genai_robotics
1.0.0
Repositori ini berisi pengaturan eksperimental dan sadar privasi untuk memanfaatkan metode AI generatif dalam kontrol robotika. Dengan solusi yang disajikan di sini, pengguna dapat dengan bebas menentukan tindakan melalui suara yang diterjemahkan ke dalam rencana yang dapat dijalankan oleh robot vakum di lingkungan dunia terbuka yang diamati oleh kamera.
Keuntungan mendasar dari metode yang disajikan di sini adalah:
Sistem ini dikembangkan dalam hackathon selama 3 hari sebagai latihan pembelajaran dan pembuktian konsep bahwa alat AI modern dapat mengurangi waktu pengembangan solusi kontrol robotika secara signifikan.
Untuk menggunakan semua fitur repositori ini, inilah yang harus Anda miliki:
Untuk memulai, ikuti langkah-langkah di bawah ini:
requirements.txt ke dalam lingkungan Python (diuji dengan Python 3.11)src/config.template.toml menjadi config.toml . Untuk semua langkah di bawah ini, masukkan kredensial yang diperoleh ke config.tomlpython-roborock .src/run.py untuk menjalankan alur kerja. Cara terbaik untuk memahami apa yang dilakukan repositori ini secara detail dan bagaimana elemen berinteraksi adalah dengan diagram arsitektur:
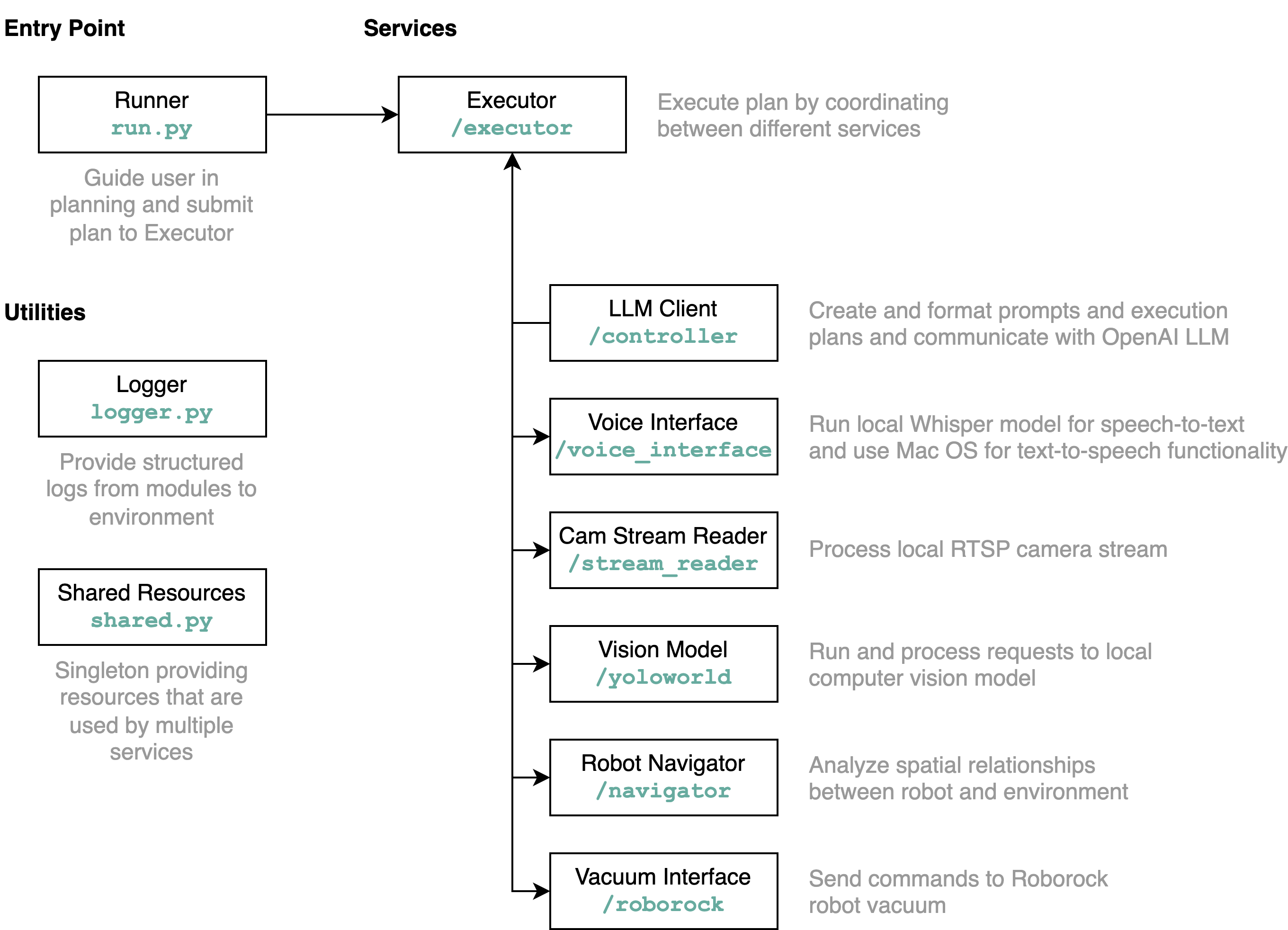
Saat Anda menjalankan file run.py seperti dijelaskan di atas, inilah yang terjadi dan cara kerjanya:
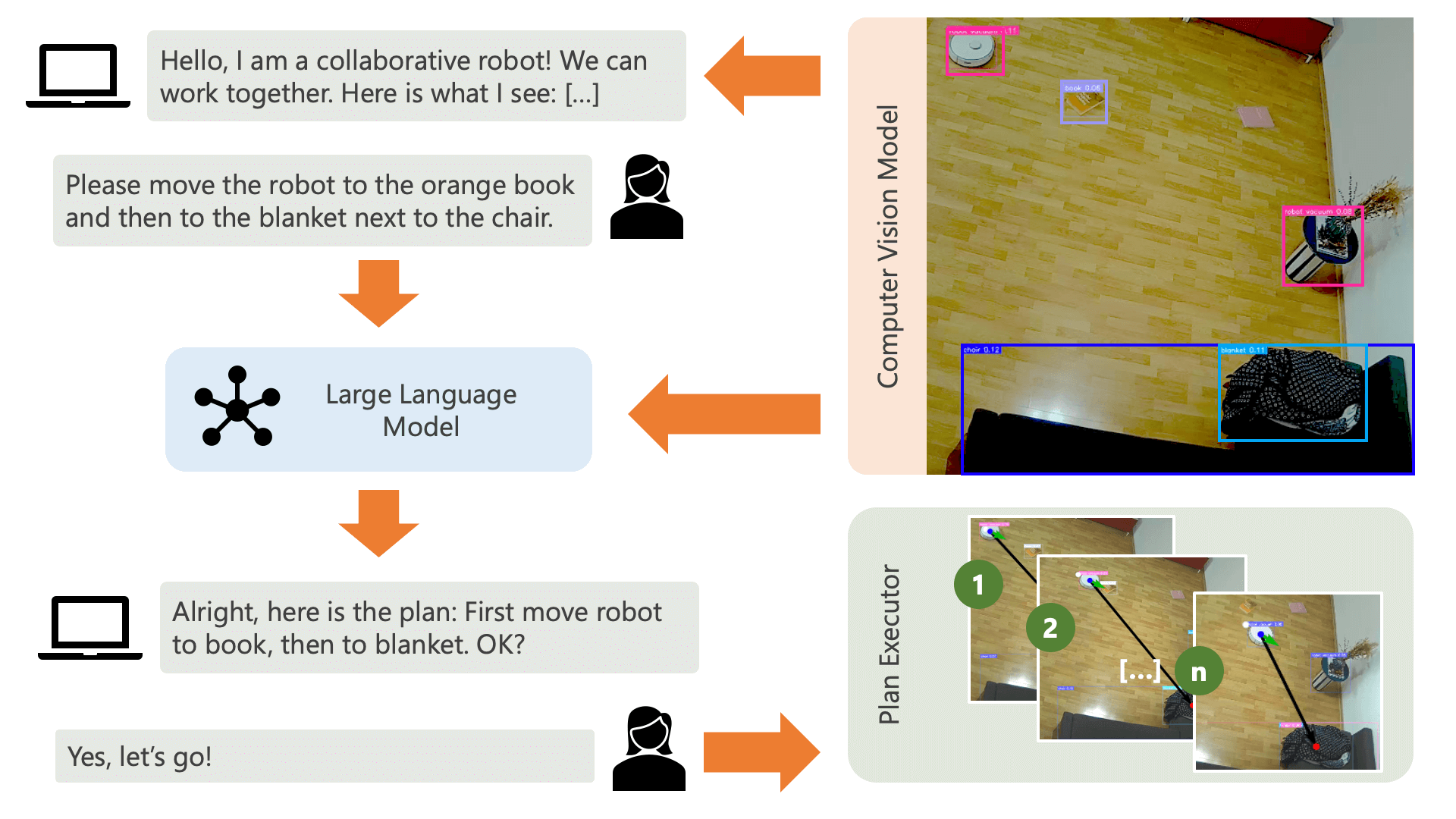
Sistem menyapa pengguna dengan pesan audio dan mengharapkan mereka memberi tahu sistem apa yang ingin mereka lakukan. Misalnya, pengguna mungkin ingin robot mengambil kopi dari seseorang yang duduk di kursi kuning dan memindahkannya ke orang lain yang duduk di sofa hitam. Sistem kemudian akan membuat rencana untuk melaksanakan tindakan ini.
Apa yang dibutuhkan sistem untuk memahami bagaimana sistem dapat mencapai apa yang ingin dilakukan pengguna? Sistem perlu menyadari lingkungannya dan tindakan yang dapat dijalankan dalam lingkungan ini. Di sini, kami menggunakan model visi komputer dengan deteksi objek untuk memberikan informasi tentang lingkungan ke sistem. Penyedot debu itu sendiri dapat melakukan 3 tindakan sederhana: Maju, berputar, dan tidak melakukan apa pun. Tindakan lain di lingkungan sedang menunggu pengguna melakukan tindakan tertentu.
Untuk menghindari kebingungan di sisi pengguna, penting bagi pengguna untuk mengetahui bagaimana AI memandang lingkungannya. Misalnya, jika suatu objek tidak dikenali oleh model visi komputer, AI tidak akan dapat memasukkannya ke dalam rencana. Penting juga bagi pengguna untuk menyadari bahwa ada ketidakpastian sehubungan dengan pengenalan model. Menggunakan model bahasa besar GPT-4o OpenAI dengan prompt deskripsi, sistem memberikan penjelasan tentang lingkungannya dan membacakannya kepada pengguna sebelum menanyakan kepada pengguna apa yang mereka ingin sistem lakukan.
Dengan mempertimbangkan informasi lingkungan dan masukan pengguna mengenai apa yang ingin mereka lakukan, sistem kemudian dapat membuat rencana. Di sini, kami meminta LLM untuk membuat rencana, dengan mempertimbangkan masukan pengguna dan deskripsi lingkungan. Anda dapat menemukan templat prompt di direktori controller . Trik menariknya di sini adalah LLM hanya mengetahui lingkungannya melalui dua tabel yang dihasilkan dari keluaran model computer vision. Berikut ini contohnya:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
Setelah LLM memproses perintah perencanaan, ia menghasilkan dua hal: Penalaran dan rencana. Sebelum sistem melanjutkan untuk menjalankan rencana, sistem akan menggunakan prompt penjelasan untuk menghasilkan ringkasan singkat dari rencana tersebut dengan tujuan mendapatkan konfirmasi dari pengguna bahwa rencana tersebut sesuai dengan apa yang mereka minta untuk dilakukan. Hal ini sesuai dengan semangat pendekatan human-in-the-loop di mana kami beroperasi dari sudut pandang bahwa dalam lingkungan fisik yang nyata dan terbuka, manusia berpotensi dirugikan oleh tindakan AI, sehingga masuk akal untuk meminta bantuan manusia. umpan balik sebelum AI melanjutkan melaksanakan rencana apa pun yang telah dibuatnya sendiri.
Setelah pengguna mengonfirmasi, sistem melanjutkan untuk menjalankan rencana. Rencana tersebut, seperti yang dihasilkan oleh LLM, mungkin terlihat seperti ini:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] Dengan menggunakan executor , sistem menjalankan rencana langkah demi langkah. Untuk mengurangi waktu penyiapan yang diperlukan, kontrol robot mengikuti algoritma yang sederhana, tidak akurat, namun efektif:
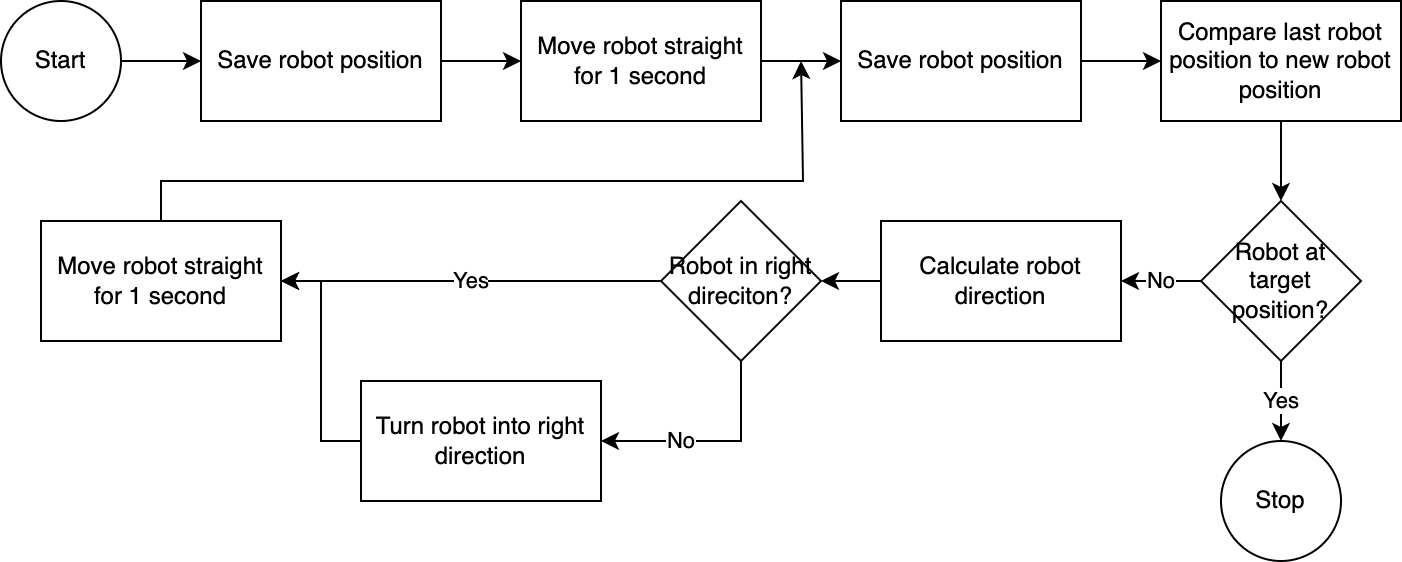
Sistem visi komputer menilai posisi robot. Melalui kode dalam modul navigator , posisi robot relatif terhadap posisi targetnya dan relatif terhadap posisi terakhir yang diketahui dianalisis dan dibandingkan. Pendekatan ini tidak sempurna karena posisi dan distorsi lensa kamera tidak diperhitungkan. Sudut yang diukur melalui pendekatan ini tidak akurat. Namun, karena sistem ini bersifat iteratif, kesalahan sering kali dapat dikompensasi. Namun, perlu dicatat bahwa hal ini mengorbankan kecepatan. Sistemnya lambat karena memerlukan waktu untuk menganalisis gambar, menghitung jalur, dan memberi tahu robot tentang langkah selanjutnya yang harus diambil.
Setelah robot mencapai posisi targetnya, pelaksana melanjutkan ke langkah rencana berikutnya. Untuk tindakan yang melibatkan input pengguna, pelaksana akan menggunakan fungsionalitas text-to-speech dan ucapan-ke-teks untuk berinteraksi dengan pengguna.
Dalam sistem ini, kami kebanyakan menggunakan layanan yang berjalan di mesin atau jaringan lokal. Pengecualian adalah GPT-4o. Kami mengirimkan data teks ke model OpenAI melalui internet. Data teks mencakup input pengguna yang ditranskripsikan dan tabel objek yang dikenali. Satu-satunya alasan kami menggunakan GPT-4o di sini adalah karena ini adalah salah satu model terbaik yang tersedia pada saat hackathon – kami juga dapat menjalankan LLM lokal dan kemudian bekerja sepenuhnya tanpa koneksi ke internet, menjaga privasi di antara seluruh aliran operasi.
Model visi komputer yang disertakan dalam repositori ini telah diproduksi oleh model YOLO-World di ruang HuggingFace dengan prompt berikut: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human . Jika Anda ingin mengenali objek tambahan, silakan sesuaikan perintahnya dan unduh model ONNX melalui ruang ini. Anda kemudian dapat mengganti model di direktori src/yoloworld/models/rev0 .
Perhatikan bahwa untuk mengekstrak model dengan benar, Anda perlu mengubah jumlah kotak maksimum dan parameter ambang batas skor secara manual di ruang HuggingFace sebelum mengekspor model.
Anda dapat mempelajari lebih lanjut tentang model YOLO-World yang menarik yang dibangun berdasarkan kemajuan terkini dalam pemodelan bahasa visi di situs web YOLO-World.
Proyek ini diterbitkan di bawah Lisensi MIT.
Repositori ini tidak dipantau secara aktif dan tidak ada niat untuk mengembangkannya – ini adalah latihan pembelajaran yang pertama dan terutama. Namun, jika Anda merasa terinspirasi, jangan ragu untuk berkontribusi pada proyek ini melalui pembukaan masalah GitHub atau permintaan tarik.


