cherche
2.2.1
Pencarian saraf

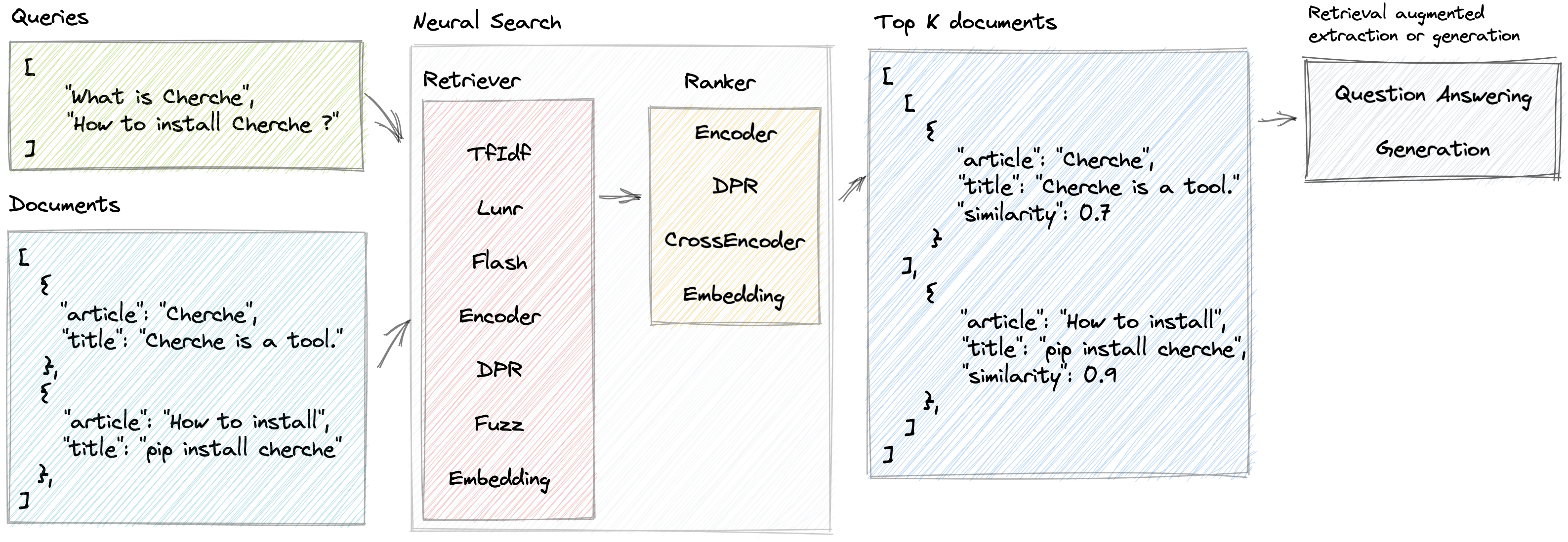
Cherche memungkinkan pengembangan saluran pencarian saraf yang menggunakan pengambil dan model bahasa terlatih baik sebagai pengambil dan pemeringkat. Keuntungan utama Cherche terletak pada kemampuannya membangun jaringan pipa end-to-end. Selain itu, Cherche sangat cocok untuk pencarian semantik offline karena kompatibilitasnya dengan komputasi batch.
Berikut beberapa fitur yang ditawarkan Cherche:
Demo langsung mesin pencari NLP yang didukung oleh Cherche
Untuk menginstal Cherche untuk digunakan dengan retriever sederhana di CPU, seperti TfIdf, Flash, Lunr, Fuzz, gunakan perintah berikut:
pip install chercheUntuk menginstal Cherche untuk digunakan dengan pengambil semantik atau serdadu apa pun di CPU, gunakan perintah berikut:
pip install " cherche[cpu] "Terakhir, jika Anda berencana menggunakan semantik retriever atau ranker di GPU, gunakan perintah berikut:
pip install " cherche[gpu] "Dengan mengikuti petunjuk instalasi ini, Anda akan dapat menggunakan Cherche dengan persyaratan yang sesuai dengan kebutuhan Anda.
Dokumentasi tersedia di sini. Ini memberikan rincian tentang retriever, ranker, pipeline dan contoh.
Cherche memungkinkan penemuan dokumen yang tepat dalam daftar objek. Berikut adalah contoh korpus.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]Berikut adalah contoh saluran pencarian saraf yang terdiri dari TF-IDF yang dengan cepat mengambil dokumen, diikuti dengan model peringkat. Model pemeringkatan mengurutkan dokumen yang dihasilkan oleh retriever berdasarkan kesamaan semantik antara kueri dan dokumen. Kita dapat memanggil pipeline menggunakan daftar kueri dan mendapatkan dokumen yang relevan untuk setiap kueri.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]Kita dapat memetakan indeks ke dokumen untuk mengakses kontennya menggunakan saluran pipa:
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche menyediakan retriever yang memfilter dokumen masukan berdasarkan kueri.
Cherche menyediakan pemeringkat yang memfilter dokumen dalam keluaran retriever.
Pemeringkat Cherche kompatibel dengan model SentenceTransformers yang tersedia di hub Hugging Face.
Cherche menyediakan modul yang didedikasikan untuk menjawab pertanyaan. Modul-modul ini kompatibel dengan model terlatih Hugging Face dan terintegrasi penuh ke dalam saluran pencarian saraf.
Cherche diciptakan untuk/oleh Renault dan sekarang tersedia untuk semua orang. Kami menyambut semua kontribusi.

Lunr retriever adalah pembungkus Lunr.py. Flash retriever adalah pembungkus FlashText. Pemeringkat DPR, Encode, dan CrossEncoder adalah pembungkus yang didedikasikan untuk penggunaan model SentenceTransformers yang telah dilatih sebelumnya dalam saluran pencarian saraf.
Jika Anda menggunakan cherche untuk menghasilkan hasil publikasi ilmiah Anda, silakan merujuk ke makalah SIGIR kami:
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}Tim pengembang Cherche terdiri dari Raphaël Sourty, François-Paul Servant, Nicolas Bizzozzero, Jose G Moreno. ?


