full stack on prem cv mlops
1.0.0
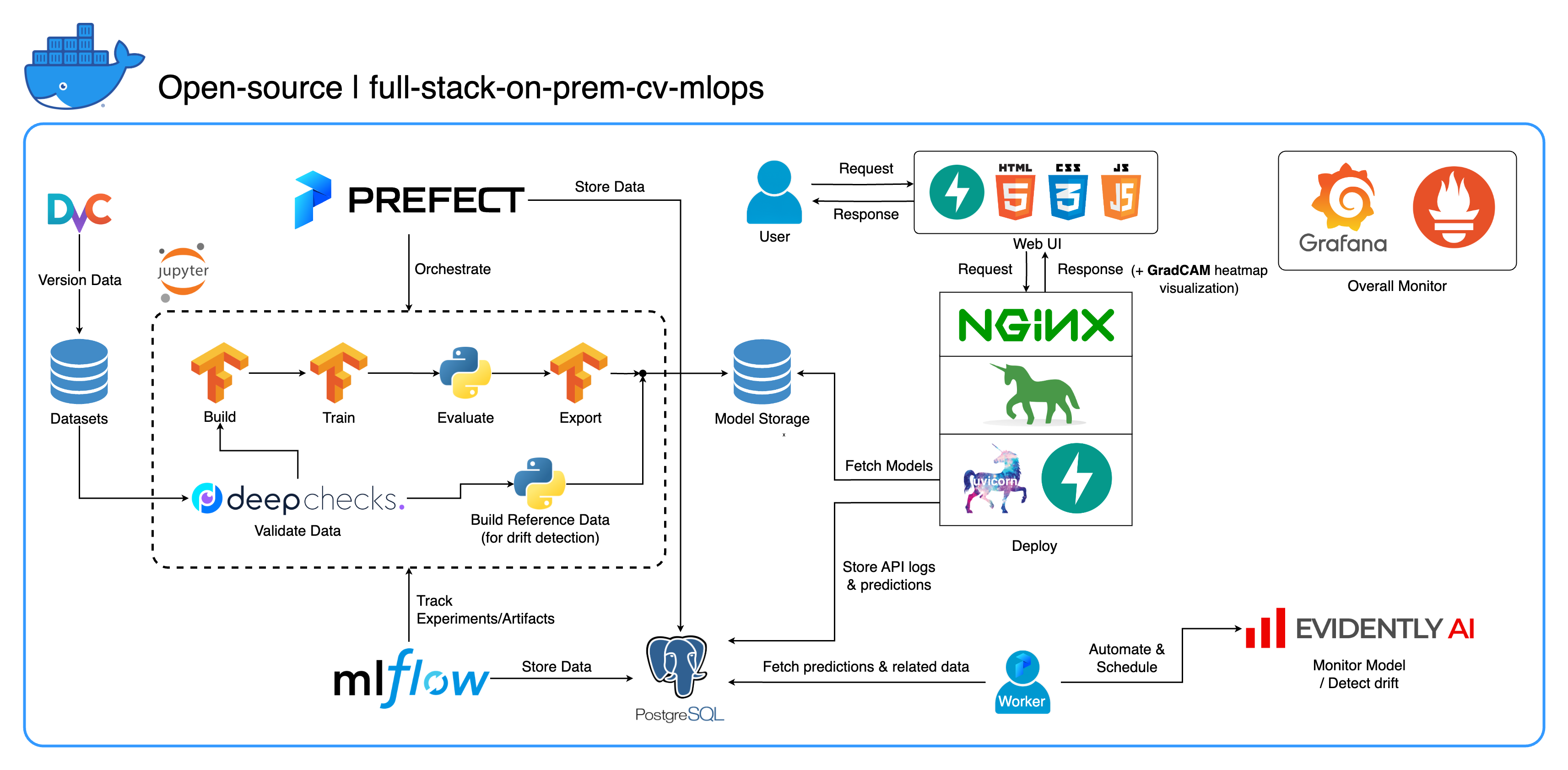
Selamat datang di ekosistem MLOps lokal komprehensif kami yang dirancang khusus untuk tugas Computer Vision, dengan fokus utama pada klasifikasi gambar. Repositori ini melengkapi Anda dengan semua yang Anda butuhkan, mulai dari ruang kerja pengembangan di Jupyter Lab/Notebook hingga layanan tingkat produksi. Bagian terbaiknya? Hanya diperlukan "1 konfigurasi dan 1 perintah" untuk menjalankan seluruh sistem mulai dari pembuatan model hingga penerapan! Kami telah mengintegrasikan berbagai praktik terbaik untuk memastikan skalabilitas dan keandalan sekaligus menjaga fleksibilitas. Meskipun kasus penggunaan utama kami berkisar pada klasifikasi gambar, struktur proyek kami dapat dengan mudah beradaptasi dengan berbagai pengembangan ML/DL, bahkan bertransisi dari lokal ke cloud!
Tujuan lainnya adalah untuk menunjukkan bagaimana mengintegrasikan semua alat ini dan membuatnya bekerja bersama dalam satu sistem penuh. Jika Anda tertarik dengan komponen atau alat tertentu, silakan pilih yang sesuai dengan kebutuhan proyek Anda.
Seluruh sistem dimasukkan ke dalam satu file Docker Compose. Untuk mengaturnya, yang harus Anda lakukan hanyalah menjalankan docker-compose up ! Ini adalah sistem yang sepenuhnya lokal, yang berarti tidak memerlukan akun cloud, dan Anda tidak perlu mengeluarkan biaya sepeser pun untuk menggunakan seluruh sistem!
Kami sangat menyarankan menonton video demo di bagian Video demo untuk mendapatkan gambaran menyeluruh dan memahami cara menerapkan sistem ini pada proyek Anda. Video-video ini berisi detail penting yang mungkin terlalu panjang dan tidak cukup jelas untuk dibahas di sini.
Demo: https://youtu.be/NKil4uzmmQc
Panduan teknis mendalam: https://youtu.be/l1S5tHuGBA8
Sumber daya dalam video:
Untuk menggunakan repositori ini, Anda hanya memerlukan Docker. Sebagai referensi, kami menggunakan Docker versi 24.0.6, build ed223bc dan Docker Compose versi v2.21.0-desktop.1 di Mac M1.
Kami telah menerapkan beberapa praktik terbaik dalam proyek ini:
tf.data untuk TensorFlowimgaug lib untuk fleksibilitas yang lebih besar dalam opsi augmentasi dibandingkan fungsi inti dari TensorFlowos.env untuk konfigurasi penting atau tingkat layananlogging alih-alih print.env untuk variabel di docker-compose.ymldefault.conf.template untuk Nginx untuk menerapkan variabel lingkungan secara elegan di konfigurasi Nginx (fitur baru di Nginx 1.19)Sebagian besar port dapat dikustomisasi dalam file .env di root repositori ini. Berikut adalah defaultnya:
123456789 )[email protected] , pw: SuperSecurePwdHere )admin , pw: admin ) Anda harus mempertimbangkan untuk mengomentari platform: linux/arm64 di docker-compose.yml jika Anda tidak menggunakan komputer berbasis ARM (kami menggunakan Mac M1 untuk pengembangan). Kalau tidak, sistem ini tidak akan berfungsi.
--recurse-submodules dalam perintah Anda: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy di bawah layanan jupyter di docker-compose.yml dan mengubah gambar dasar di services/jupyter/Dockerfile dari ubuntu:18.04 ke nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (teks ada di file, Anda hanya perlu memberi komentar dan membatalkan komentar) untuk memanfaatkan GPU. Anda mungkin juga perlu menginstal nvidia-container-toolkit di mesin host agar dapat berfungsi. Untuk pengguna Windows/WSL2, kami menemukan artikel ini sangat membantu.docker-compose up atau docker-compose up -d untuk melepaskan terminal.datasets/animals10-dvc dan ikuti langkah-langkah di bagian Cara menggunakan . http://localhost:8888/labcd ~/workspace/docker-compose.yml ) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasksflowsrun_flow.py di root repo.start(config) di file aliran Anda. Fungsi ini menerima konfigurasi sebagai dict Python dan pada dasarnya memanggil aliran spesifik dalam file itu.datasets dan semuanya harus memiliki struktur direktori yang sama dengan yang ada di dalam repo ini.central_storage di ~/ariya/ harus berisi setidaknya 2 subdirektori bernama models dan ref_data . central_storage ini melayani tujuan penyimpanan objek untuk menyimpan semua file bertahap untuk digunakan di seluruh lingkungan pengembangan dan penerapan. (Ini adalah salah satu hal yang dapat Anda pertimbangkan untuk diubah ke layanan penyimpanan cloud jika Anda ingin menerapkan di cloud dan membuatnya lebih skalabel)Konvensi PENTING yang harus SUPER EKSTRA HATI-HATI jika ingin berubah (karena hal-hal ini terikat dan digunakan di berbagai bagian sistem):
central_storage -> Di dalamnya harus ada subdirektori models/ ref_data/<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file dan monitor_pool_namecomputer-viz-dl (nilai default), dengan semua paket yang diperlukan untuk repositori ini. Semua perintah/kode Python seharusnya dijalankan dalam Jupyter ini.central_storage bertindak sebagai penyimpanan file pusat yang digunakan selama pengembangan dan penerapan. Ini terutama berisi file model (termasuk detektor penyimpangan) dan data referensi dalam format Parket. Di akhir langkah pelatihan model, model baru disimpan di sini, dan layanan penerapan mengambil model dari lokasi ini. ( Catatan : Ini adalah tempat yang ideal untuk mengganti layanan penyimpanan cloud untuk skalabilitas.)model di konfigurasi untuk membuat model pengklasifikasi. Model ini dibuat dengan TensorFlow dan arsitekturnya di-hardcode di tasks/model.py:build_model .dataset di konfigurasi untuk menyiapkan kumpulan data untuk pelatihan. DvC digunakan pada langkah ini untuk memeriksa konsistensi data dalam disk dibandingkan dengan versi yang ditentukan dalam konfigurasi. Jika ada perubahan, itu akan mengubahnya kembali ke versi yang ditentukan secara terprogram. Jika Anda ingin menyimpan perubahan, jika Anda bereksperimen dengan kumpulan data, Anda dapat menyetel bidang dvc_checkout di konfigurasi ke false sehingga DvC tidak melakukan tugasnya.train di konfigurasi untuk membuat pemuat data dan memulai proses pelatihan. Info eksperimen dan artefak dilacak dan dicatat dengan MLflow . Catatan: laporan hasil (dalam file .html ) dari DeepChecks juga diunggah ke eksperimen pelatihan di MLflow untuk konvensi.model di konfigurasi.central_storage (dalam hal ini, hanya membuat salinan ke lokasi central_storage . Ini adalah langkah yang dapat Anda ubah untuk mengunggah file ke penyimpanan cloud)model/drift_detection di konfigurasi.central_storage .central_storage .central_storage . (ini adalah salah satu kekhawatiran yang dibahas dalam video demo tutorial, tonton untuk lebih detailnya)current_model_metadata_file yang menyimpan nama file metadata model yang diakhiri dengan .yaml dan monitor_pool_name menyimpan nama kumpulan kerja untuk menerapkan pekerja dan aliran Prefek.cd secara terprogram ke dalam deployments/prefect-deployments dan jalankan prefect --no-prompt deploy --name {deploy_name} menggunakan input dari bagian deploy/prefect di konfigurasi. Karena semuanya sudah di-docker dan dimasukkan ke dalam container di repo ini, mengubah layanan dari on-prem ke on-cloud cukup mudah. Ketika Anda selesai mengembangkan dan menguji API layanan Anda, Anda cukup memisahkan services/dl_service dengan membangun kontainer dari Dockerfile-nya, dan mendorongnya ke layanan registri kontainer cloud (AWS ECR, misalnya). Itu saja!
Catatan: Ada satu potensi masalah dalam kode layanan jika Anda ingin menggunakannya di lingkungan produksi nyata. Saya telah membahasnya dalam video mendalam dan saya menyarankan Anda meluangkan waktu untuk menonton keseluruhan video. 
Kami memiliki tiga database di dalam PostgreSQL: satu untuk MLflow, satu untuk Prefek, dan satu lagi yang kami buat untuk layanan model ML kami. Kami tidak akan mempelajari dua hal pertama, karena keduanya dikelola sendiri oleh alat tersebut. Basis data untuk layanan model ML kami adalah yang kami rancang sendiri.
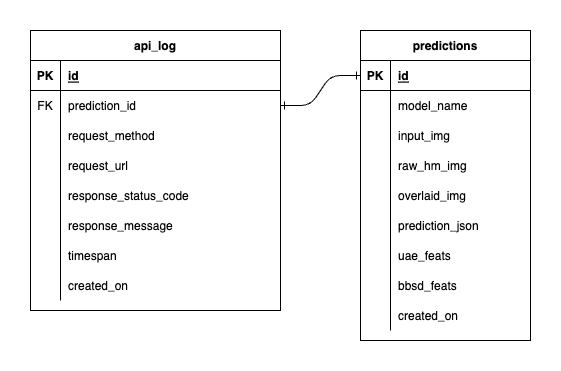
Untuk menghindari kerumitan yang berlebihan, kami membuatnya tetap sederhana hanya dengan dua tabel. Hubungan dan atribut ditunjukkan pada ERD di bawah ini. Pada dasarnya, kami bertujuan untuk menyimpan detail penting tentang permintaan masuk dan tanggapan layanan kami. Semua tabel ini dibuat dan dimanipulasi secara otomatis, jadi Anda tidak perlu khawatir tentang pengaturan manual.
Patut diperhatikan: input_img , raw_hm_img , dan overlaid_img adalah gambar berkode base64 yang disimpan sebagai string. uae_feats dan bbsd_feats adalah rangkaian fitur penyematan untuk algoritme deteksi penyimpangan kami.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block , coba export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 lalu jalankan kembali naskah.

