textgenrnn
T
Latih jaringan saraf penghasil teks Anda sendiri dengan mudah dengan berbagai ukuran dan kompleksitas pada kumpulan data teks apa pun dengan beberapa baris kode, atau latih teks dengan cepat menggunakan model yang telah dilatih sebelumnya.
textgenrnn adalah modul Python 3 di atas Keras/TensorFlow untuk membuat char-rnns, dengan banyak fitur keren:
Anda dapat bermain dengan textgenrnn dan melatih file teks apa pun dengan GPU secara gratis di Notebook Kolaborasi ini! Baca postingan blog ini atau tonton video ini untuk informasi lebih lanjut!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
Model yang disertakan dapat dengan mudah dilatih pada teks baru, dan dapat menghasilkan teks yang sesuai bahkan setelah satu kali input data .
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
Bobot model relatif kecil (2 MB pada disk), dan dapat dengan mudah disimpan dan dimuat ke dalam instance textgenrnn baru. Hasilnya, Anda dapat bermain-main dengan model yang telah dilatih melalui ratusan lintasan data. (sebenarnya, textgenrnn belajar dengan sangat baik sehingga Anda harus meningkatkan suhu secara signifikan untuk hasil kreatif!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
Anda juga dapat melatih model baru, dengan dukungan untuk penyematan tingkat kata dan lapisan RNN dua arah dengan menambahkan new_model=True ke fungsi kereta apa pun.
Dimungkinkan juga untuk terlibat dalam bagaimana hasilnya terungkap, langkah demi langkah. Mode interaktif akan menyarankan Anda N opsi teratas untuk karakter/kata berikutnya, dan memungkinkan Anda memilih salah satu.
Saat menjalankan textgenrnn di terminal, teruskan interactive=True dan top=N untuk generate . N defaultnya adalah 3.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
Ini dapat menambahkan sentuhan manusiawi pada keluarannya; rasanya seperti kamulah penulisnya! (referensi)
textgenrnn dapat diinstal dari pypi melalui pip :
pip3 install textgenrnnUntuk textgenrnn terbaru, Anda harus memiliki versi TensorFlow minimal 2.1.0 .
Anda dapat melihat demo fitur umum dan opsi konfigurasi model di Notebook Jupyter ini.
/datasets berisi contoh kumpulan data menggunakan data Hacker News/Reddit untuk pelatihan textgenrnn.
/weights berisi model yang telah dilatih lebih lanjut pada kumpulan data yang disebutkan di atas yang dapat dimuat ke dalam textgenrnn.
/outputs berisi contoh teks yang dihasilkan dari model terlatih di atas.
textgenrnn didasarkan pada proyek char-rnn oleh Andrej Karpathy dengan beberapa optimasi modern, seperti kemampuan untuk bekerja dengan urutan teks yang sangat kecil.
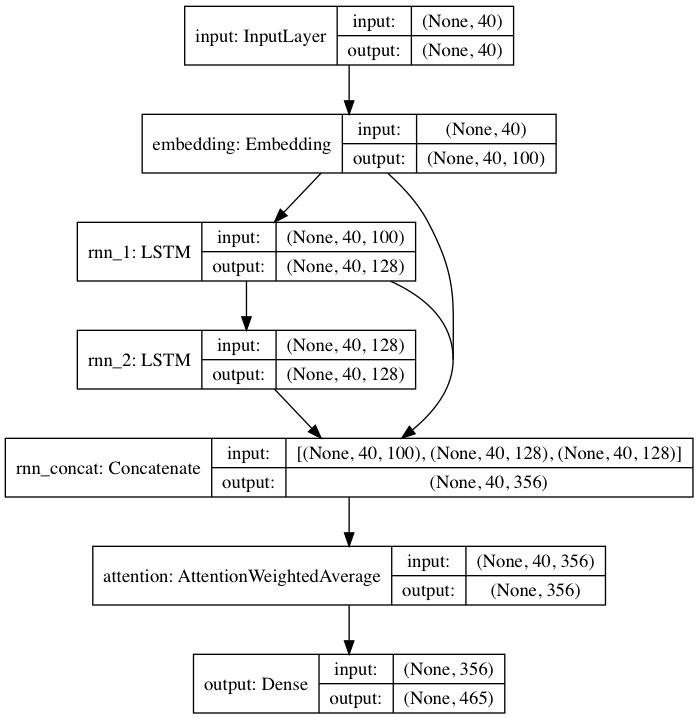
Model terlatih yang disertakan mengikuti arsitektur jaringan saraf yang terinspirasi oleh DeepMoji. Untuk model default, textgenrnn menerima masukan hingga 40 karakter, mengonversi setiap karakter menjadi vektor penyematan karakter 100-D, dan memasukkannya ke dalam lapisan berulang memori jangka pendek (LSTM) 128 sel. Keluaran tersebut kemudian dimasukkan ke LSTM 128 sel lainnya . Ketiga lapisan tersebut kemudian dimasukkan ke dalam lapisan Perhatian untuk memberi bobot pada fitur temporal yang paling penting dan membuat rata-ratanya bersama-sama (dan karena penyematan + LSTM pertama dilompati terhubung ke lapisan perhatian, pembaruan model dapat melakukan propagasi mundur ke fitur tersebut dengan lebih mudah dan mencegah hilangnya gradien). Keluaran tersebut dipetakan ke probabilitas hingga 394 karakter berbeda yang merupakan karakter berikutnya dalam urutan, termasuk karakter huruf besar, huruf kecil, tanda baca, dan emoji. (jika melatih model baru pada kumpulan data baru, semua parameter numerik di atas dapat dikonfigurasi)
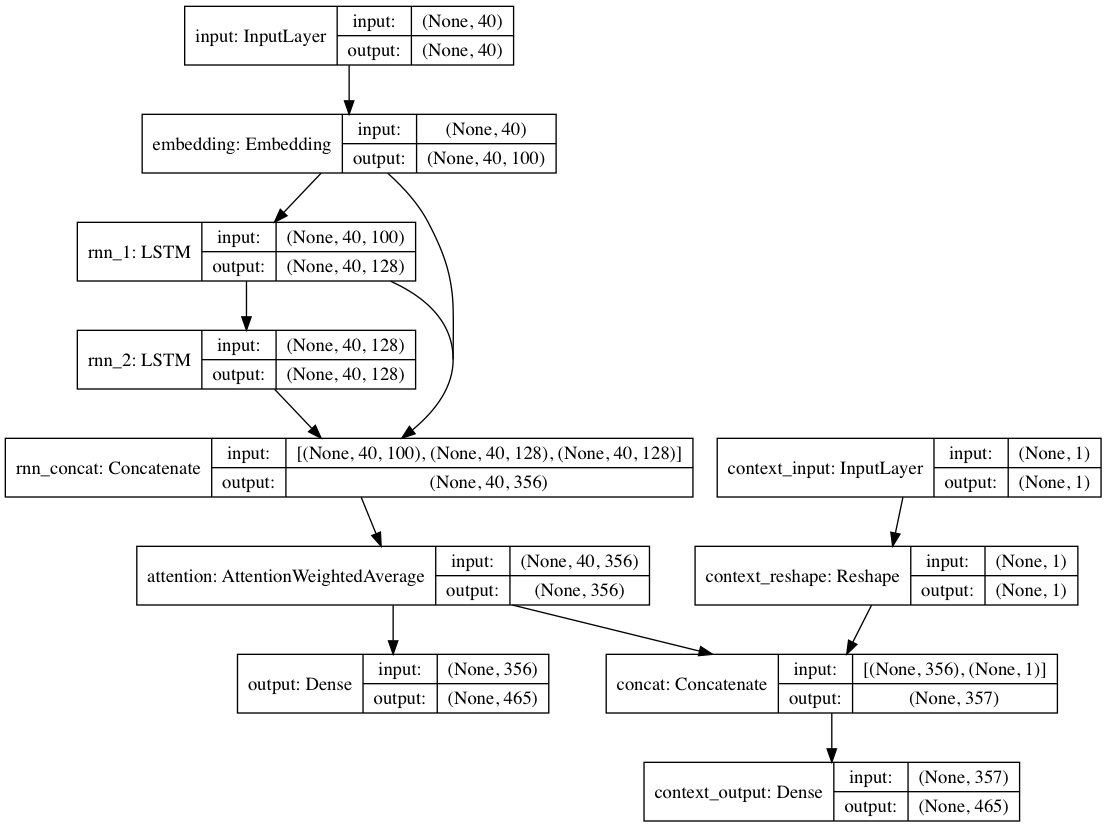
Alternatifnya, jika label konteks diberikan pada setiap dokumen teks, model dapat dilatih dalam mode kontekstual, di mana model mempelajari teks berdasarkan konteksnya sehingga lapisan berulang mempelajari bahasa yang didekontekstualisasikan . Jalur hanya teks dapat mendukung lapisan yang didekontekstualisasikan; secara keseluruhan, hal ini menghasilkan pelatihan yang jauh lebih cepat dan performa model kuantitatif dan kualitatif yang lebih baik daripada hanya melatih model berdasarkan teks saja.
Bobot model yang disertakan dengan paket dilatih pada ratusan ribu dokumen teks dari kiriman Reddit (melalui BigQuery), dari berbagai subreddit yang sangat beragam . Jaringan ini juga dilatih menggunakan pendekatan dekontekstual yang disebutkan di atas untuk meningkatkan kinerja pelatihan dan mengurangi bias penulis.
Saat menyempurnakan model pada kumpulan data teks baru menggunakan textgenrnn, semua lapisan dilatih ulang. Namun, karena jaringan asli yang telah dilatih sebelumnya memiliki "pengetahuan" yang jauh lebih kuat pada awalnya, textgenrnn yang baru akan dilatih lebih cepat dan lebih akurat pada akhirnya, dan berpotensi mempelajari hubungan baru yang tidak ada dalam kumpulan data asli (misalnya, penyematan karakter yang telah dilatih sebelumnya mencakup konteksnya untuk karakter untuk semua kemungkinan jenis tata bahasa internet modern).
Selain itu, pelatihan ulang dilakukan dengan pengoptimal berbasis momentum dan kecepatan pembelajaran yang menurun secara linier, yang keduanya mencegah ledakan gradien dan memperkecil kemungkinan model menyimpang setelah pelatihan dalam waktu lama.
Anda tidak akan mendapatkan teks berkualitas yang dihasilkan 100% setiap saat , bahkan dengan jaringan saraf yang sangat terlatih. Itulah alasan utama postingan blog viral/tweet Twitter yang menggunakan pembuatan teks NN sering kali menghasilkan banyak teks dan kemudian mengkurasi/mengedit yang terbaik.
Hasil akan sangat bervariasi antar kumpulan data . Karena jaringan saraf yang telah dilatih sebelumnya berukuran relatif kecil, jaringan tersebut tidak dapat menyimpan data sebanyak yang biasanya dipamerkan RNN dalam postingan blog. Untuk hasil terbaik, gunakan kumpulan data dengan setidaknya 2.000-5.000 dokumen. Jika kumpulan data lebih kecil, Anda harus melatihnya lebih lama dengan menyetel num_epochs lebih tinggi saat memanggil metode pelatihan dan/atau melatih model baru dari awal. Meski begitu, saat ini belum ada heuristik yang baik untuk menentukan model yang “baik”.
GPU tidak diperlukan untuk melatih ulang textgenrnn, tetapi akan membutuhkan waktu lebih lama untuk melatihnya pada CPU. Jika Anda menggunakan GPU, saya sarankan untuk meningkatkan parameter batch_size untuk pemanfaatan perangkat keras yang lebih baik.
Dokumentasi yang lebih formal
Implementasi berbasis web menggunakan Tensorflow.js (berfungsi sangat baik karena ukuran jaringan yang kecil)
Suatu cara untuk memvisualisasikan keluaran lapisan perhatian untuk melihat bagaimana jaringan "belajar".
Mode yang memungkinkan arsitektur model digunakan untuk percakapan chatbot (dapat dirilis sebagai proyek terpisah)
Lebih mendalam terhadap konteks (konteks posisi + memungkinkan beberapa label konteks)
Jaringan terlatih yang lebih besar yang dapat mengakomodasi rangkaian karakter yang lebih panjang dan pemahaman bahasa yang lebih mendalam, sehingga menghasilkan kalimat yang lebih baik.
Aktivasi softmax hierarki untuk model tingkat kata (setelah Keras memiliki dukungan yang baik untuk itu).
FP16 untuk pelatihan super cepat di Volta/TPU (setelah Keras mendapat dukungan yang baik untuk itu).
Max Woolf (@minimaxir)
Proyek sumber terbuka Max didukung oleh Patreon miliknya. Jika Anda merasa proyek ini bermanfaat, segala kontribusi keuangan kepada Patreon akan dihargai dan akan dimanfaatkan secara kreatif.
Andrej Karpathy atas proposal asli char-rnn melalui postingan blog The Unreasonable Effectiveness of Recurrent Neural Networks.
Daniel Grijalva atas kontribusinya dalam mode interaktif.
MIT
Kode lapisan perhatian yang digunakan dari DeepMoji (Berlisensi MIT)


