3DDFA
1.0.0
Oleh Jianzhu Guo.

[Pembaruan]
2022.5.14 : Merekomendasikan implementasi python untuk pembuatan profil wajah: face_pose_augmentation.2020.8.30 : Model dan kode terlatih ECCV-20 dipublikasikan di 3DDFA_V2, hak cipta dijelaskan oleh Jianzhu Guo dan grup CBSR.2020.8.2 : Perbarui port c++ sederhana dari proyek ini.2020.7.3 : Upaya lanjutan Menuju Penyelarasan Wajah Padat 3D yang Cepat, Akurat, dan Stabil diterima oleh ECCV 2020. Lihat halaman saya untuk lebih jelasnya.2019.9.15 : Beberapa pembaruan, lihat penerapannya untuk detailnya.2019.6.17 : Menambahkan demo video yang disumbangkan oleh zjjMaiMai.2019.5.2 : Mengevaluasi kecepatan inferensi pada CPU dengan PyTorch v1.1.0, lihat di sini dan speed_cpu.py.2019.4.27 : Pipeline render sederhana yang berjalan pada ~25ms/frame (720p), lihat rendering.py untuk detail selengkapnya.2019.4.24 : Menyediakan gedung demo obama, lihat demo@obama/readme.md untuk lebih jelasnya.2019.3.28 : Beberapa pembaruan.2018.12.23 : Menambahkan beberapa fitur: estimasi kedalaman gambar, PNGC, fitur PAF dan serialisasi obj. Lihat opsi dump_depth , dump_pncc , dump_paf , dump_obj untuk detail selengkapnya.2018.12.2 : Mendukung pemotongan wajah tanpa landmark, lihat opsi dlib_landmark .2018.12.1 : Sempurnakan kode dan tambahkan fitur estimasi pose, lihat utils/estimate_pose.py untuk detail selengkapnya.2018.11.17 : Sempurnakan kode dan petakan simpul 3d ke ruang gambar asli.2018.11.11 : Perbarui saluran inferensi ujung ke ujung: menyimpulkan/membuat serial bentuk wajah 3D dan 68 landmark dengan satu gambar arbitrer, silakan lihat readme.md di bawah untuk detail lebih lanjut.2018.10.4 : Tambahkan demo rendering mesh wajah Matlab dalam visualisasi.2018.9.9 : Tambahkan pra-proses pemotongan wajah di benchmark.[Todo]
Repo ini berisi versi makalah pytorch yang ditingkatkan: Penyelarasan Wajah dalam Rentang Pose Penuh: Solusi Total 3D. Beberapa karya di luar makalah asli ditambahkan, termasuk pelatihan real-time, strategi pelatihan. Oleh karena itu, repo ini merupakan versi perbaikan dari karya aslinya. Sejauh ini, repo ini merilis model pytorch tahap pertama yang telah dilatih sebelumnya dari struktur MobileNet-V1, kumpulan data dan basis kode pelatihan & pengujian yang telah diproses sebelumnya. Perhatikan bahwa waktu inferensi adalah sekitar 0,27 ms per gambar (kumpulan masukan dengan 128 gambar sebagai kumpulan masukan) pada GeForce GTX TITAN X.
Repo ini akan terus diperbarui di waktu luang saya, dan segala masalah serta PR yang berarti akan diterima.
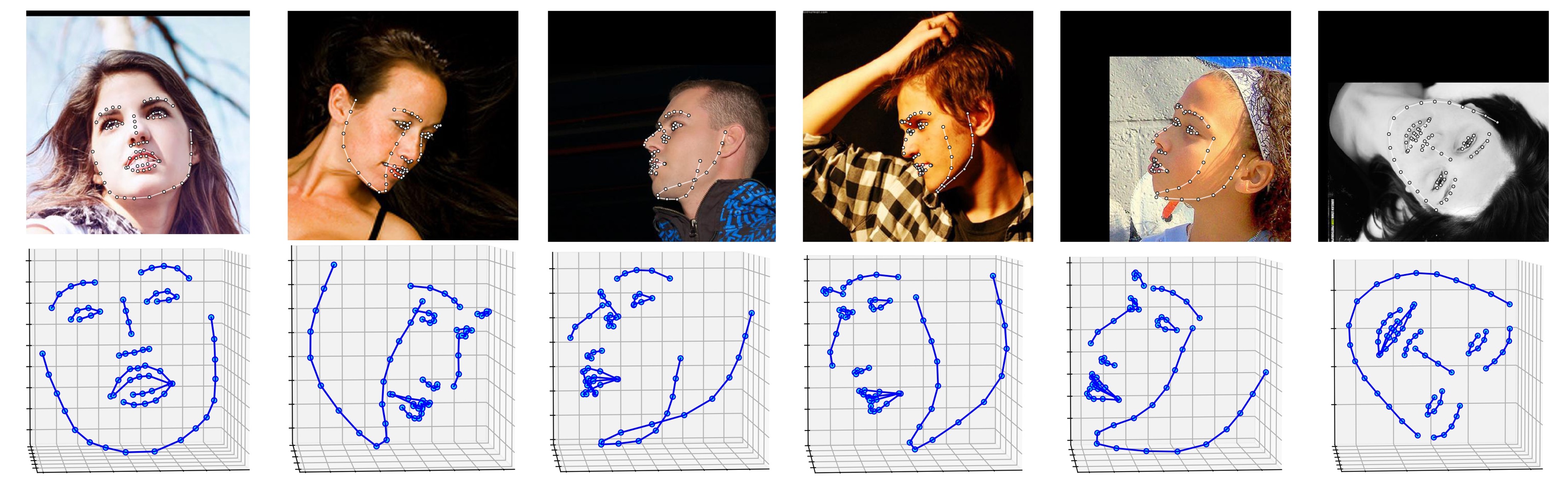
Beberapa hasil pada dataset ALFW-2000 (disimpulkan dari modelphase1_wpdc_vdc.pth.tar ) ditunjukkan di bawah ini.





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
Selain itu, saya sangat menyarankan menggunakan Python3.6+ daripada versi yang lebih lama untuk desainnya yang lebih baik.
Kloning repo ini (ini mungkin memerlukan waktu karena ukurannya agak besar)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
Kemudian, unduh model terlatih dlib landmark di Google Drive atau Baidu Yun, dan masukkan ke direktori models . (Untuk memperkecil ukuran repo ini, saya menghapus beberapa file biner berukuran besar termasuk model ini, jadi Anda harus mengunduhnya : ))
Bangun modul cython (hanya satu baris untuk membangun)
cd utils/cython
python3 setup.py build_ext -i
Ini untuk mempercepat estimasi kedalaman dan render PNCC karena Python terlalu lambat dalam loop for.
Jalankan main.py dengan gambar arbitrer sebagai input
python3 main.py -f samples/test1.jpg
Jika Anda dapat melihat keluaran terminal masuk ini, Anda berhasil menjalankannya.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
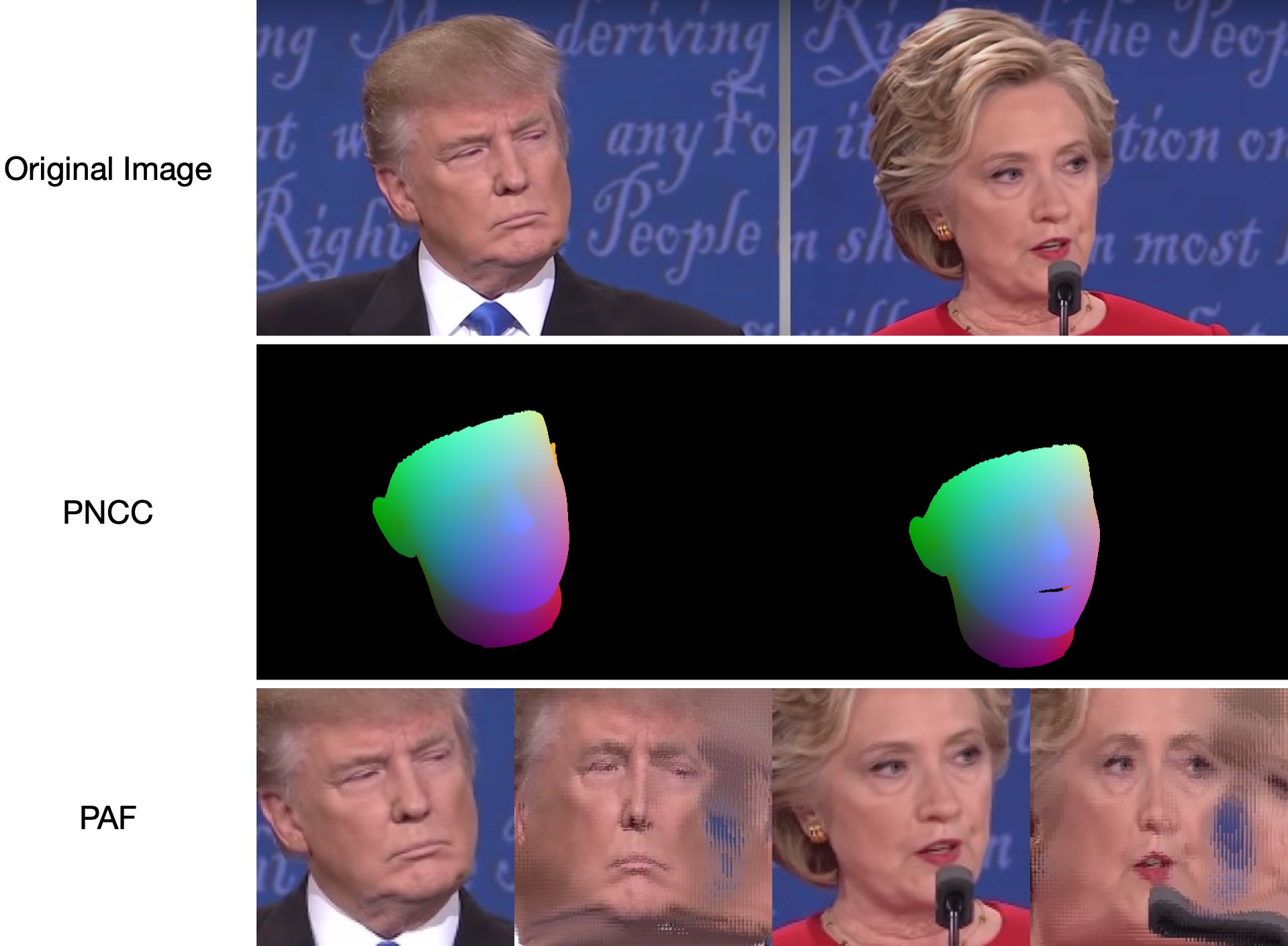
Karena test1.jpg memiliki dua wajah, ada dua file .ply dan .obj (dapat dirender oleh Meshlab atau Microsoft 3D Builder) yang diprediksi. Kedalaman, PNCC, PAF, dan estimasi pose semuanya disetel benar secara default. Silakan jalankan python3 main.py -h atau tinjau kode untuk lebih jelasnya.
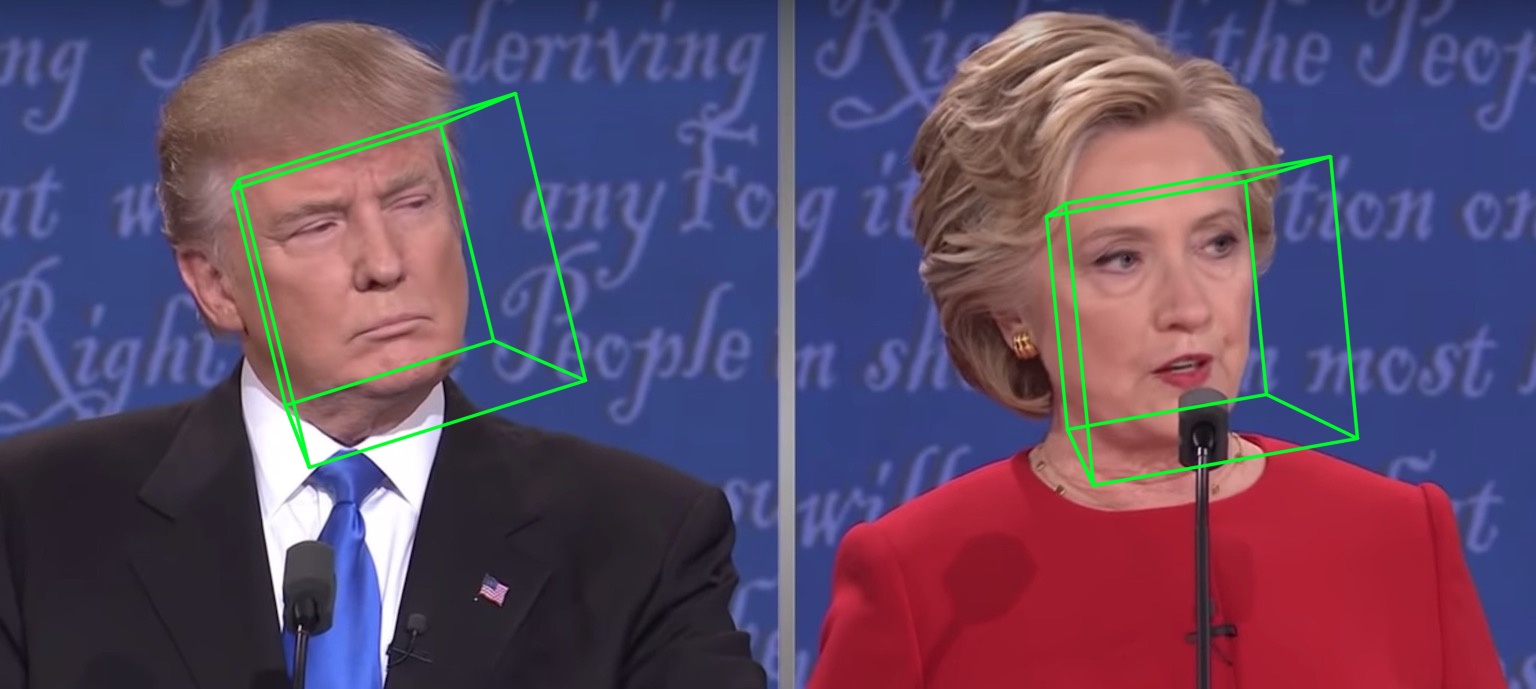
68 landmark hasil visualisasi samples/test1_3DDFA.jpg dan hasil estimasi pose samples/test1_pose.jpg ditampilkan di bawah ini:

Contoh tambahan
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
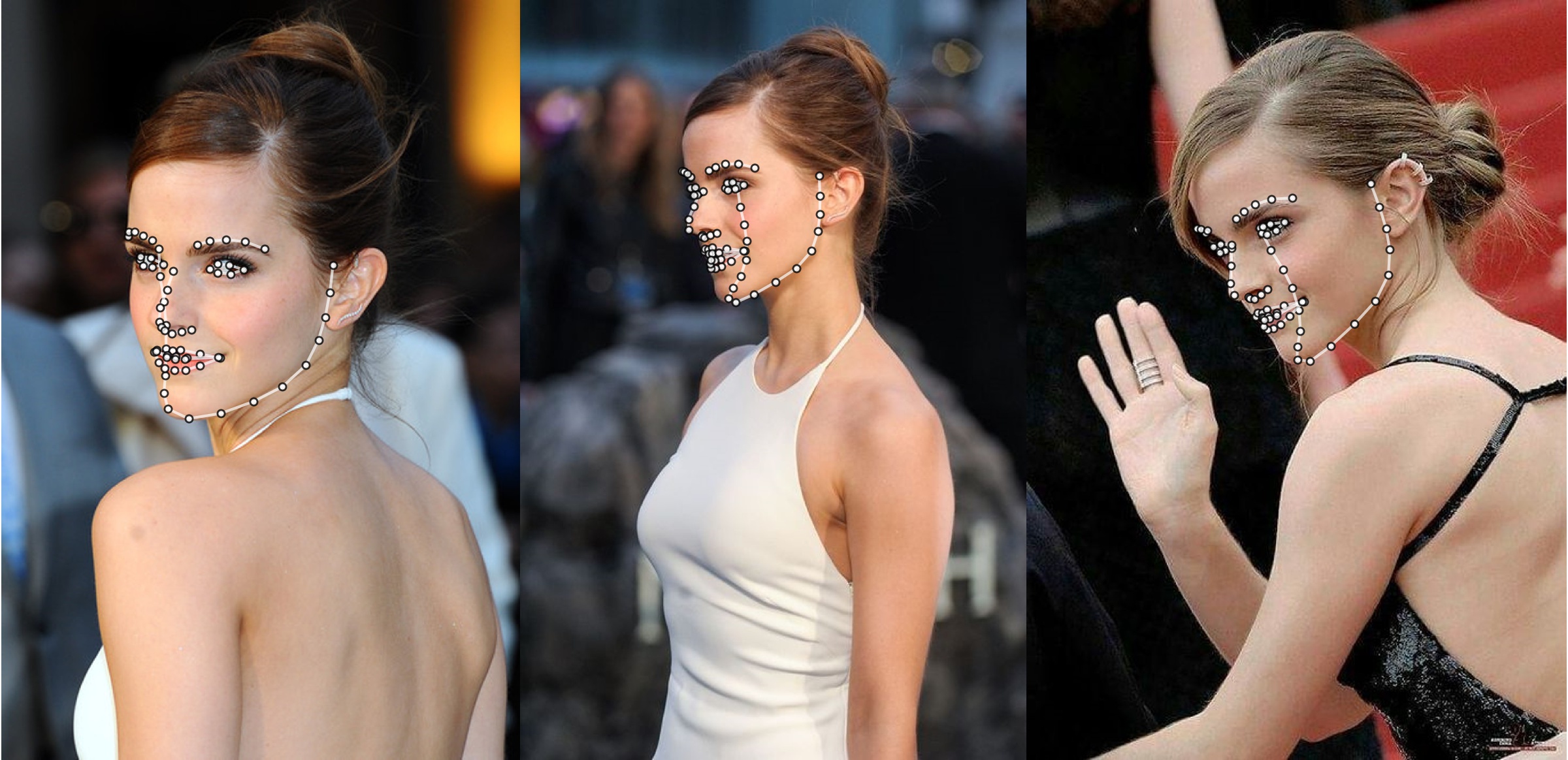
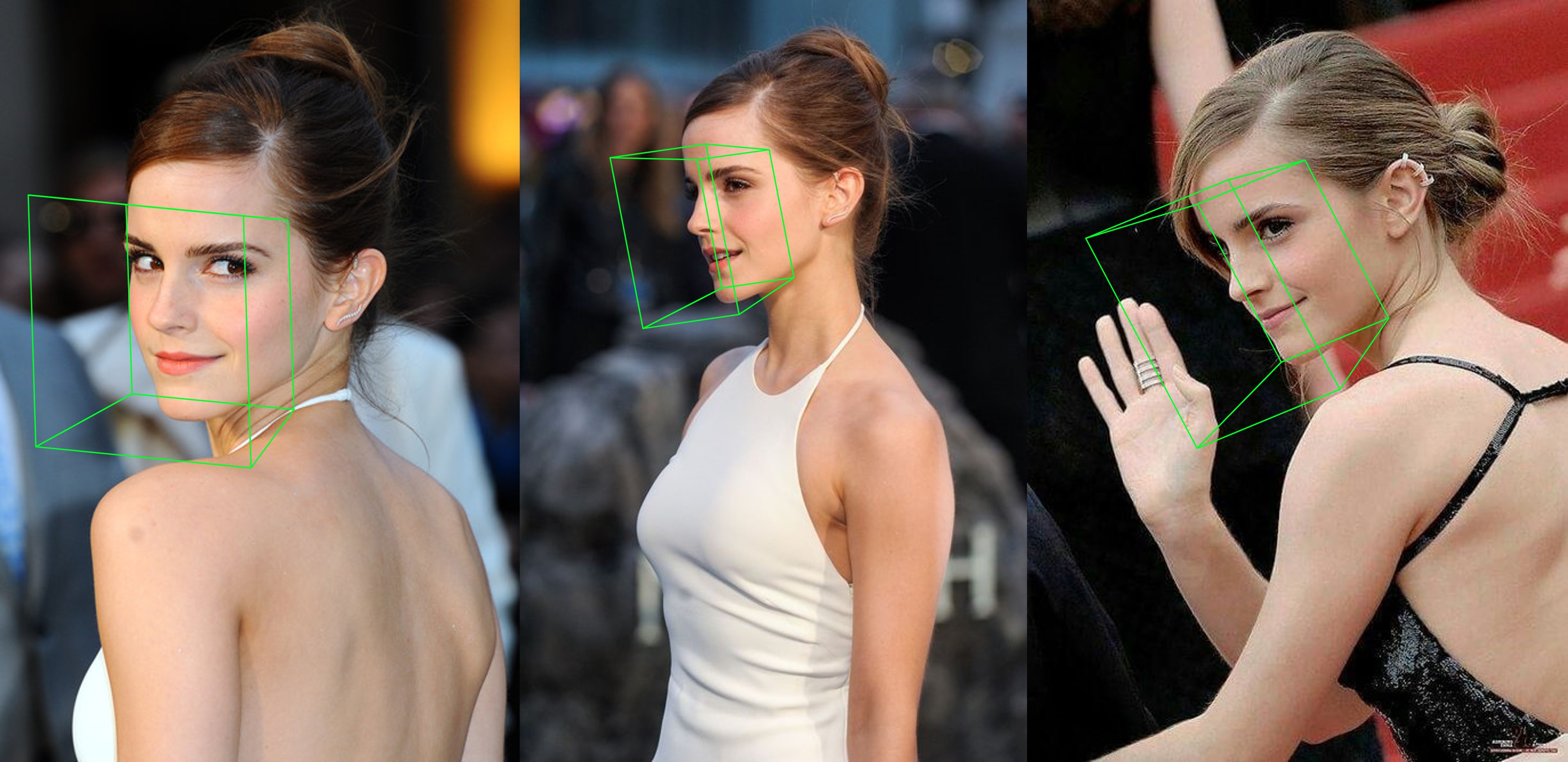
Jalankan saja
python3 speed_cpu.py
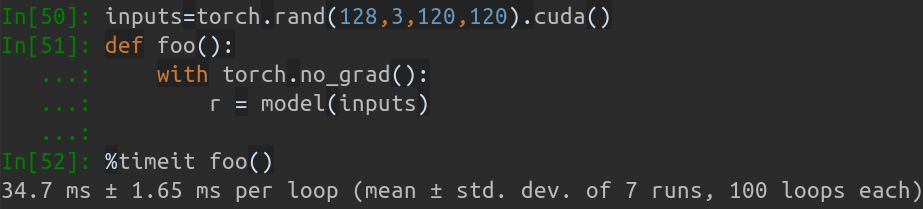
Pada MBP saya (CPU i5-8259U @ 2,30GHz pada MacBook Pro 13 inci), berdasarkan PyTorch v1.1.0 , dengan satu masukan, keluaran yang berjalan adalah:
Inference speed: 14.50±0.11 ms
Ketika ukuran batch input adalah 128, total waktu inferensi MobileNet-V1 membutuhkan waktu sekitar 34,7 ms. Kecepatan rata-ratanya sekitar 0,27 ms/gambar .
Skrip pelatihan terletak di direktori training . Sumber daya terkait ada di tabel di bawah ini.
| Data | Tautan Unduh | Keterangan |
|---|---|---|
| kereta.configs | BaiduYun atau Google Drive, 217M | Direktori yang berisi param 3DMM dan daftar file set data pelatihan |
| kereta_aug_120x120.zip | BaiduYun atau Google Drive, 2.15G | Gambar kumpulan data pelatihan augmentasi yang dipotong |
| tes.data.zip | BaiduYun atau Google Drive, 151M | Gambar yang dipotong dari set pengujian AFLW dan ALFW-2000-3D |
Setelah menyiapkan dataset pelatihan dan file konfigurasi, masuk ke direktori training dan jalankan skrip bash untuk melatih. train_wpdc.sh , train_vdc.sh dan train_pdc.sh adalah contoh skrip pelatihan. Setelah mengonfigurasi set pelatihan dan pengujian, jalankan saja untuk pelatihan. Ambil train_wpdc.sh misalnya seperti di bawah ini:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
Parameter pelatihan spesifik semuanya disajikan dalam skrip bash, termasuk kecepatan pembelajaran, ukuran batch mini, zaman, dan sebagainya.
Pertama, Anda harus mengunduh testset ALFW dan ALFW-2000-3D yang telah dipotong di test.data.zip, lalu unzip dan letakkan di direktori root. Selanjutnya, jalankan kode benchmark dengan menyediakan jalur model terlatih. Saya telah menyediakan lima model terlatih di direktori models (lihat tabel di bawah). Model-model ini dilatih menggunakan kerugian yang berbeda pada tahap pertama. Ukuran model sekitar 13M karena efisiensi tinggi dari struktur MobileNet-V1.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
Performa model terlatih ditunjukkan di bawah ini. Pada tahap pertama, efektivitas kerugian yang berbeda-beda diurutkan: WPDC > VDC > PDC. Sedangkan strategi penggunaan VDC untuk menyempurnakan WPDC mencapai hasil terbaik.
| Model | AFLW (21 poin) | AFLW 2000-3D (68 poin) | Tautan Unduh |
|---|---|---|---|
| fase1_pdc.pth.tar | 6,956±0,981 | 5.644±1.323 | Baidu Yun atau Google Drive |
| fase1_vdc.pth.tar | 6.717±0.924 | 5.030±1.044 | Baidu Yun atau Google Drive |
| fase1_wpdc.pth.tar | 6,348±0,929 | 4,759±0,996 | Baidu Yun atau Google Drive |
| fase1_wpdc_vdc.pth.tar | 5,401±0,754 | 4.252±0.976 | Dalam repo ini. |
Percayalah bahwa kerangka repo ini dapat mencapai kinerja yang lebih baik daripada PRNet tanpa menambah anggaran komputasi apa pun. Pekerjaan terkait sedang ditinjau dan kode akan dirilis setelah diterima.
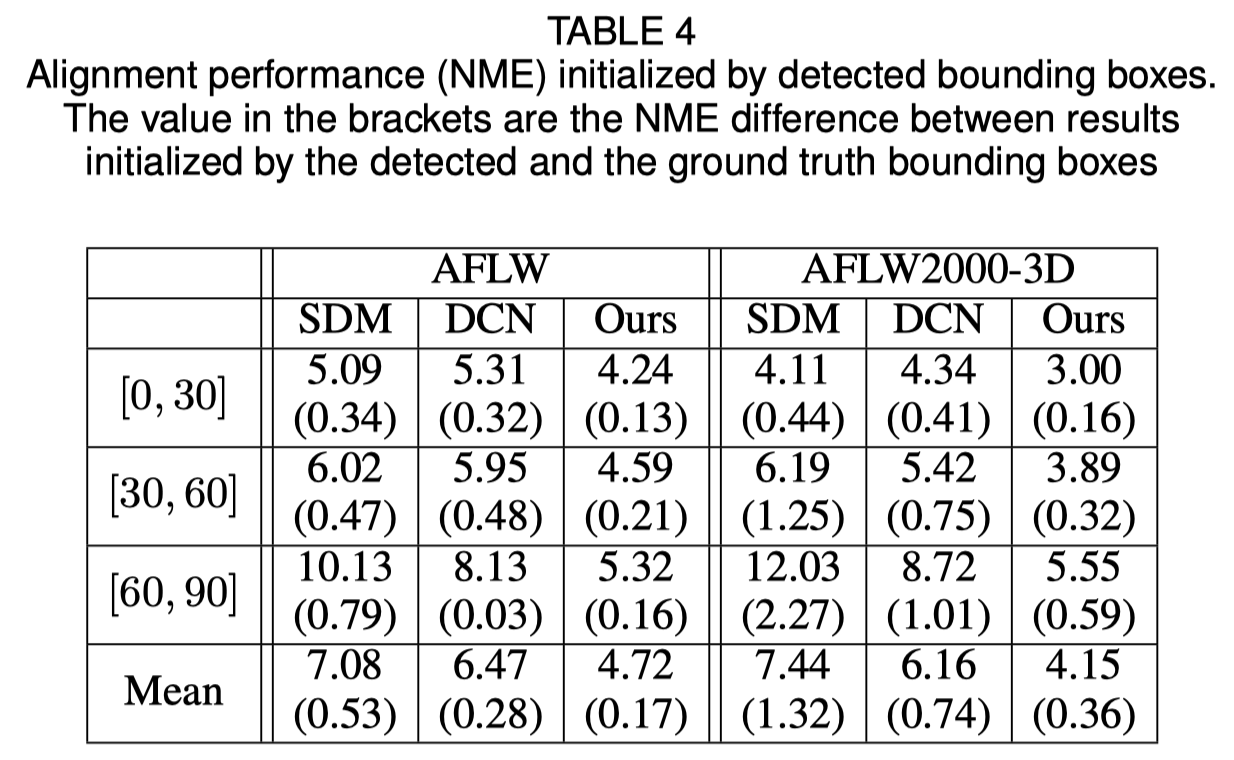
Inisialisasi kotak pembatas wajah
Makalah asli menunjukkan bahwa menggunakan kotak pembatas yang terdeteksi alih-alih kotak kebenaran dasar akan menyebabkan sedikit penurunan kinerja. Oleh karena itu, metode pemotongan wajah saat ini adalah yang paling tangguh. Hasil kuantitatif ditunjukkan pada tabel di bawah ini.
Rekonstruksi wajah
Tekstur area yang tidak terlihat terdistorsi karena oklusi diri, oleh karena itu area wajah yang tidak terlihat mungkin tampak aneh (sedikit mengerikan).
Tentang kliping parameter bentuk dan ekspresi
Pemotongan parameter mempercepat pelatihan dan rekonstruksi, namun menurunkan akurasi terutama detail seperti menutup mata. Di bawah ini adalah gambar dengan dimensi parameter 40+10, 60+29 dan 199+29 (asli). Dibandingkan dengan bentuk, kliping ekspresi memiliki efek yang lebih besar pada akurasi rekonstruksi ketika melibatkan emosi. Oleh karena itu, Anda dapat memilih trade-off antara kecepatan/ukuran parameter dan akurasi. Rekomendasi clipping trade-off adalah 60+29.

Terima kasih atas minat Anda pada repo ini. Jika karya atau penelitian Anda mendapat manfaat dari repo ini, beri bintang pada repo ini?
Selamat datang untuk fokus pada karya saya yang berhubungan dengan wajah 3D: MeGlass dan Face Anti-Spoofing.
Jika karya Anda mendapat manfaat dari repo ini, silakan kutip tiga bibs di bawah ini.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [Beranda, Google Cendekia]: [email protected] atau [email protected] .


