similarity
1.1.6
kesamaan, menghitung skor kesamaan antara string teks, tulisan Java.
Kemiripan, perangkat penghitungan kesamaan, dapat digunakan untuk penghitungan kesamaan teks, analisis sentimen, dll., yang ditulis dalam Java.
Kemiripan adalah perangkat penghitungan kesamaan versi Java yang terdiri dari serangkaian algoritma. Tujuannya adalah untuk menyebarkan metode penghitungan kesamaan dalam pemrosesan bahasa alami. Kemiripannya mempunyai ciri-ciri alat yang praktis, kinerja yang efisien, struktur yang jelas, korpus yang mutakhir, dan kemampuan penyesuaian.
Kesamaan menyediakan fungsionalitas berikut:
Perhitungan kesamaan kata
Perhitungan kesamaan frasa
Perhitungan kesamaan kalimat
Perhitungan kesamaan paragraf
CNKI Yiyuan
analisis sentimen
Perkiraan kata-kata
Sambil menyediakan fungsi yang kaya, modul internal Kemiripan menuntut kopling rendah, model menuntut pemuatan lambat, dan kamus menuntut penerbitan dalam teks biasa. Modul ini mudah digunakan dan membantu pengguna melatih corpora mereka sendiri.
Perkenalkan paket Jar
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >Pengenalan kelas:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}Panjang teks: perincian kata
Disarankan untuk menggunakan kesamaan Cilin: org.xm.Similarity.cilinSimilarity , yang merupakan metode perhitungan kesamaan berdasarkan sinonim Cilin
contoh: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
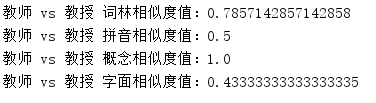
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
Panjang Teks: Perincian Frasa
Disarankan untuk menggunakan kesamaan frasa: org.xm.Similarity.phraseSimilarity , yang pada dasarnya adalah metode menghitung kesamaan dua frasa melalui karakter yang sama dan posisi karakter yang sama.
contoh: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
Panjang teks: rincian kalimat
Disarankan untuk menggunakan kesamaan bentuk kata dan urutan kata kalimat: org.xm.similarity.morphoSimilarity , metode kesamaan yang tidak hanya mempertimbangkan literal teks yang sama dari dua kalimat, tetapi juga mempertimbangkan urutan kemunculan teks yang sama.
contoh: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
Panjang teks: perincian paragraf (satu paragraf, 25 karakter < panjang (teks) < 500 karakter)
Disarankan untuk menggunakan kesamaan kalimat urutan kata bentuk kata: org.xm.similarity.text.CosineSimilarity , sebuah metode yang mempertimbangkan teks yang sama dalam dua paragraf, memberi bobot melalui segmentasi kata, frekuensi kata, dan bobot part-of-speech, dan menggunakan kosinus untuk menghitung kesamaan.
contoh: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875contoh: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}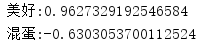
Contoh ini adalah analisis polaritas sentimen granular kata berdasarkan pohon sememe. Mengenai analisis sentimen teks, terdapat pytextclassifier, yang menggunakan model jaringan saraf dalam dan algoritma klasifikasi SVM untuk mencapai hasil yang lebih baik.
contoh: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

Pelatihan vektor kata Word2vec adalah versi Java dari alat pelatihan word2vec Word2VEC_java. Korpus pelatihan adalah novel Tian Long Ba Bu, dan sinonim diperoleh melalui vektor kata. Pengguna dapat melatih korpus khusus atau menggunakan Wikipedia bahasa Mandarin untuk melatih vektor kata universal.
Ukuran kesamaan teks

Perjanjian lisensinya adalah The Apache License 2.0, yang gratis untuk penggunaan komersial. Harap lampirkan link kesamaan dan perjanjian lisensi pada deskripsi produk.
Kode proyek masih sangat kasar. Jika Anda memiliki perbaikan pada kode tersebut, Anda dipersilakan untuk mengirimkannya kembali ke proyek ini. Sebelum mengirimkan, harap perhatikan dua poin berikut:
testAnda kemudian dapat mengirimkan PR.


