cleanrl
v1.0.0 CleanRL Release ?
CleanRL adalah perpustakaan Deep Reinforcement Learning yang menyediakan implementasi file tunggal berkualitas tinggi dengan fitur ramah penelitian. Penerapannya bersih dan sederhana, namun kami dapat menskalakannya untuk menjalankan ribuan eksperimen menggunakan AWS Batch. Fitur unggulan CleanRL adalah:
ppo_atari.py kami hanya memiliki 340 baris kode tetapi berisi semua detail implementasi tentang cara kerja PPO dengan game Atari, jadi ini adalah implementasi referensi yang bagus untuk dibaca oleh orang-orang yang tidak ingin membaca seluruh perpustakaan modular .Anda dapat membaca lebih lanjut tentang CleanRL di makalah dan dokumentasi JMLR kami.
Proyek penting terkait CleanRL:
Dukungan untuk Gymnasium : Farama-Foundation/Gymnasium merupakan
openai/gymgenerasi penerus yang akan terus dipertahankan dan memperkenalkan fitur-fitur baru. Silakan lihat pengumuman mereka untuk detail lebih lanjut. Kami bermigrasi kegymnasiumdan kemajuannya dapat dilacak di vwxyzjn/cleanrl#277.
️ CATATAN : CleanRL bukan perpustakaan modular dan oleh karena itu tidak dimaksudkan untuk diimpor. Dengan mengorbankan kode duplikat, kami membuat semua detail implementasi varian algoritma DRL mudah dipahami, sehingga CleanRL hadir dengan kelebihan dan kekurangannya sendiri. Anda harus mempertimbangkan untuk menggunakan CleanRL jika Anda ingin 1) memahami semua detail implementasi varaint algoritme atau 2) membuat prototipe fitur-fitur canggih yang tidak didukung oleh perpustakaan DRL modular lainnya (CleanRL memiliki baris kode minimal sehingga memberi Anda pengalaman debugging yang hebat dan Anda tidak 'tidak perlu melakukan banyak subkelas seperti yang terkadang terjadi di perpustakaan DRL modular).
Prasyarat:
Untuk menjalankan eksperimen secara lokal, cobalah hal berikut:
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runsUntuk menggunakan pelacakan eksperimen dengan tongkat sihir, jalankan
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest Jika Anda tidak menggunakan poetry , Anda dapat menginstal CleanRL dengan requirements.txt :
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txtUntuk menjalankan skrip pelatihan di game lain:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
Anda juga dapat menggunakan lingkungan pengembangan bawaan yang dihosting di Gitpod:
| Algoritma | Varian Diimplementasikan |
|---|---|
| ✅ Gradien Kebijakan Proksimal (PPO) | ppo.py , dokumen |
ppo_atari.py , dokumen | |
ppo_continuous_action.py , dokumen | |
ppo_atari_lstm.py , dokumen | |
ppo_atari_envpool.py , dokumen | |
ppo_atari_envpool_xla_jax.py , dokumen | |
ppo_atari_envpool_xla_jax_scan.py , dokumen) | |
ppo_procgen.py , dokumen | |
ppo_atari_multigpu.py , dokumen | |
ppo_pettingzoo_ma_atari.py , dokumen | |
ppo_continuous_action_isaacgym.py , dokumen | |
ppo_trxl.py , dokumen | |
| ✅ Pembelajaran Q Mendalam (DQN) | dqn.py , dokumen |
dqn_atari.py , dokumen | |
dqn_jax.py , dokumen | |
dqn_atari_jax.py , dokumen | |
| ✅ DQN Kategoris (C51) | c51.py , dokumen |
c51_atari.py , dokumen | |
c51_jax.py , dokumen | |
c51_atari_jax.py , dokumen | |
| ✅ Aktor-Kritikus Lembut (SAC) | sac_continuous_action.py , dokumen |
sac_atari.py , dokumen | |
| ✅ Gradien Kebijakan deterministik mendalam (DDPG) | ddpg_continuous_action.py , dokumen |
ddpg_continuous_action_jax.py , dokumen | |
| ✅ Gradien Kebijakan Deterministik Mendalam Kembar Tertunda (TD3) | td3_continuous_action.py , dokumen |
td3_continuous_action_jax.py , dokumen | |
| ✅ Gradien Kebijakan Fase (PPG) | ppg_procgen.py , dokumen |
| ✅ Distilasi Jaringan Acak (RND) | ppo_rnd_envpool.py , dokumen |
| ✅ Qdagger | qdagger_dqn_atari_impalacnn.py , dokumen |
qdagger_dqn_atari_jax_impalacnn.py , dokumen |
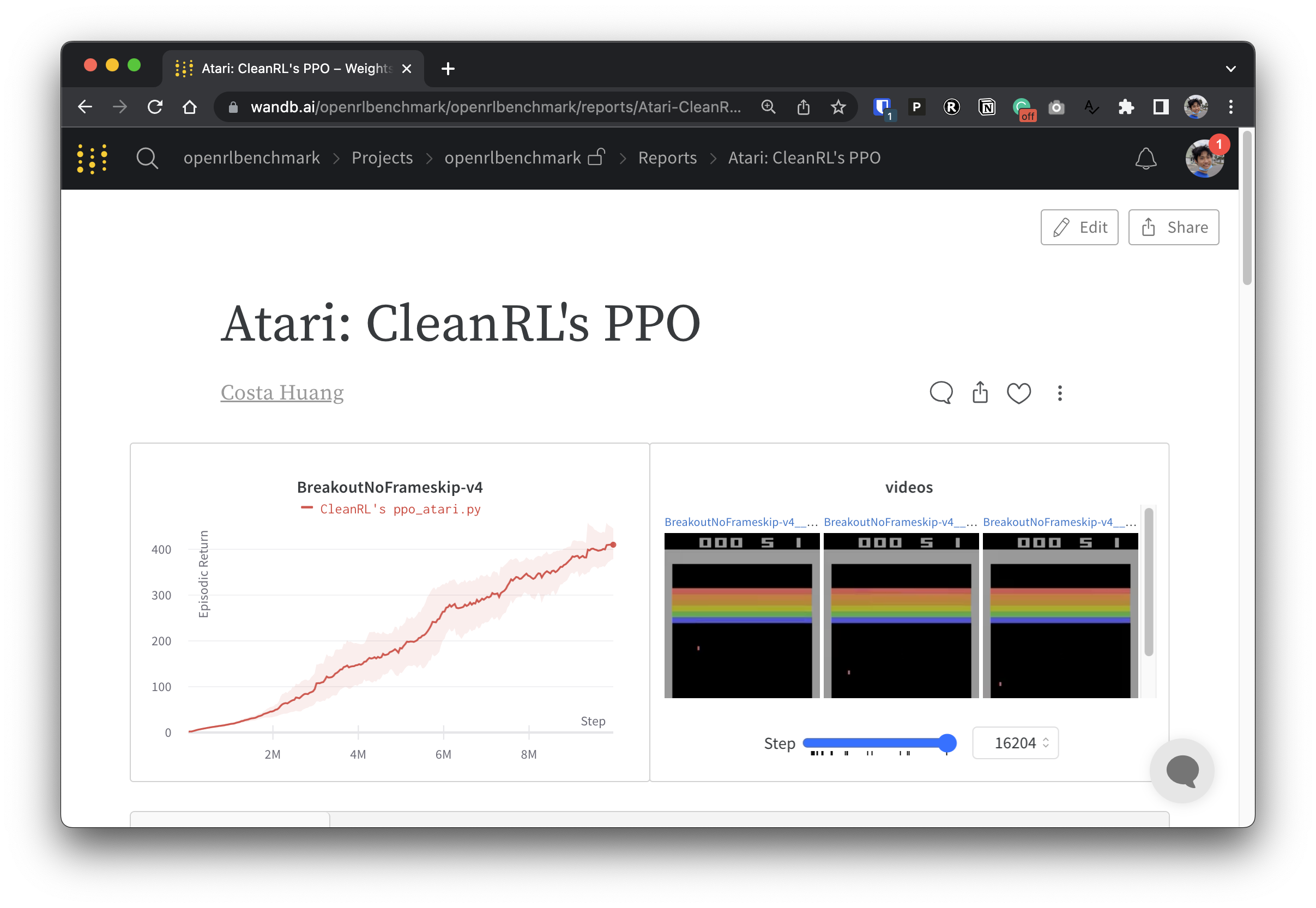
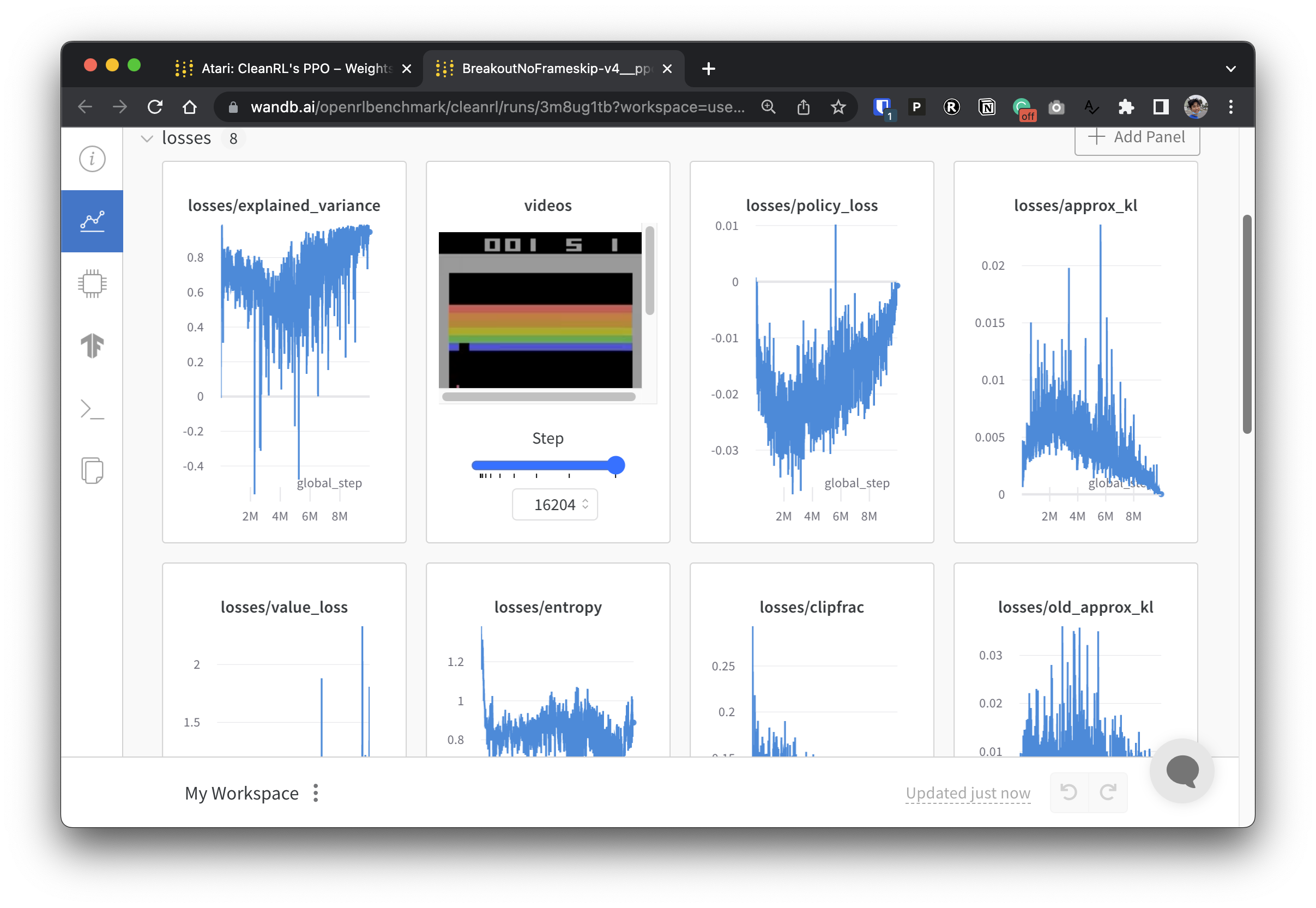
Untuk membuat data eksperimen kami transparan, CleanRL berpartisipasi dalam proyek terkait yang disebut Open RL Benchmark, yang berisi eksperimen terlacak dari perpustakaan DRL populer seperti milik kami, Stable-baselines3, openai/baselines, jaxrl, dan lainnya.
Lihat https://benchmark.cleanrl.dev/ untuk kumpulan laporan Bobot dan Bias yang menampilkan eksperimen DRL terlacak. Laporannya bersifat interaktif, dan peneliti dapat dengan mudah menanyakan informasi seperti penggunaan GPU dan video gameplay agen yang biasanya sulit diperoleh di benchmark RL lainnya. Di masa depan, Open RL Benchmark kemungkinan akan menyediakan API kumpulan data agar peneliti dapat mengakses data dengan mudah (lihat repo).
Kami memiliki Komunitas Perselisihan untuk mendapatkan dukungan. Jangan ragu untuk mengajukan pertanyaan. Posting di Github Isu dan PR juga diterima. Juga rekaman video kami sebelumnya tersedia di YouTube
Jika Anda menggunakan CleanRL dalam pekerjaan Anda, harap kutip makalah teknis kami:
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL adalah proyek yang didukung komunitas dan kontributor kami menjalankan eksperimen pada berbagai perangkat keras.


