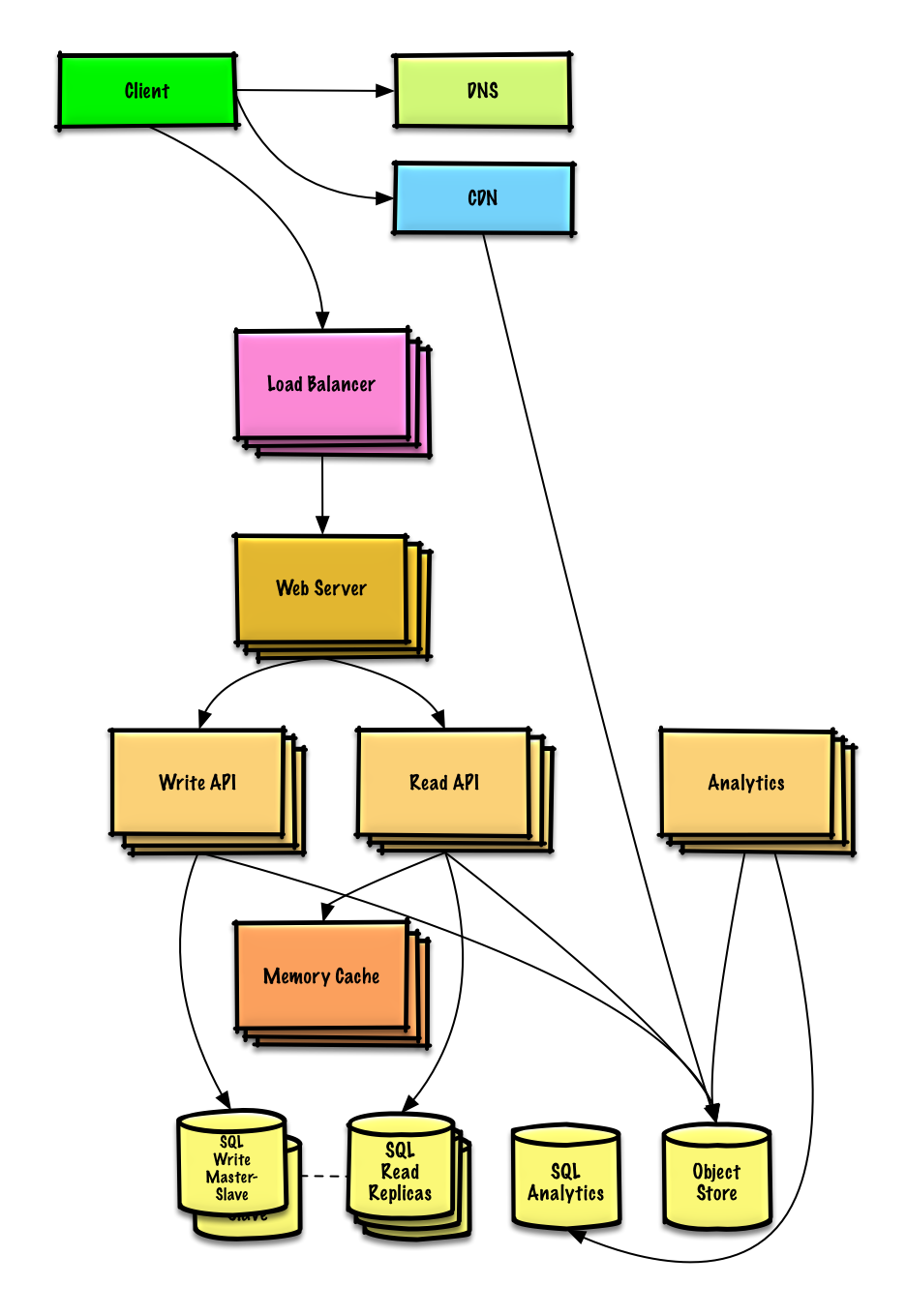
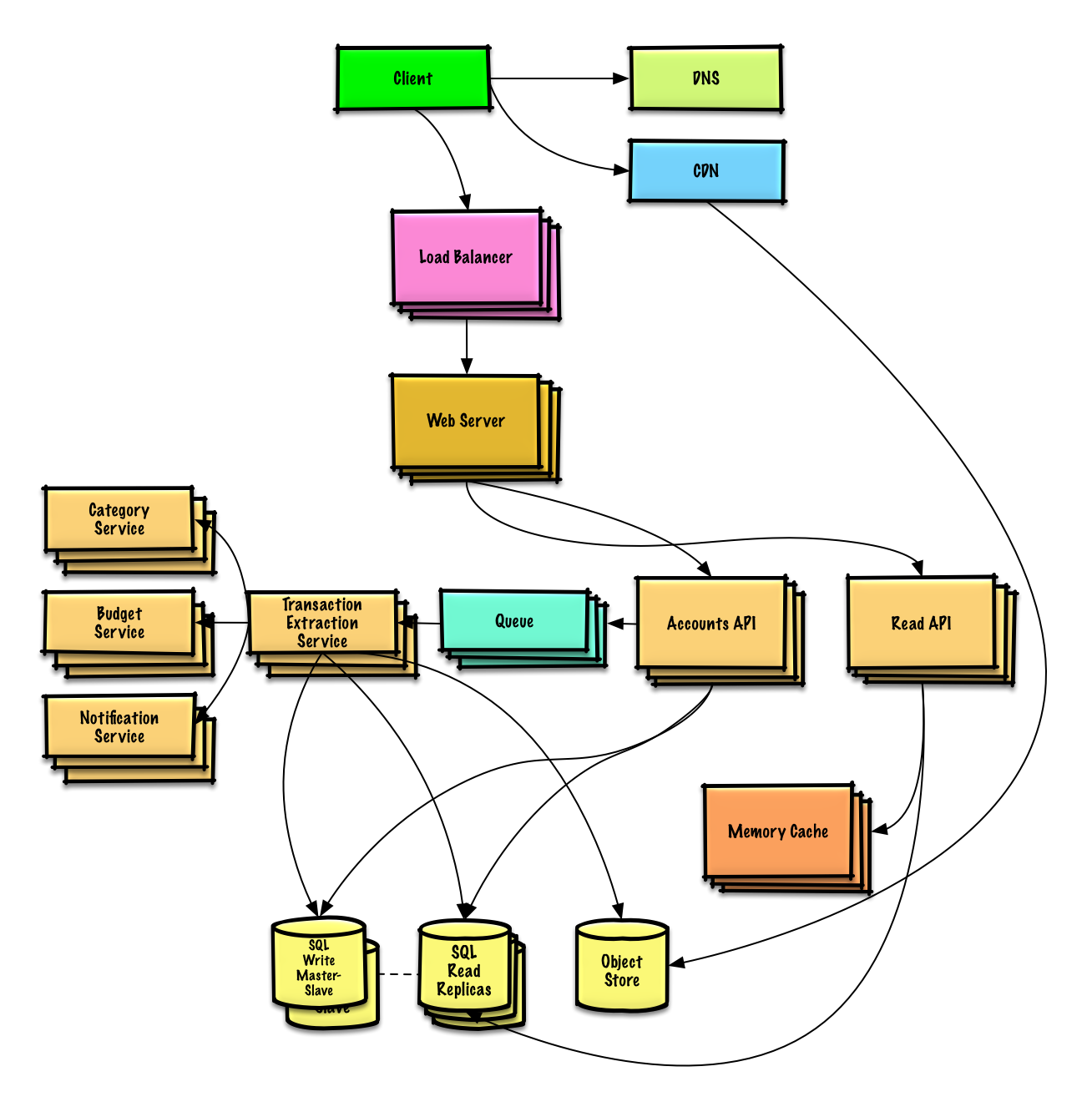
| Desain Mint.com | Larutan |
| Rancang struktur data untuk jaringan sosial | Larutan |
| Rancang penyimpanan nilai kunci untuk mesin pencari | Larutan |
| Rancang peringkat penjualan Amazon berdasarkan fitur kategori | Larutan |
| Rancang sistem yang dapat menjangkau jutaan pengguna di AWS | Larutan |
| Tambahkan pertanyaan desain sistem | Menyumbang |
Lihat latihan dan solusinya
Lihat latihan dan solusinya
Lihat latihan dan solusinya
Lihat latihan dan solusinya
Lihat latihan dan solusinya
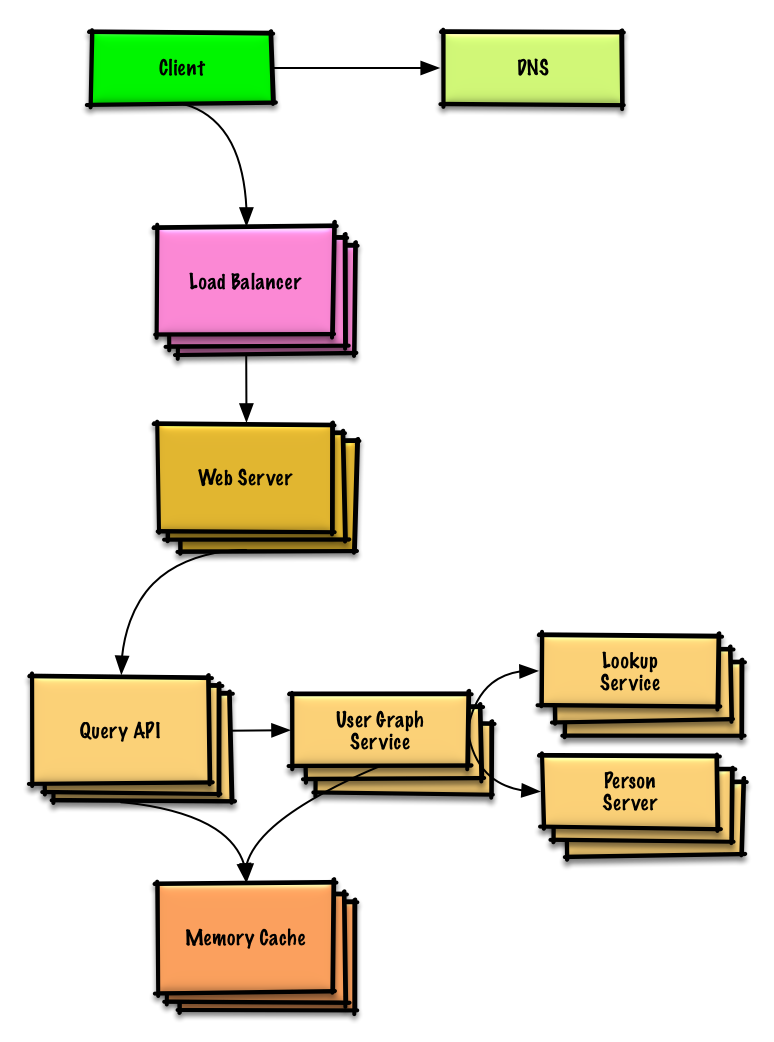
Lihat latihan dan solusinya
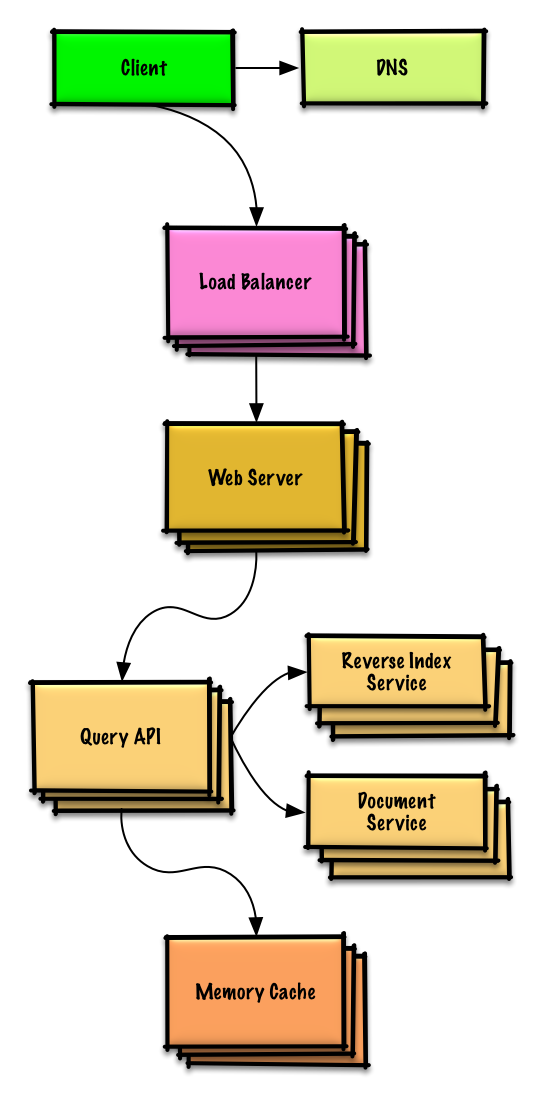
Lihat latihan dan solusinya
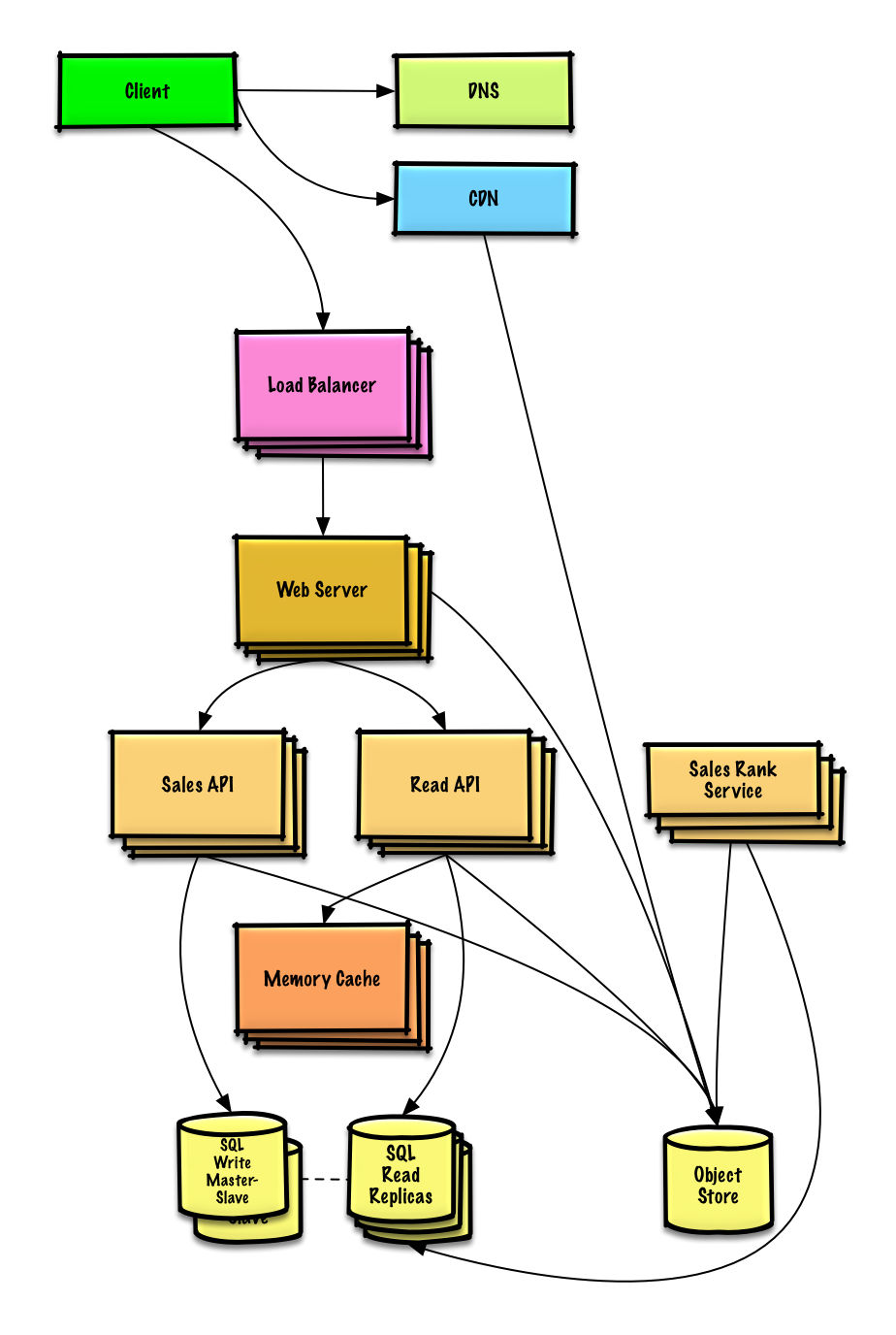
Lihat latihan dan solusinya
Pertanyaan wawancara desain berorientasi objek umum dengan contoh diskusi, kode, dan diagram.
Solusi ditautkan ke konten dalam folder
solutions/.
Catatan: Bagian ini sedang dalam pengembangan
| Pertanyaan | |
|---|---|
| Rancang peta hash | Larutan |
| Rancang cache yang terakhir digunakan | Larutan |
| Desain pusat panggilan | Larutan |
| Rancang setumpuk kartu | Larutan |
| Desain tempat parkir | Larutan |
| Rancang server obrolan | Larutan |
| Rancang susunan melingkar | Menyumbang |
| Tambahkan pertanyaan desain berorientasi objek | Menyumbang |
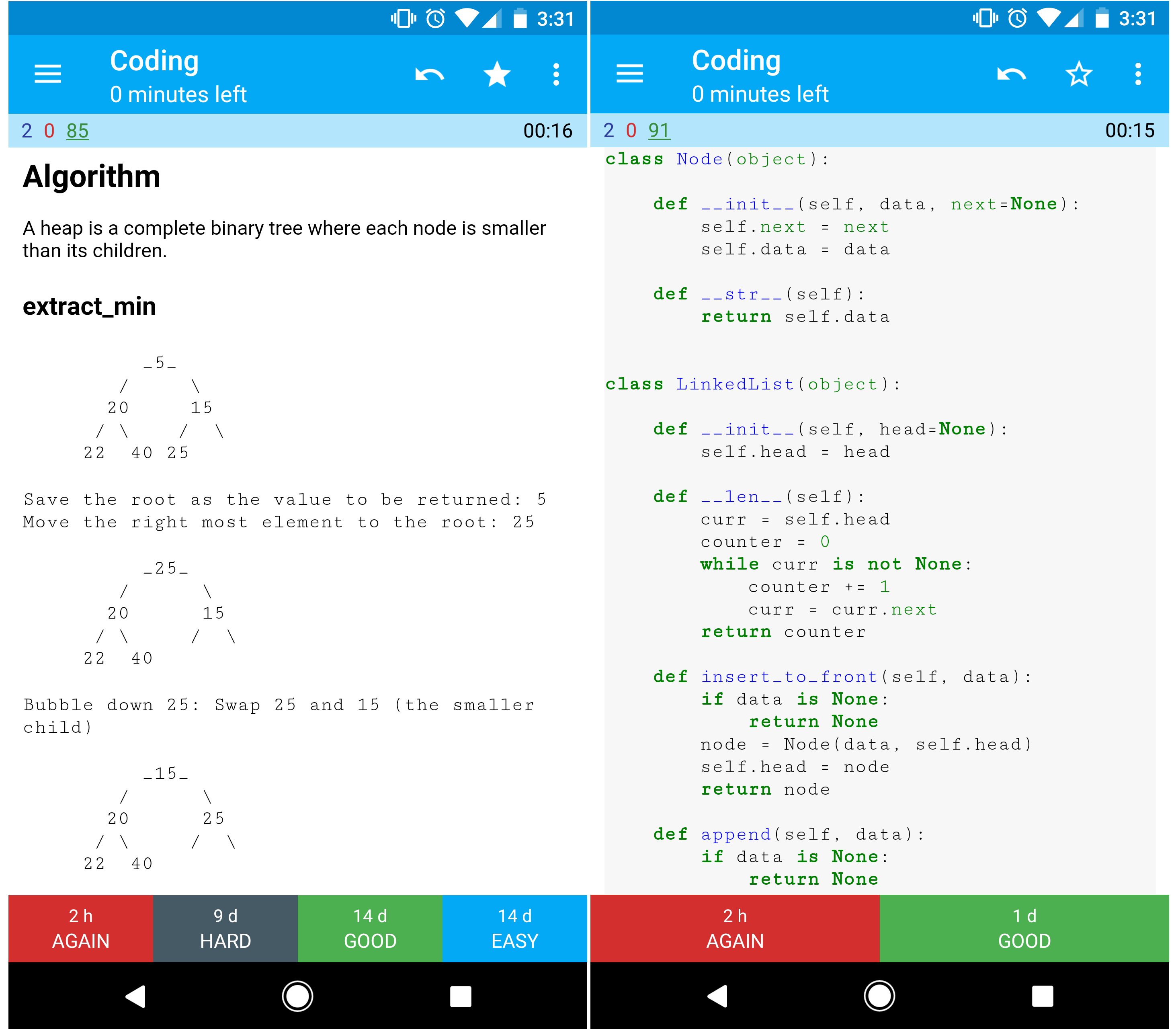
Baru mengenal desain sistem?
Pertama, Anda memerlukan pemahaman dasar tentang prinsip-prinsip umum, mempelajari apa prinsip-prinsip tersebut, bagaimana penggunaannya, serta kelebihan dan kekurangannya.
Kuliah Skalabilitas di Harvard
Skalabilitas
Selanjutnya, kita akan melihat trade-off tingkat tinggi:
Ingatlah bahwa semuanya adalah trade-off .
Kemudian kita akan mendalami topik yang lebih spesifik seperti DNS, CDN, dan penyeimbang beban.
Suatu layanan dapat diskalakan jika menghasilkan peningkatan kinerja yang sebanding dengan sumber daya yang ditambahkan. Secara umum, meningkatkan kinerja berarti melayani lebih banyak unit kerja, namun bisa juga menangani unit kerja yang lebih besar, misalnya saat kumpulan data bertambah. 1
Cara lain untuk melihat kinerja vs skalabilitas:
Latensi adalah waktu untuk melakukan suatu tindakan atau menghasilkan suatu hasil.
Throughput adalah jumlah tindakan atau hasil tersebut per unit waktu.
Secara umum, Anda harus menargetkan throughput maksimal dengan latensi yang dapat diterima .
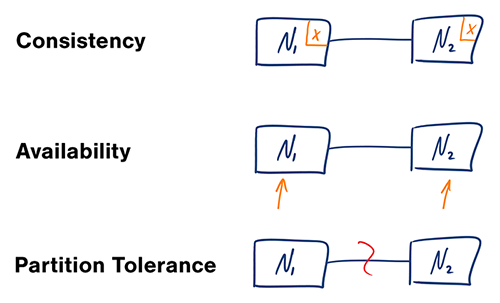
Sumber: teorema CAP ditinjau kembali
Dalam sistem komputer terdistribusi, Anda hanya dapat mendukung dua jaminan berikut:
Jaringan tidak dapat diandalkan, jadi Anda harus mendukung toleransi partisi. Anda harus membuat tradeoff perangkat lunak antara konsistensi dan ketersediaan.
Menunggu respons dari node yang dipartisi mungkin mengakibatkan kesalahan batas waktu. CP adalah pilihan yang baik jika kebutuhan bisnis Anda memerlukan pembacaan dan penulisan atom.
Respons mengembalikan versi data yang paling tersedia di node mana pun, yang mungkin bukan versi terbaru. Penulisan mungkin memerlukan waktu untuk disebarkan ketika partisi diselesaikan.
AP adalah pilihan yang baik jika bisnis perlu memungkinkan konsistensi pada akhirnya atau ketika sistem perlu terus bekerja meskipun ada kesalahan eksternal.
Dengan banyak salinan data yang sama, kita dihadapkan pada opsi tentang cara menyinkronkannya sehingga klien memiliki tampilan data yang konsisten. Ingat kembali definisi konsistensi dari teorema CAP - Setiap pembacaan menerima penulisan terbaru atau kesalahan.
Setelah menulis, membaca mungkin melihatnya atau tidak. Pendekatan upaya terbaik diambil.
Pendekatan ini terlihat pada sistem seperti memcached. Konsistensi yang lemah berfungsi dengan baik dalam kasus penggunaan waktu nyata seperti VoIP, obrolan video, dan game multipemain waktu nyata. Misalnya, jika Anda sedang melakukan panggilan telepon dan kehilangan penerimaan selama beberapa detik, saat sambungan tersambung kembali, Anda tidak akan mendengar apa yang diucapkan saat sambungan terputus.
Setelah penulisan, pembacaan pada akhirnya akan melihatnya (biasanya dalam milidetik). Data direplikasi secara asinkron.
Pendekatan ini terlihat pada sistem seperti DNS dan email. Konsistensi akhirnya bekerja dengan baik dalam sistem dengan ketersediaan tinggi.
Setelah menulis, membaca akan melihatnya. Data direplikasi secara sinkron.
Pendekatan ini terlihat pada sistem file dan RDBMS. Konsistensi yang kuat bekerja dengan baik dalam sistem yang memerlukan transaksi.
Ada dua pola yang saling melengkapi untuk mendukung ketersediaan tinggi: failover dan replikasi .
Dengan failover aktif-pasif, detak jantung dikirim antara server aktif dan pasif dalam keadaan siaga. Jika detak jantung terganggu, server pasif mengambil alih alamat IP aktif dan melanjutkan layanan.
Lamanya waktu henti ditentukan oleh apakah server pasif sudah berjalan dalam keadaan siaga 'panas' atau perlu memulai dari keadaan siaga 'dingin'. Hanya server aktif yang menangani lalu lintas.
Failover aktif-pasif juga dapat disebut sebagai failover master-slave.
Secara aktif-aktif, kedua server mengatur lalu lintas, menyebarkan beban di antara keduanya.
Jika server bersifat publik, DNS perlu mengetahui IP publik kedua server. Jika server menghadap ke internal, logika aplikasi perlu mengetahui tentang kedua server.
Failover aktif-aktif bisa juga disebut sebagai master-master failover.
Topik ini dibahas lebih lanjut di bagian Database:
Ketersediaan sering kali diukur berdasarkan waktu aktif (atau waktu henti) sebagai persentase waktu tersedianya layanan. Ketersediaan umumnya diukur dalam angka 9--layanan dengan ketersediaan 99,99% digambarkan memiliki empat angka 9.
| Lamanya | Waktu henti yang dapat diterima |
|---|---|
| Waktu henti per tahun | 8 jam 45 menit 57 detik |
| Waktu henti per bulan | 43m 49,7 detik |
| Waktu henti per minggu | 10m 4,8 detik |
| Waktu henti per hari | 1 menit 26,4 detik |
| Lamanya | Waktu henti yang dapat diterima |
|---|---|
| Waktu henti per tahun | 52 menit 35,7 detik |
| Waktu henti per bulan | 4 menit 23 detik |
| Waktu henti per minggu | 1m 5s |
| Waktu henti per hari | 8.6 detik |
Jika suatu layanan terdiri dari beberapa komponen yang rentan terhadap kegagalan, ketersediaan layanan secara keseluruhan bergantung pada apakah komponen-komponen tersebut berada dalam urutan atau paralel.
Ketersediaan keseluruhan menurun ketika dua komponen dengan ketersediaan < 100% berada secara berurutan:
Availability (Total) = Availability (Foo) * Availability (Bar)
Jika Foo dan Bar masing-masing memiliki ketersediaan 99,9%, total ketersediaan secara berurutan akan menjadi 99,8%.
Ketersediaan keseluruhan meningkat ketika dua komponen dengan ketersediaan <100% dipasang secara paralel:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Jika Foo dan Bar masing-masing memiliki ketersediaan 99,9%, total ketersediaan secara paralel akan menjadi 99,9999%.
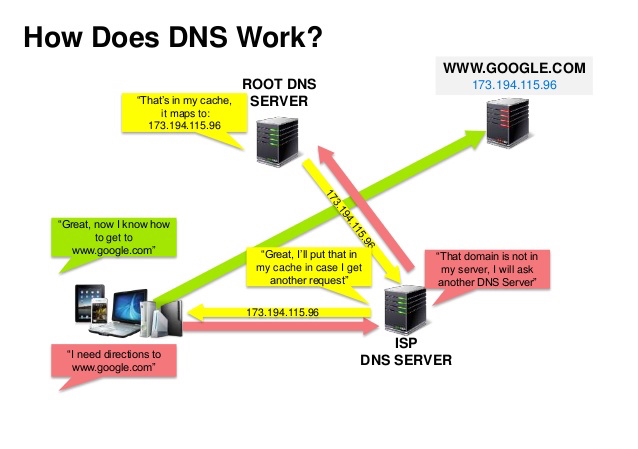
Sumber: Presentasi keamanan DNS
Sistem Nama Domain (DNS) menerjemahkan nama domain seperti www.example.com ke alamat IP.
DNS bersifat hierarkis, dengan beberapa server otoritatif di tingkat atas. Router atau ISP Anda memberikan informasi tentang server DNS mana yang harus dihubungi saat melakukan pencarian. Pemetaan cache server DNS tingkat rendah, yang dapat menjadi usang karena penundaan propagasi DNS. Hasil DNS juga dapat di-cache oleh browser atau OS Anda dalam jangka waktu tertentu, ditentukan oleh time to live (TTL).
CNAME (example.com ke www.example.com) atau ke data ALayanan seperti CloudFlare dan Route 53 menyediakan layanan DNS terkelola. Beberapa layanan DNS dapat merutekan lalu lintas melalui berbagai metode:
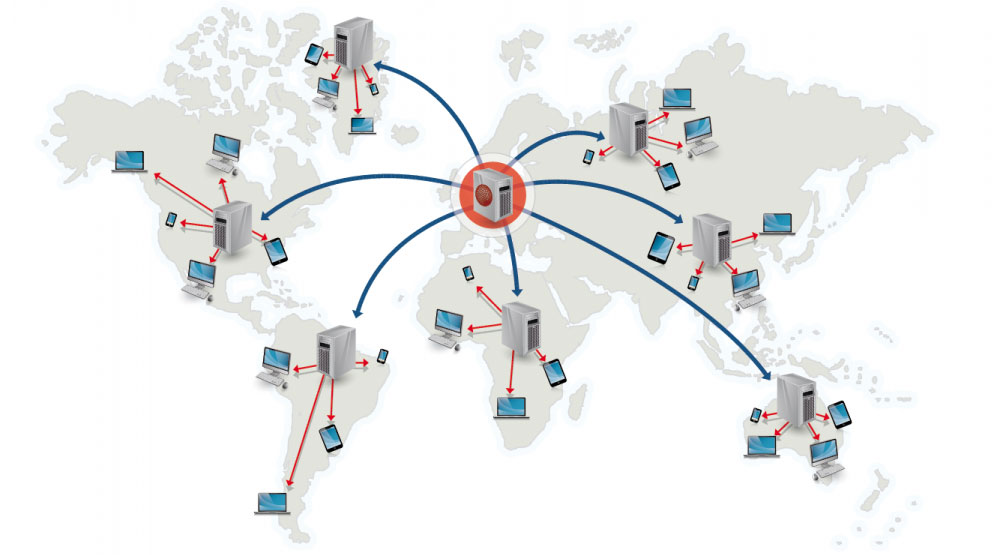
Sumber: Mengapa menggunakan CDN
Jaringan pengiriman konten (CDN) adalah jaringan server proxy yang didistribusikan secara global, menyajikan konten dari lokasi yang lebih dekat dengan pengguna. Umumnya, file statis seperti HTML/CSS/JS, foto, dan video disajikan dari CDN, meskipun beberapa CDN seperti CloudFront Amazon mendukung konten dinamis. Resolusi DNS situs akan memberi tahu klien server mana yang harus dihubungi.
Menyajikan konten dari CDN dapat meningkatkan kinerja secara signifikan dalam dua cara:
Push CDN menerima konten baru setiap kali terjadi perubahan di server Anda. Anda bertanggung jawab penuh untuk menyediakan konten, mengunggah langsung ke CDN, dan menulis ulang URL agar mengarah ke CDN. Anda dapat mengonfigurasi kapan konten kedaluwarsa dan kapan diperbarui. Konten diunggah hanya jika masih baru atau diubah, meminimalkan lalu lintas, namun memaksimalkan penyimpanan.
Situs dengan jumlah lalu lintas kecil atau situs dengan konten yang jarang diperbarui berfungsi baik dengan CDN push. Konten ditempatkan di CDN satu kali, bukan ditarik kembali secara berkala.
Pull CDN mengambil konten baru dari server Anda saat pengguna pertama meminta konten tersebut. Anda meninggalkan konten di server Anda dan menulis ulang URL agar mengarah ke CDN. Hal ini mengakibatkan permintaan lebih lambat hingga konten di-cache di CDN.
Time-to-live (TTL) menentukan berapa lama konten di-cache. Pull CDN meminimalkan ruang penyimpanan di CDN, namun dapat membuat lalu lintas berlebihan jika file kedaluwarsa dan ditarik sebelum benar-benar diubah.
Situs dengan lalu lintas padat berfungsi dengan baik dengan CDN tarik, karena lalu lintas tersebar lebih merata dengan hanya konten yang baru diminta tersisa di CDN.
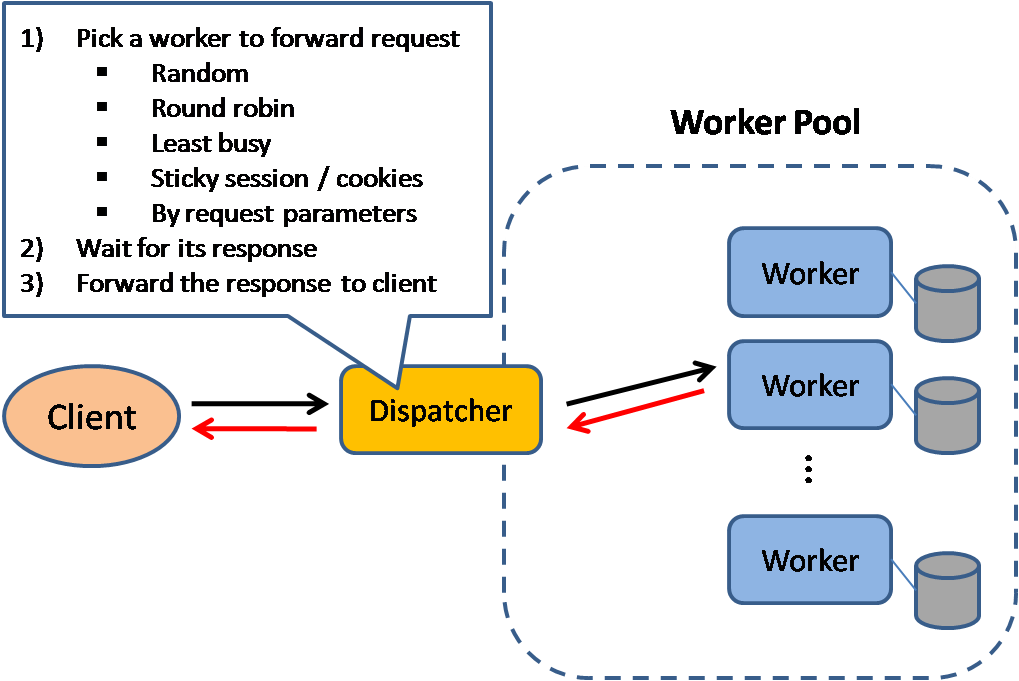
Sumber: Pola desain sistem yang dapat diskalakan
Penyeimbang beban mendistribusikan permintaan klien yang masuk ke sumber daya komputasi seperti server aplikasi dan database. Dalam setiap kasus, penyeimbang beban mengembalikan respons dari sumber daya komputasi ke klien yang sesuai. Penyeimbang beban efektif dalam:
Penyeimbang beban dapat diimplementasikan dengan perangkat keras (mahal) atau perangkat lunak seperti HAProxy.
Manfaat tambahan meliputi:
Untuk melindungi dari kegagalan, biasanya menyiapkan beberapa penyeimbang beban, baik dalam mode aktif-pasif atau aktif-aktif.
Penyeimbang beban dapat merutekan lalu lintas berdasarkan berbagai metrik, termasuk:
Penyeimbang beban lapisan 4 melihat informasi di lapisan transport untuk memutuskan cara mendistribusikan permintaan. Umumnya, ini melibatkan sumber, alamat IP tujuan, dan port di header, namun tidak melibatkan isi paket. Penyeimbang beban lapisan 4 meneruskan paket jaringan ke dan dari server upstream, melakukan Network Address Translation (NAT).
Penyeimbang beban lapisan 7 melihat lapisan aplikasi untuk memutuskan cara mendistribusikan permintaan. Hal ini dapat melibatkan isi header, pesan, dan cookie. Penyeimbang beban lapisan 7 menghentikan lalu lintas jaringan, membaca pesan, membuat keputusan penyeimbangan beban, lalu membuka koneksi ke server yang dipilih. Misalnya, penyeimbang beban lapisan 7 dapat mengarahkan lalu lintas video ke server yang menghosting video sekaligus mengarahkan lalu lintas penagihan pengguna yang lebih sensitif ke server dengan keamanan yang lebih ketat.
Dengan mengorbankan fleksibilitas, penyeimbangan beban lapisan 4 memerlukan lebih sedikit waktu dan sumber daya komputasi dibandingkan Lapisan 7, meskipun dampak kinerjanya bisa minimal pada perangkat keras komoditas modern.
Penyeimbang beban juga dapat membantu penskalaan horizontal, meningkatkan kinerja, dan ketersediaan. Peningkatan skala menggunakan mesin komoditas lebih hemat biaya dan menghasilkan ketersediaan yang lebih tinggi dibandingkan peningkatan skala server tunggal pada perangkat keras yang lebih mahal, yang disebut Penskalaan Vertikal . Juga lebih mudah untuk merekrut talenta yang bekerja pada perangkat keras komoditas dibandingkan dengan sistem perusahaan khusus.
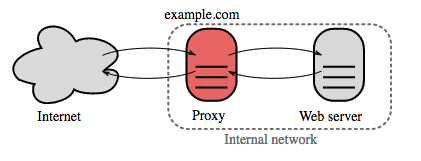
Sumber: Wikipedia
Proksi terbalik adalah server web yang memusatkan layanan internal dan menyediakan antarmuka terpadu kepada publik. Permintaan dari klien diteruskan ke server yang dapat memenuhinya sebelum reverse proxy mengembalikan respons server ke klien.
Manfaat tambahan meliputi:
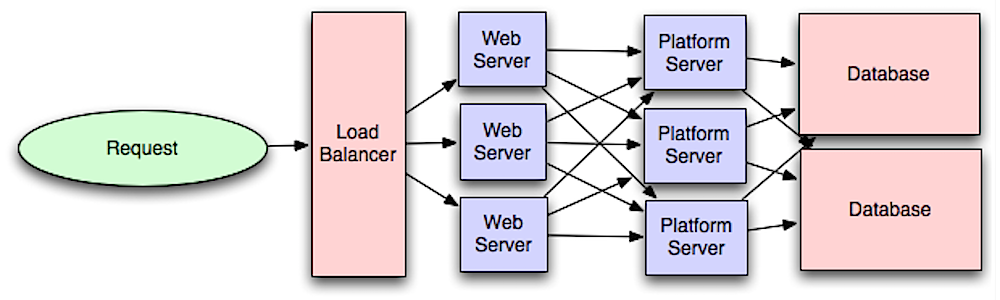
Sumber: Pengantar sistem arsitektur untuk skala
Memisahkan lapisan web dari lapisan aplikasi (juga dikenal sebagai lapisan platform) memungkinkan Anda menskalakan dan mengonfigurasi kedua lapisan secara independen. Menambahkan API baru menghasilkan penambahan server aplikasi tanpa harus menambahkan server web tambahan. Prinsip tanggung jawab tunggal menganjurkan layanan kecil dan otonom yang bekerja sama. Tim kecil dengan layanan kecil dapat membuat rencana yang lebih agresif untuk pertumbuhan yang cepat.
Pekerja di lapisan aplikasi juga membantu mengaktifkan asinkronisme.
Terkait dengan diskusi ini adalah layanan mikro, yang dapat digambarkan sebagai rangkaian layanan modular kecil yang dapat diterapkan secara independen. Setiap layanan menjalankan proses unik dan berkomunikasi melalui mekanisme yang terdefinisi dengan baik dan ringan untuk mencapai tujuan bisnis. 1
Pinterest, misalnya, dapat memiliki layanan mikro berikut: profil pengguna, pengikut, umpan, pencarian, unggahan foto, dll.
Sistem seperti Konsul, Dll, dan Zookeeper dapat membantu layanan menemukan satu sama lain dengan melacak nama, alamat, dan port yang terdaftar. Pemeriksaan kesehatan membantu memverifikasi integritas layanan dan sering kali dilakukan menggunakan titik akhir HTTP. Baik Konsul maupun Etcd memiliki penyimpanan nilai kunci bawaan yang dapat berguna untuk menyimpan nilai konfigurasi dan data bersama lainnya.
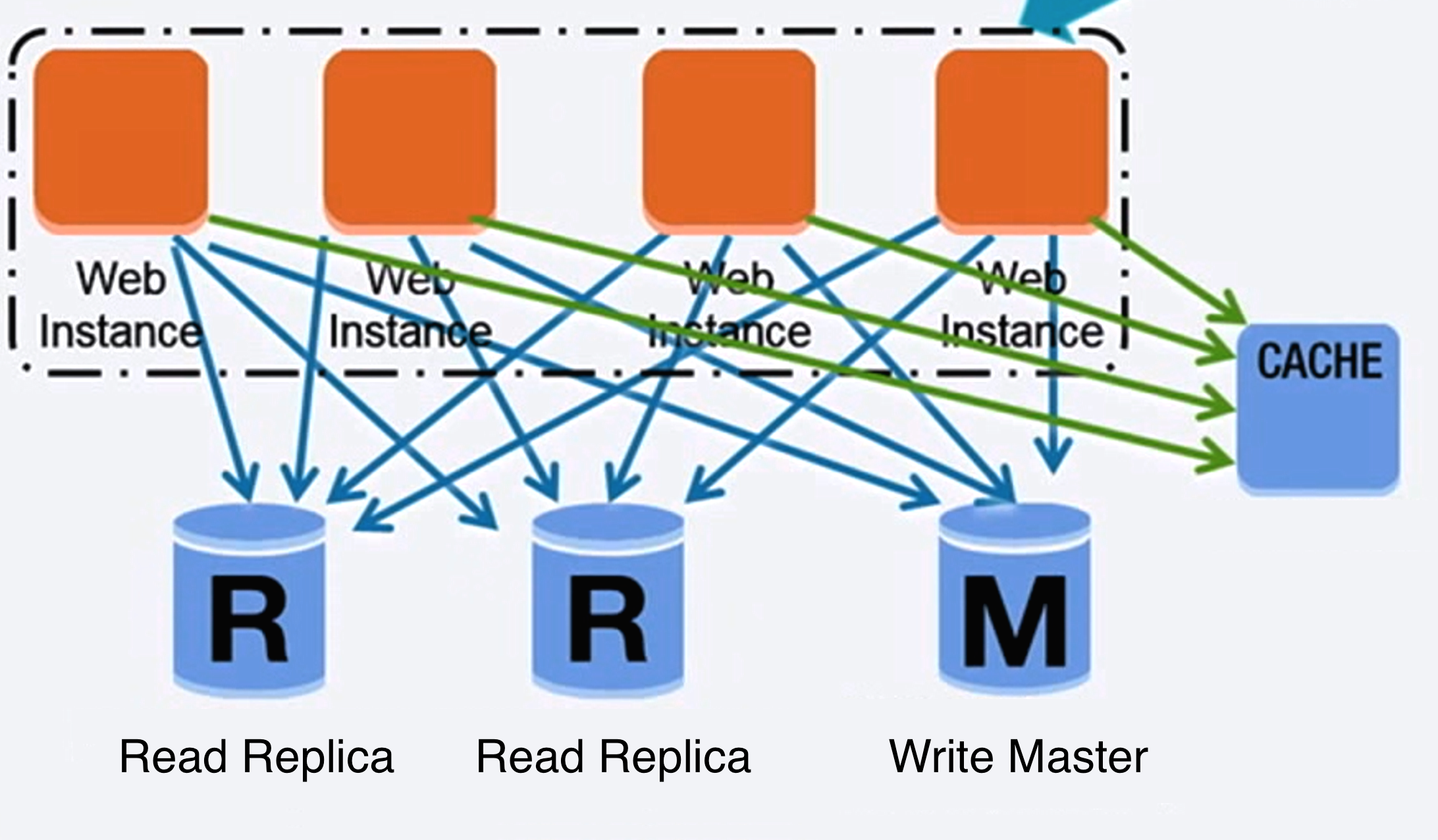
Sumber: Meningkatkan hingga 10 juta pengguna pertama Anda
Basis data relasional seperti SQL adalah kumpulan item data yang disusun dalam tabel.
ACID adalah sekumpulan properti transaksi database relasional.
Ada banyak teknik untuk menskalakan database relasional: replikasi master-slave , replikasi master-master , federasi , sharding , denormalisasi , dan penyetelan SQL .
Master melayani membaca dan menulis, mereplikasi penulisan ke satu atau lebih budak, yang hanya melayani membaca. Budak juga dapat mereplikasi ke budak tambahan dengan cara seperti pohon. Jika master offline, sistem dapat terus beroperasi dalam mode baca-saja hingga budak dipromosikan menjadi master atau master baru disediakan.
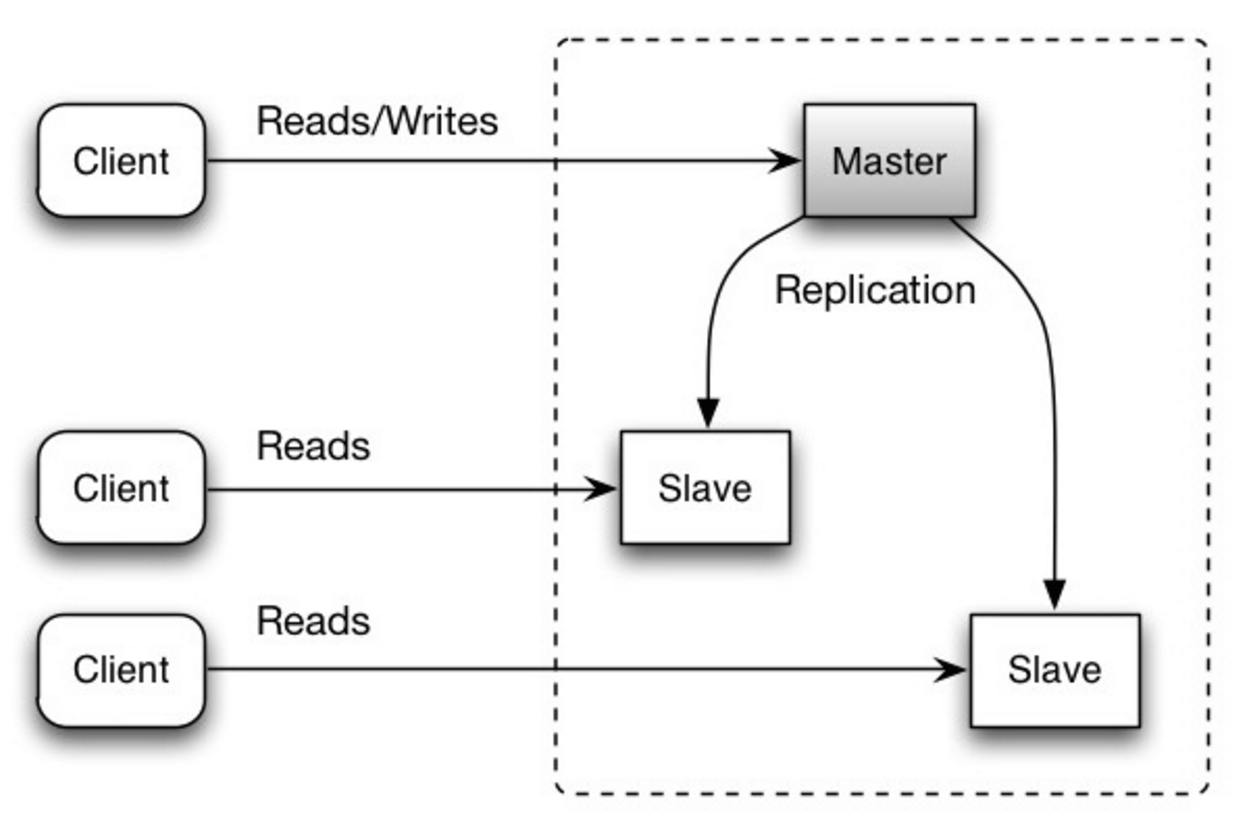
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
Kedua master melayani membaca dan menulis serta saling berkoordinasi dalam penulisan. Jika salah satu master mati, sistem dapat terus beroperasi dengan membaca dan menulis.
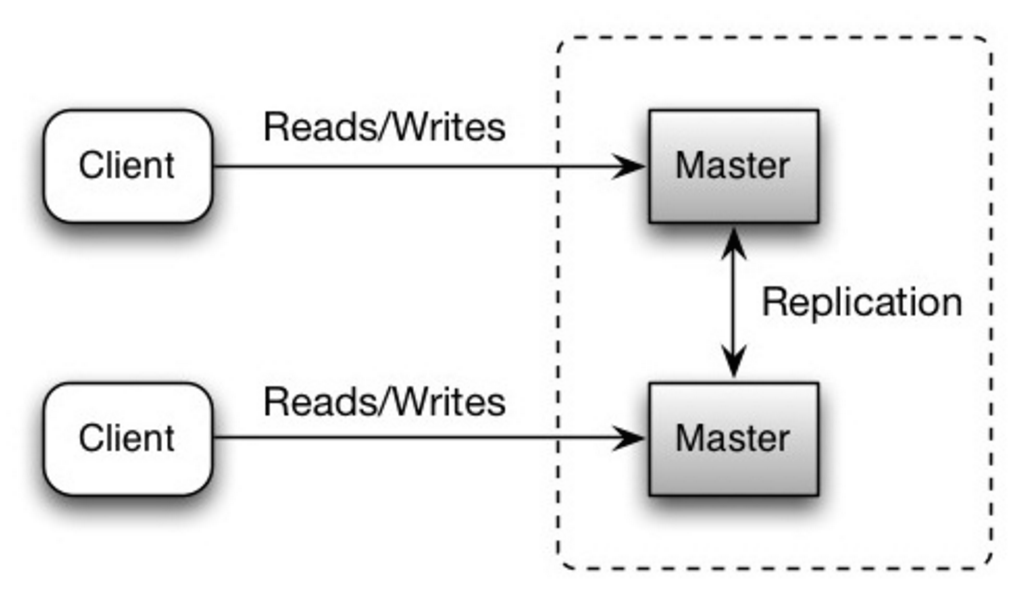
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
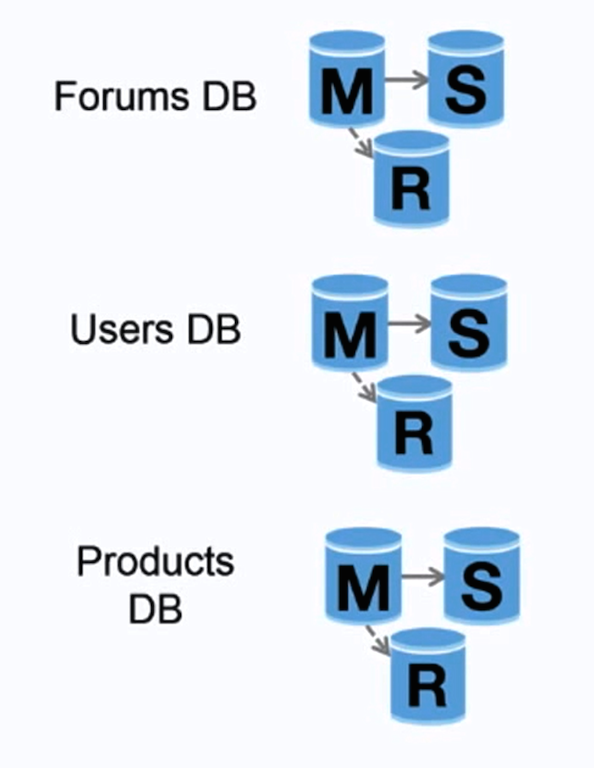
Sumber: Meningkatkan hingga 10 juta pengguna pertama Anda
Federasi (atau partisi fungsional) membagi database berdasarkan fungsinya. Misalnya, alih-alih menggunakan database tunggal yang monolitik, Anda dapat memiliki tiga database: forums , pengguna , dan produk , sehingga mengurangi lalu lintas baca dan tulis ke setiap database sehingga mengurangi kelambatan replikasi. Basis data yang lebih kecil menghasilkan lebih banyak data yang dapat ditampung dalam memori, yang pada gilirannya menghasilkan lebih banyak cache yang ditemukan karena peningkatan lokalitas cache. Tanpa satu pun penulisan serialisasi master pusat, Anda dapat menulis secara paralel, sehingga meningkatkan throughput.
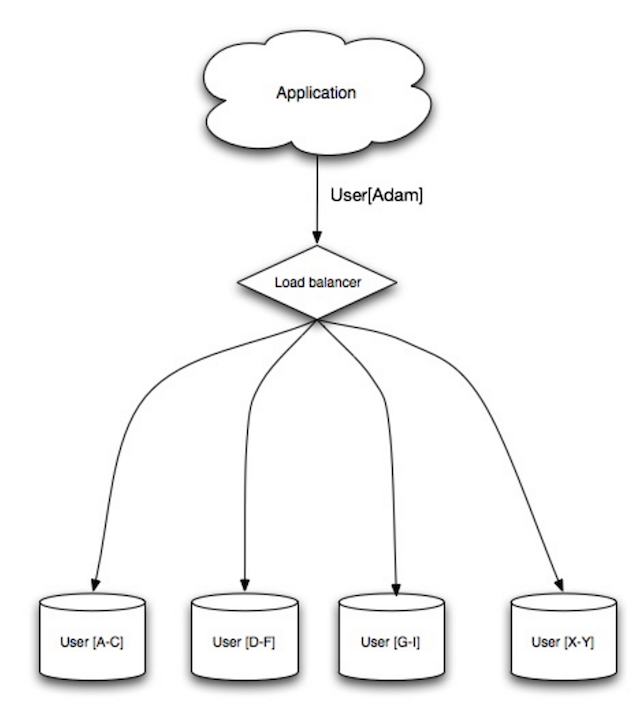
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
Sharding mendistribusikan data ke berbagai database berbeda sehingga setiap database hanya dapat mengelola sebagian data. Mengambil database pengguna sebagai contoh, seiring bertambahnya jumlah pengguna, semakin banyak pecahan yang ditambahkan ke klaster.
Mirip dengan keuntungan federasi, sharding menghasilkan lebih sedikit lalu lintas baca dan tulis, lebih sedikit replikasi, dan lebih banyak cache yang ditemukan. Ukuran indeks juga berkurang, yang umumnya meningkatkan kinerja dengan kueri yang lebih cepat. Jika satu shard rusak, shard lainnya masih beroperasi, meskipun Anda perlu menambahkan beberapa bentuk replikasi untuk menghindari kehilangan data. Seperti federasi, tidak ada satu pun penulisan serialisasi master pusat, yang memungkinkan Anda menulis secara paralel dengan peningkatan throughput.
Cara umum untuk melakukan sharding pada tabel pengguna adalah melalui inisial nama belakang pengguna atau lokasi geografis pengguna.
Denormalisasi berupaya meningkatkan kinerja baca dengan mengorbankan beberapa kinerja menulis. Salinan data yang berlebihan ditulis dalam beberapa tabel untuk menghindari gabungan mahal. Beberapa RDBM seperti PostgreSQL dan Oracle Support terwujud yang menangani pekerjaan menyimpan informasi yang berlebihan dan menjaga salinan berlebihan konsisten.
Setelah data didistribusikan dengan teknik seperti federasi dan sharding, mengelola gabungan di seluruh pusat data lebih lanjut meningkatkan kompleksitas. Denormalisasi mungkin menghindari kebutuhan akan gabungan kompleks seperti itu.
Di sebagian besar sistem, bacaan dapat lebih banyak daripada menulis 100: 1 atau bahkan 1000: 1. Bacaan yang menghasilkan gabungan database yang kompleks bisa sangat mahal, menghabiskan banyak waktu untuk operasi disk.
Tuning SQL adalah topik yang luas dan banyak buku telah ditulis sebagai referensi.
Penting untuk membandingkan dan profil untuk mensimulasikan dan mengungkap kemacetan.
Benchmarking dan profile mungkin mengarahkan Anda ke optimisasi berikut.
CHAR bukannya VARCHAR untuk bidang panjang tetap.CHAR secara efektif memungkinkan akses acak yang cepat dan acak, sedangkan dengan VARCHAR , Anda harus menemukan ujung string sebelum pindah ke yang berikutnya.TEXT untuk blok teks besar seperti posting blog. TEXT juga memungkinkan pencarian boolean. Menggunakan bidang TEXT hasil dalam menyimpan pointer pada disk yang digunakan untuk menemukan blok teks.INT untuk angka yang lebih besar hingga 2^32 atau 4 miliar.DECIMAL untuk mata uang untuk menghindari kesalahan representasi titik mengambang.BLOBS besar, simpan lokasi di mana untuk mendapatkan objek sebagai gantinya.VARCHAR(255) adalah jumlah karakter terbesar yang dapat dihitung dalam angka 8 bit, sering memaksimalkan penggunaan byte dalam beberapa RDBM.NOT NULL jika berlaku untuk meningkatkan kinerja pencarian. SELECT , GROUP BY , ORDER BY , JOIN ) bisa lebih cepat dengan indeks.NoSQL adalah kumpulan item data yang diwakili dalam penyimpanan nilai kunci , toko dokumen , toko kolom lebar , atau basis data grafik . Data didenormalisasi, dan gabungan umumnya dilakukan dalam kode aplikasi. Sebagian besar toko NoSQL tidak memiliki transaksi asam yang sebenarnya dan mendukung konsistensi akhirnya.
Basis sering digunakan untuk menggambarkan sifat -sifat database NoSQL. Dibandingkan dengan teorema CAP, Base memilih ketersediaan daripada konsistensi.
Selain memilih antara SQL atau NoSQL, akan sangat membantu untuk memahami jenis basis data NoSQL mana yang paling sesuai dengan kasus penggunaan Anda. Kami akan meninjau toko-toko nilai kunci , toko dokumen , toko kolom lebar , dan basis data grafik di bagian berikutnya.
Abstraksi: Tabel Hash
Toko nilai kunci umumnya memungkinkan untuk O (1) membaca dan menulis dan sering didukung oleh memori atau SSD. Simpan data dapat mempertahankan kunci dalam urutan leksikografi, memungkinkan pengambilan rentang kunci yang efisien. Toko-toko bernilai kunci dapat memungkinkan untuk menyimpan metadata dengan nilai.
Penyimpanan value kunci memberikan kinerja tinggi dan sering digunakan untuk model data sederhana atau untuk data yang berubah dengan cepat, seperti lapisan cache dalam memori. Karena mereka hanya menawarkan satu set operasi terbatas, kompleksitas digeser ke lapisan aplikasi jika diperlukan operasi tambahan.
Toko nilai kunci adalah dasar untuk sistem yang lebih kompleks seperti toko dokumen, dan dalam beberapa kasus, database grafik.
Abstraksi: Toko Nilai Kunci dengan dokumen yang disimpan sebagai nilai
Toko dokumen berpusat di sekitar dokumen (XML, JSON, biner, dll), di mana dokumen menyimpan semua informasi untuk objek yang diberikan. Toko dokumen menyediakan API atau bahasa kueri untuk permintaan berdasarkan struktur internal dokumen itu sendiri. Catatan, banyak toko nilai kunci termasuk fitur untuk bekerja dengan metadata nilai, mengaburkan garis antara kedua jenis penyimpanan ini.
Berdasarkan implementasi yang mendasarinya, dokumen disusun oleh koleksi, tag, metadata, atau direktori. Meskipun dokumen dapat diatur atau dikelompokkan bersama, dokumen mungkin memiliki bidang yang sama sekali berbeda satu sama lain.
Beberapa toko dokumen seperti MongoDB dan CouchDB juga menyediakan bahasa seperti SQL untuk melakukan pertanyaan yang kompleks. DynamoDB mendukung nilai-nilai kunci dan dokumen.
Toko dokumen memberikan fleksibilitas tinggi dan sering digunakan untuk bekerja dengan data yang kadang -kadang mengubah.
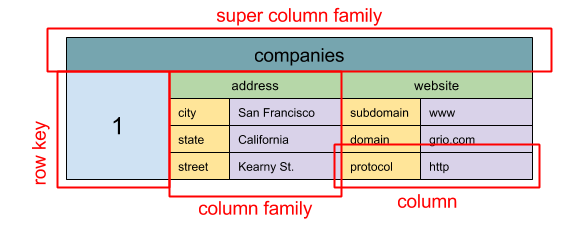
Sumber: SQL & NoSQL, Sejarah Singkat
Abstraksi:
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
Unit Data Dasar Toko Kolom Lebar adalah kolom (Name/Value Pair). Kolom dapat dikelompokkan dalam keluarga kolom (analog dengan tabel SQL). Keluarga Kolom Super lebih lanjut Keluarga Kelompok Kolom. Anda dapat mengakses setiap kolom secara independen dengan kunci baris, dan kolom dengan kunci baris yang sama membentuk baris. Setiap nilai berisi cap waktu untuk versi dan untuk resolusi konflik.
Google memperkenalkan BigTable sebagai toko kolom lebar pertama, yang memengaruhi HBase open-source yang sering digunakan di ekosistem Hadoop, dan Cassandra dari Facebook. Toko -toko seperti BigTable, HBase, dan Cassandra mempertahankan kunci dalam urutan leksikografi, memungkinkan pengambilan rentang kunci selektif yang efisien.
Toko kolom lebar menawarkan ketersediaan tinggi dan skalabilitas tinggi. Mereka sering digunakan untuk set data yang sangat besar.
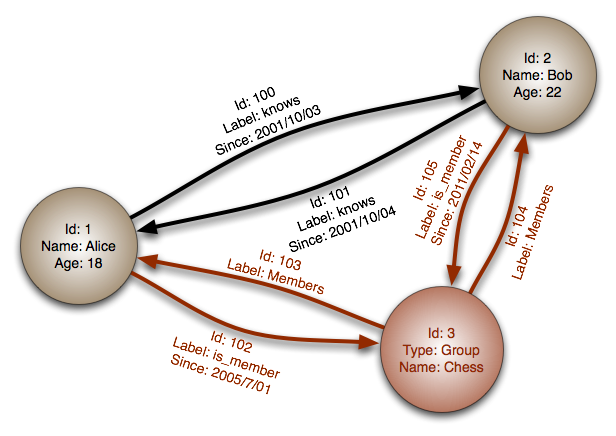
Sumber: Basis Data Grafik
Abstraksi: Grafik
Dalam database grafik, setiap node adalah catatan dan masing -masing busur adalah hubungan antara dua node. Basis data grafik dioptimalkan untuk mewakili hubungan yang kompleks dengan banyak kunci asing atau banyak hubungan.
Basis data grafik menawarkan kinerja tinggi untuk model data dengan hubungan yang kompleks, seperti jejaring sosial. Mereka relatif baru dan belum banyak digunakan; Mungkin lebih sulit untuk menemukan alat dan sumber daya pengembangan. Banyak grafik hanya dapat diakses dengan API REST.
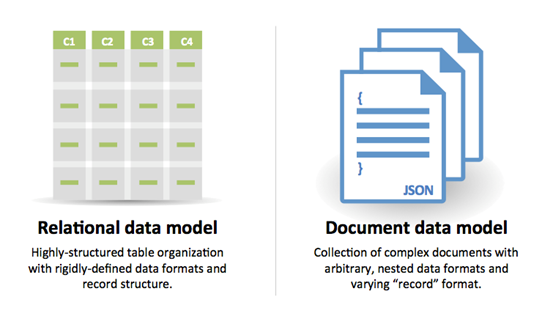
Sumber: Transisi dari RDBM ke NoSQL
Alasan SQL :
Alasan NoSQL :
Data sampel yang cocok untuk NoSQL:
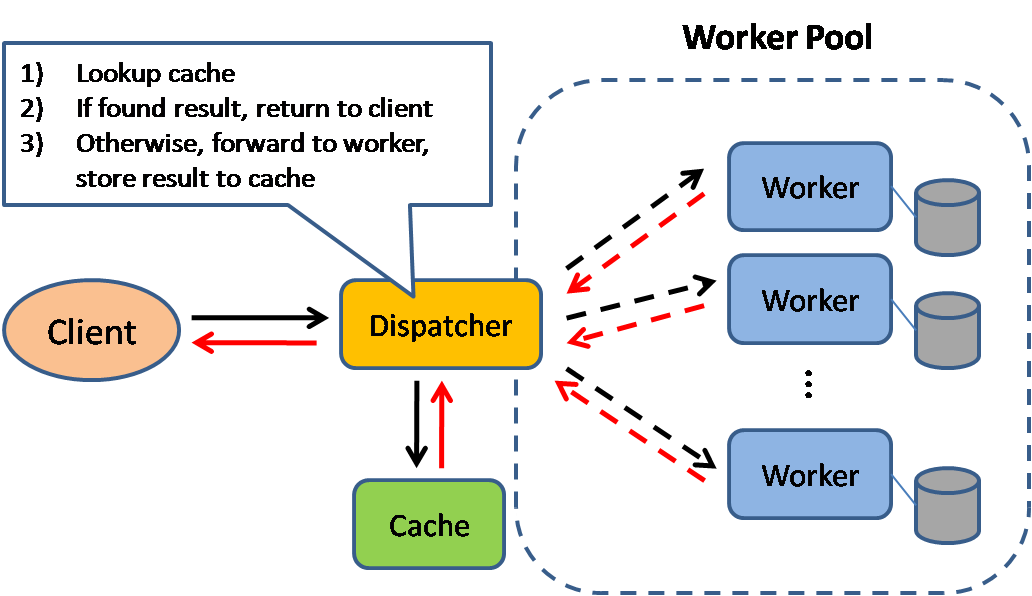
Sumber: Pola Desain Sistem yang Dapat Diukur
Caching meningkatkan waktu pemuatan halaman dan dapat mengurangi beban pada server dan database Anda. Dalam model ini, dispatcher pertama -tama akan mencari jika permintaan telah dibuat sebelumnya dan mencoba menemukan hasil sebelumnya untuk kembali, untuk menyimpan eksekusi yang sebenarnya.
Basis data sering mendapat manfaat dari distribusi bacaan yang seragam dan menulis di seluruh partisi. Barang -barang populer dapat memiringkan distribusi, menyebabkan kemacetan. Menempatkan cache di depan basis data dapat membantu menyerap beban yang tidak merata dan lonjakan lalu lintas.
Cache dapat ditempatkan di sisi klien (OS atau browser), sisi server, atau di lapisan cache yang berbeda.
CDN dianggap sebagai jenis cache.
Proksi dan cache terbalik seperti pernis dapat melayani konten statis dan dinamis secara langsung. Server Web juga dapat men -cache permintaan, mengembalikan tanggapan tanpa harus menghubungi server aplikasi.
Basis data Anda biasanya mencakup beberapa tingkat caching dalam konfigurasi default, dioptimalkan untuk kasing umum. Mengubah pengaturan ini untuk pola penggunaan tertentu dapat meningkatkan kinerja.
Caches dalam memori seperti memcached dan redis adalah penyimpanan nilai kunci antara aplikasi Anda dan penyimpanan data Anda. Karena data disimpan dalam RAM, itu jauh lebih cepat daripada database khas di mana data disimpan di disk. RAM lebih terbatas daripada disk, sehingga cache tidak validasi algoritma seperti baru -baru ini yang digunakan (LRU) dapat membantu membatalkan entri 'dingin' dan menyimpan data 'panas' di RAM.
Redis memiliki fitur tambahan berikut:
Ada beberapa tingkatan yang dapat Anda cache yang termasuk dalam dua kategori umum: kueri dan objek basis data:
Secara umum, Anda harus mencoba menghindari caching berbasis file, karena membuat kloning dan penskalaan otomatis lebih sulit.
Setiap kali Anda meminta database, hash kueri sebagai kunci dan simpan hasilnya ke cache. Pendekatan ini menderita masalah kedaluwarsa:
Lihat data Anda sebagai objek, mirip dengan apa yang Anda lakukan dengan kode aplikasi Anda. Mintalah aplikasi Anda merakit dataset dari database menjadi instance kelas atau struktur data:
Saran tentang apa yang harus disimpan:
Karena Anda hanya dapat menyimpan data dalam jumlah terbatas dalam cache, Anda harus menentukan strategi pembaruan cache mana yang paling cocok untuk kasus penggunaan Anda.
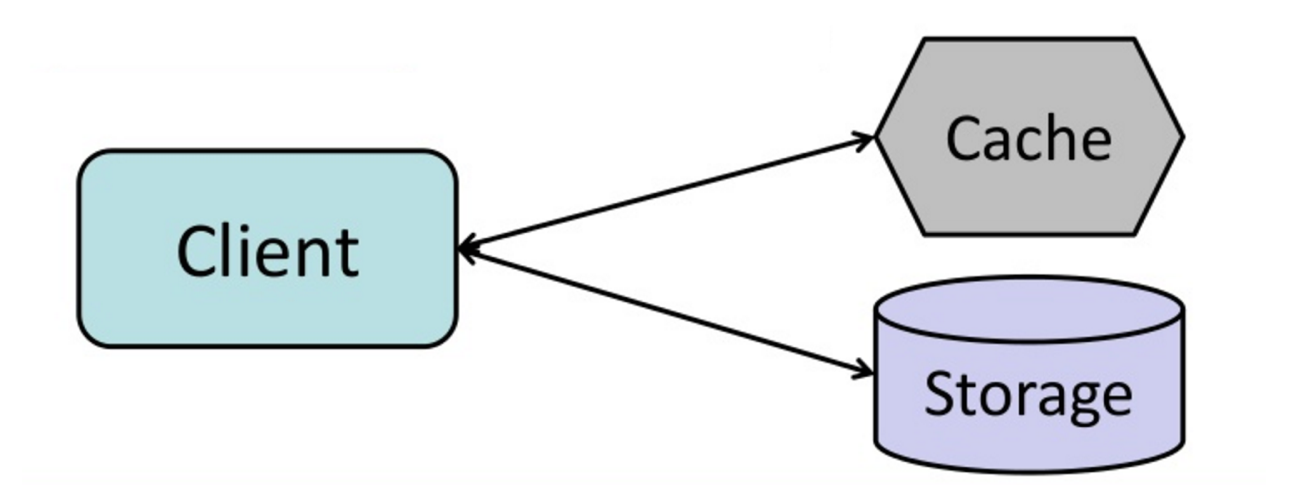
Sumber: Dari cache hingga kisi data dalam memori
Aplikasi ini bertanggung jawab untuk membaca dan menulis dari penyimpanan. Cache tidak berinteraksi dengan penyimpanan secara langsung. Aplikasi melakukan hal berikut:
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return userMemcached umumnya digunakan dengan cara ini.
Bacaan data berikutnya yang ditambahkan ke cache cepat. Cache-aside juga disebut sebagai pemuatan malas. Hanya data yang diminta di -cache, yang menghindari mengisi cache dengan data yang tidak diminta.
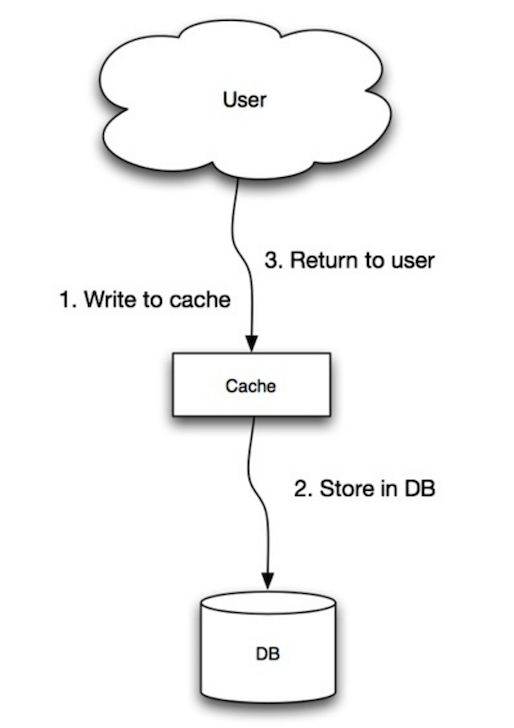
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
Aplikasi menggunakan cache sebagai penyimpanan data utama, membaca dan menulis data untuk itu, sementara cache bertanggung jawab untuk membaca dan menulis ke database:
Kode aplikasi:
set_user ( 12345 , { "foo" : "bar" })Kode cache:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )Write-Through adalah operasi keseluruhan yang lambat karena operasi tulis, tetapi bacaan data tertulis yang hanya cepat. Pengguna umumnya lebih toleran terhadap latensi saat memperbarui data daripada membaca data. Data dalam cache tidak basi.
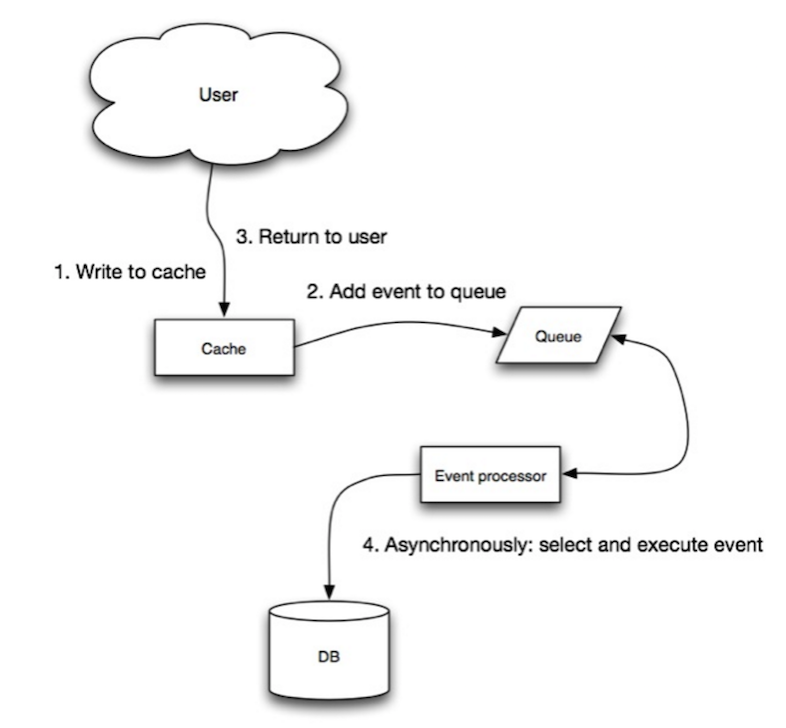
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
Di B-Behind, aplikasi melakukan hal berikut:
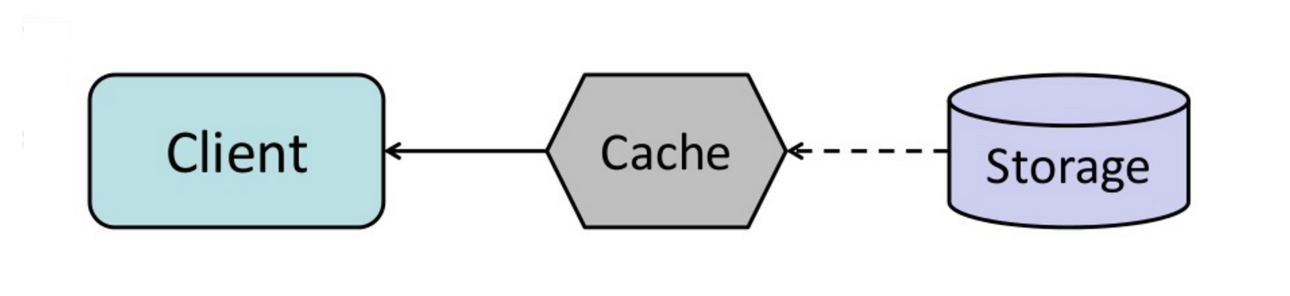
Sumber: Dari cache hingga kisi data dalam memori
Anda dapat mengonfigurasi cache untuk secara otomatis menyegarkan entri cache yang baru diakses sebelum kedaluwarsa.
Refresh-Aahad dapat mengakibatkan pengurangan latensi vs membaca-melalui jika cache dapat secara akurat memprediksi item mana yang mungkin diperlukan di masa depan.
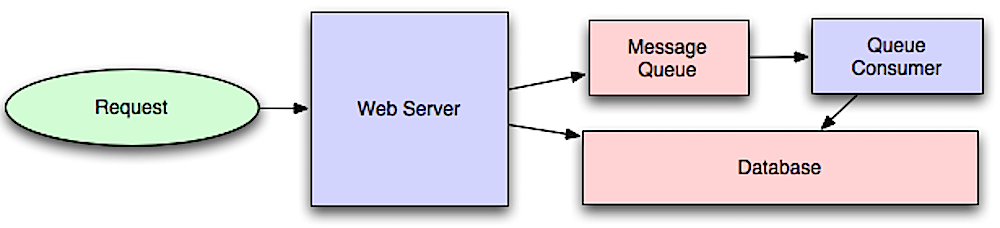
Sumber: Intro to Architecting Systems for Scale
Alur kerja asinkron membantu mengurangi waktu permintaan untuk operasi mahal yang seharusnya dilakukan sejalan. Mereka juga dapat membantu dengan melakukan pekerjaan yang memakan waktu terlebih dahulu, seperti agregasi data berkala.
Antrian pesan menerima, menahan, dan mengirimkan pesan. Jika suatu operasi terlalu lambat untuk melakukan inline, Anda dapat menggunakan antrian pesan dengan alur kerja berikut:
Pengguna tidak diblokir dan pekerjaan diproses di latar belakang. Selama waktu ini, klien mungkin secara opsional melakukan sejumlah kecil pemrosesan untuk membuatnya tampak seperti tugas telah selesai. Misalnya, jika memposting tweet, tweet dapat langsung diposting ke timeline Anda, tetapi itu bisa memakan waktu sebelum tweet Anda sebenarnya dikirimkan ke semua pengikut Anda.
Redis berguna sebagai broker pesan sederhana tetapi pesan bisa hilang.
RabbitMQ populer tetapi mengharuskan Anda beradaptasi dengan protokol 'AMQP' dan mengelola node Anda sendiri.
Amazon SQS di -host tetapi dapat memiliki latensi tinggi dan memiliki kemungkinan pesan yang dikirimkan dua kali.
Tugas antrian menerima tugas dan data terkait mereka, menjalankannya, kemudian memberikan hasilnya. Mereka dapat mendukung penjadwalan dan dapat digunakan untuk menjalankan pekerjaan yang intensif secara komputasi di latar belakang.
Celery memiliki dukungan untuk penjadwalan dan terutama memiliki dukungan python.
Jika antrian mulai tumbuh secara signifikan, ukuran antrian dapat menjadi lebih besar dari memori, menghasilkan cache miss, disk membaca, dan bahkan kinerja yang lebih lambat. Tekanan punggung dapat membantu dengan membatasi ukuran antrian, sehingga mempertahankan laju throughput yang tinggi dan waktu respons yang baik untuk pekerjaan yang sudah ada dalam antrian. Setelah antrian terisi, klien mendapatkan server sibuk atau kode status HTTP 503 untuk dicoba lagi nanti. Klien dapat mencoba lagi permintaan di lain waktu, mungkin dengan backoff eksponensial.
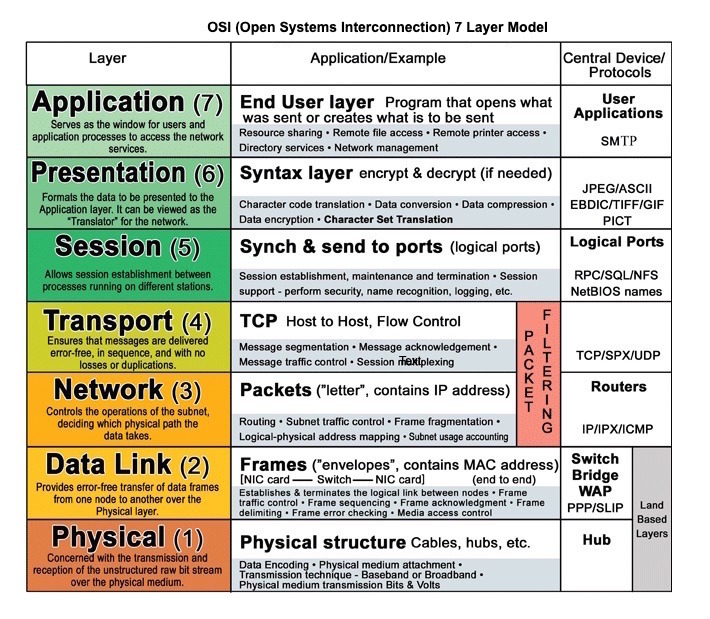
Sumber: OSI 7 Layer Model
HTTP adalah metode untuk mengkode dan mengangkut data antara klien dan server. Ini adalah protokol permintaan/respons: klien mengeluarkan permintaan dan server menerbitkan tanggapan dengan konten yang relevan dan info status penyelesaian tentang permintaan tersebut. HTTP mandiri, memungkinkan permintaan dan respons mengalir melalui banyak router dan server menengah yang melakukan penyeimbangan beban, caching, enkripsi, dan kompresi.
Permintaan HTTP dasar terdiri dari kata kerja (metode) dan sumber daya (titik akhir). Di bawah ini adalah kata kerja http umum:
| Kata kerja | Keterangan | Idempotent* | Aman | Dapat di-cache |
|---|---|---|---|---|
| MENDAPATKAN | Membaca sumber daya | Ya | Ya | Ya |
| POS | Membuat sumber daya atau memicu proses yang menangani data | TIDAK | TIDAK | Ya jika respons berisi info kesegaran |
| MELETAKKAN | Membuat atau mengganti sumber daya | Ya | TIDAK | TIDAK |
| tambalan | Sebagian memperbarui sumber daya | TIDAK | TIDAK | Ya jika respons berisi info kesegaran |
| MENGHAPUS | Menghapus sumber daya | Ya | TIDAK | TIDAK |
*Dapat disebut berkali -kali tanpa hasil yang berbeda.
HTTP adalah protokol lapisan aplikasi yang mengandalkan protokol tingkat bawah seperti TCP dan UDP .
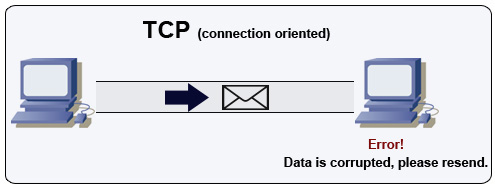
Sumber: Cara Membuat Game Multiplayer
TCP adalah protokol berorientasi koneksi melalui jaringan IP. Koneksi dibuat dan diakhiri dengan menggunakan jabat tangan. Semua paket yang dikirim dijamin akan mencapai tujuan dalam urutan asli dan tanpa korupsi melalui:
Jika pengirim tidak menerima respons yang benar, itu akan mengirimkan kembali paket. Jika ada beberapa batas waktu, koneksi dijatuhkan. TCP juga mengimplementasikan kontrol aliran dan kontrol kemacetan. Jaminan ini menyebabkan penundaan dan umumnya menghasilkan transmisi yang kurang efisien daripada UDP.
Untuk memastikan throughput yang tinggi, server web dapat membuka sejumlah besar koneksi TCP, menghasilkan penggunaan memori yang tinggi. Mungkin mahal untuk memiliki sejumlah besar koneksi terbuka antara utas server web dan katakanlah, server memcached. Pooling koneksi dapat membantu selain beralih ke UDP jika berlaku.
TCP berguna untuk aplikasi yang membutuhkan keandalan tinggi tetapi kurang kritis waktu. Beberapa contoh termasuk server web, info basis data, SMTP, FTP, dan SSH.
Gunakan TCP melalui UDP saat:
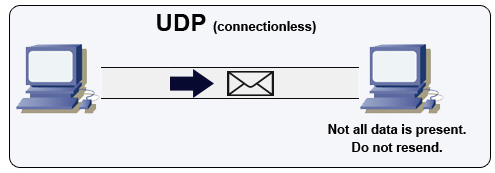
Sumber: Cara Membuat Game Multiplayer
UDP tanpa koneksi. Datagram (analog dengan paket) dijamin hanya pada level datagram. Datagram mungkin mencapai tujuan mereka rusak atau tidak sama sekali. UDP tidak mendukung kontrol kemacetan. Tanpa jaminan bahwa dukungan TCP, UDP umumnya lebih efisien.
UDP dapat menyiarkan, mengirim datagram ke semua perangkat di subnet. Ini berguna dengan DHCP karena klien belum menerima alamat IP, sehingga mencegah cara agar TCP streaming tanpa alamat IP.
UDP kurang dapat diandalkan tetapi bekerja dengan baik dalam kasus penggunaan waktu nyata seperti VoIP, obrolan video, streaming, dan game multipemain realtime.
Gunakan UDP melalui TCP saat:
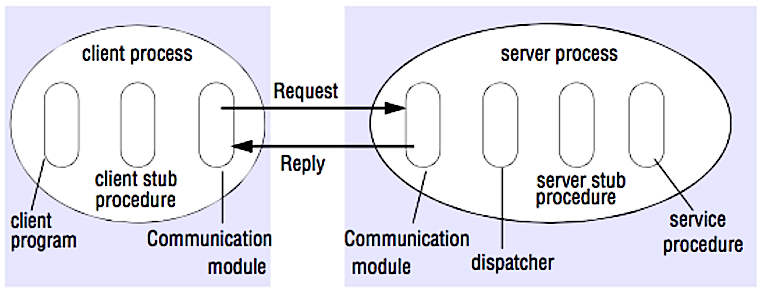
Sumber: Retak wawancara desain sistem
Dalam RPC, klien menyebabkan prosedur untuk dieksekusi pada ruang alamat yang berbeda, biasanya server jarak jauh. Prosedur ini diberi kode seolah -olah itu adalah panggilan prosedur lokal, mengabstraksi rincian cara berkomunikasi dengan server dari program klien. Panggilan jarak jauh biasanya lebih lambat dan kurang dapat diandalkan daripada panggilan lokal sehingga sangat membantu untuk membedakan panggilan RPC dari panggilan lokal. Kerangka kerja RPC yang populer termasuk Protobuf, Thrift, dan Avro.
RPC adalah protokol permintaan-respons:
Contoh Panggilan RPC:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC difokuskan pada mengekspos perilaku. RPC sering digunakan untuk alasan kinerja dengan komunikasi internal, karena Anda dapat menjajakan panggilan asli agar lebih sesuai dengan kasus penggunaan Anda.
Pilih Perpustakaan Asli (alias SDK) Kapan:
HTTP API berikut istirahat cenderung lebih sering digunakan untuk API publik.
REST adalah gaya arsitektur yang menegakkan model klien/server di mana klien bertindak pada serangkaian sumber daya yang dikelola oleh server. Server menyediakan representasi sumber daya dan tindakan yang dapat memanipulasi atau mendapatkan representasi sumber daya baru. Semua komunikasi harus tanpa kewarganegaraan dan dapat di -cache.
Ada empat kualitas antarmuka yang tenang:
Contoh panggilan istirahat:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
Istirahat difokuskan pada mengekspos data. Ini meminimalkan kopling antara klien/server dan sering digunakan untuk HTTP API publik. REST menggunakan metode yang lebih umum dan seragam untuk mengekspos sumber daya melalui URI, representasi melalui header, dan tindakan melalui kata kerja seperti GET, POST, POS, DELETE, dan PATCH. Menjadi kewarganegaraan, istirahat sangat bagus untuk penskalaan dan partisi horizontal.
| Operasi | RPC | ISTIRAHAT |
|---|---|---|
| Mendaftar | Posting /Daftar | Posting /Orang |
| Berhenti | Posting /mengundurkan diri { "personid": "1234" } | Hapus /orang /1234 |
| Baca seseorang | Dapatkan /Readperson? PersonID = 1234 | Dapatkan /Orang /1234 |
| Baca daftar item seseorang | Get /ReadUserSitemSlist? PersonID = 1234 | Dapatkan /orang/1234/item |
| Tambahkan item ke item seseorang | POST /ADDITEMTOUSITITEMSLIST { "personid": "1234"; "ItemId": "456" } | Pos /Orang/1234/Item { "ItemId": "456" } |
| Perbarui item | POST /MODIFYITEM { "ItemId": "456"; "kunci": "nilai" } | Put /item /456 { "kunci": "nilai" } |
| Hapus item | POST /REMPATI { "ItemId": "456" } | Hapus /item /456 |
Sumber: Apakah Anda benar -benar tahu mengapa Anda lebih suka istirahat daripada RPC
Bagian ini dapat menggunakan beberapa pembaruan. Pertimbangkan berkontribusi!
Keamanan adalah topik yang luas. Kecuali Anda memiliki pengalaman yang cukup besar, latar belakang keamanan, atau melamar posisi yang membutuhkan pengetahuan keamanan, Anda mungkin tidak perlu tahu lebih dari dasar -dasarnya:
Kadang-kadang Anda akan diminta untuk melakukan perkiraan 'di belakang envelope'. Misalnya, Anda mungkin perlu menentukan berapa lama waktu yang dibutuhkan untuk menghasilkan 100 thumbnail gambar dari disk atau berapa banyak memori yang akan dibutuhkan oleh struktur data. Kekuatan dua tabel dan nomor latensi yang harus diketahui oleh setiap programmer adalah referensi yang praktis.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Metrik praktis berdasarkan angka di atas:
Pertanyaan wawancara desain sistem umum, dengan tautan ke sumber daya tentang cara menyelesaikan masing -masing.
| Pertanyaan | Referensi |
|---|---|
| Desain Layanan Sinkronisasi File Seperti Dropbox | youtube.com |
| Desain mesin pencari seperti google | Queue.acm.org stackexchange.com ardendertat.com stanford.edu |
| Desain crawler web yang dapat diskalakan seperti google | quora.com |
| Desain Google Documents | code.google.com neil.fraser.name |
| Rancang toko bernilai kunci seperti Redis | slideshare.net |
| Merancang sistem cache seperti memcached | slideshare.net |
| Rancang sistem rekomendasi seperti Amazon | hulu.com ijcai13.org |
| Rancang sistem tinyurl seperti bitly | n00tc0d3r.blogspot.com |
| Desain aplikasi obrolan seperti whatsapp | highscalability.com |
| Rancang sistem berbagi gambar seperti Instagram | highscalability.com highscalability.com |
| Rancang Fungsi Umpan Berita Facebook | quora.com quora.com slideshare.net |
| Rancang fungsi timeline Facebook | facebook.com highscalability.com |
| Desain fungsi obrolan Facebook | erlang-factory.com facebook.com |
| Desain fungsi pencarian grafik seperti Facebook | facebook.com facebook.com facebook.com |
| Desain jaringan pengiriman konten seperti cloudflare | figshare.com |
| Rancang sistem topik yang sedang tren seperti Twitter | michael-noll.com snikolov .wordpress.com |
| Rancang sistem pembuatan ID acak | blog.twitter.com github.com |
| Mengembalikan permintaan k teratas selama interval waktu | cs.ucsb.edu wpi.edu |
| Rancang sistem yang melayani data dari beberapa pusat data | highscalability.com |
| Desain game kartu multipemain online | indieflashblog.com buildnewgames.com |
| Rancang sistem pengumpulan sampah | stuffwithstuff.com Washington.edu |
| Merancang pembatas tingkat API | https://stripe.com/blog/ |
| Desain Bursa Efek (seperti Nasdaq atau Binance) | Jalan Jane Implementasi Golang Implementasi GO |
| Tambahkan pertanyaan desain sistem | Menyumbang |
Artikel tentang bagaimana sistem dunia nyata dirancang.
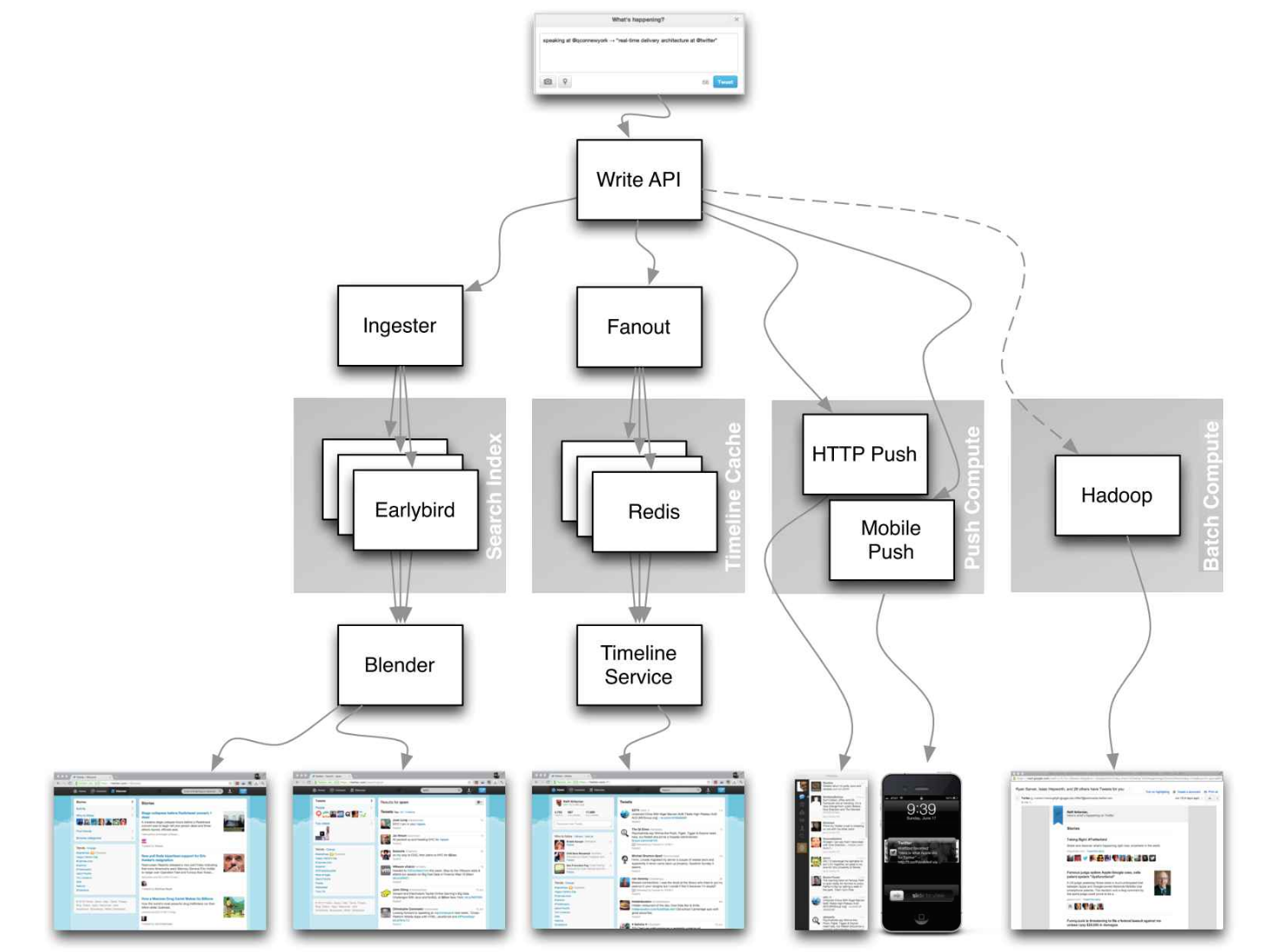
Sumber: Garis Waktu Twitter pada Skala
Jangan fokus pada detail seluk beluk untuk artikel -artikel berikut, sebagai gantinya:
| Jenis | Sistem | Referensi |
|---|---|---|
| Pengolahan data | MapReduce - Pemrosesan Data Terdistribusi dari Google | riset.google.com |
| Pengolahan data | Spark - Pemrosesan Data Terdistribusi dari Databricks | slideshare.net |
| Pengolahan data | Storm - Pemrosesan Data Terdistribusi dari Twitter | slideshare.net |
| Penyimpanan data | BigTable - Database Berorientasi Kolom Terdistribusi dari Google | Harvard.edu |
| Penyimpanan data | HBASE - Implementasi Sumber Terbuka BigTable | slideshare.net |
| Penyimpanan data | Cassandra - Database berorientasi kolom terdistribusi dari Facebook | slideshare.net |
| Penyimpanan data | DynamoDB - Database Berorientasi Dokumen dari Amazon | Harvard.edu |
| Penyimpanan data | MongoDB - Database Berorientasi Dokumen | slideshare.net |
| Penyimpanan data | Spanner - Database yang didistribusikan secara global dari Google | riset.google.com |
| Penyimpanan data | Memcached - Sistem caching memori terdistribusi | slideshare.net |
| Penyimpanan data | Redis - Sistem caching memori terdistribusi dengan ketekunan dan jenis nilai | slideshare.net |
| Sistem file | Google File System (GFS) - Sistem File Terdistribusi | riset.google.com |
| Sistem file | Hadoop File System (HDFS) - Implementasi Sumber Terbuka dari GFS | Apache.org |
| Lain-lain | Chubby - Layanan kunci untuk sistem terdistribusi yang dipasangkan secara longgar dari google | riset.google.com |
| Lain-lain | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Lain-lain | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| Lain-lain | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Menyumbang |
| Perusahaan | Referensi |
|---|---|
| Amazon | Amazon architecture |
| Cinchcast | Producing 1,500 hours of audio every day |
| DataSift | Realtime datamining At 120,000 tweets per second |
| Dropbox | How we've scaled Dropbox |
| ESPN | Operating At 100,000 duh nuh nuhs per second |
| Google architecture | |
| 14 million users, terabytes of photos What powers Instagram | |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers | |
| Flickr | Flickr architecture |
| Kotak surat | From 0 to one million users in 6 weeks |
| Netflix | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees | |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| Salesforce | How they handle 1.3 billion transactions a day |
| Stack Overflow | Stack Overflow architecture |
| TripAdvisor | 40M visitors, 200M dynamic page views, 30TB data |
| Tumblr | 15 billion page views a month |
| Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second | |
| uber | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| Ada apa | The WhatsApp architecture Facebook bought for $19 billion |
| YouTube | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? Menyumbang!
Credits and sources are provided throughout this repo.
Special thanks to:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


