SmartFilteringRAG
1.0.0
Pernah menelusuri "komedi hitam putih lama" hanya untuk dibombardir dengan campuran film aksi modern? Membuat frustrasi, bukan? Itulah tantangan yang dihadapi mesin telusur tradisional - mereka sering kali kesulitan memahami nuansa kueri kami, sehingga membuat kami harus mengarungi hasil yang tidak relevan.
Di sinilah Smart Filtering berperan. Ini adalah pengubah permainan yang menggunakan pencarian metadata dan vektor untuk memberikan hasil pencarian yang benar-benar sesuai dengan maksud Anda. Bayangkan menemukan komedi klasik yang Anda dambakan, tanpa repot.
Kami akan mendalami apa itu Pemfilteran Cerdas, cara kerjanya, dan mengapa hal ini penting untuk membangun pengalaman penelusuran yang lebih baik. Mari kita temukan keajaiban di balik teknologi ini dan jelajahi bagaimana teknologi ini dapat merevolusi cara Anda melakukan penelusuran.
Pencarian vektor adalah alat canggih yang membantu komputer memahami makna di balik data, bukan hanya kata-kata itu sendiri. Alih-alih mencocokkan kata kunci, ini berfokus pada konsep dan hubungan yang mendasarinya. Bayangkan menelusuri "anjing" dan mendapatkan hasil yang mencakup "anak anjing", "anjing", dan bahkan gambar anjing. Itulah keajaiban pencarian vektor!
Bagaimana cara kerjanya? Ya, itu mengubah data menjadi representasi matematika yang disebut vektor. Vektor-vektor ini seperti koordinat pada peta, dan titik-titik data serupa terletak berdekatan dalam ruang vektor ini. Saat Anda mencari sesuatu, sistem akan menemukan vektor yang paling dekat dengan kueri Anda, sehingga memberikan hasil yang serupa secara semantik.
Meskipun penelusuran vektor sangat bagus dalam memahami konteks, terkadang penelusuran ini gagal dalam tugas pemfilteran sederhana. Misalnya, menemukan semua film yang dirilis sebelum tahun 2000 memerlukan pemfilteran yang tepat, bukan hanya pemahaman semantik. Di sinilah Smart Filtering hadir untuk melengkapi pencarian vektor.
Meskipun vektor membawa kita lebih dekat untuk memahami arti sebenarnya dari kueri, masih ada kesenjangan antara apa yang diinginkan pengguna dan apa yang diberikan oleh mesin pencari. Kueri penelusuran yang rumit seperti "film komedi paling awal sebelum tahun 2000" masih dapat menjadi tantangan. Penelusuran semantik mungkin memahami konsep "komedi" dan "film", namun mungkin kesulitan memahami konsep "paling awal" dan "sebelum tahun 2000".
Di sinilah hasilnya mulai berantakan. Kita mungkin mendapatkan campuran komedi lama dan baru, atau bahkan drama yang salah dimasukkan. Untuk benar-benar memuaskan pengguna, kami memerlukan cara untuk menyaring hasil penelusuran ini dan menjadikannya lebih tepat. Di sinilah pra-filter berperan.
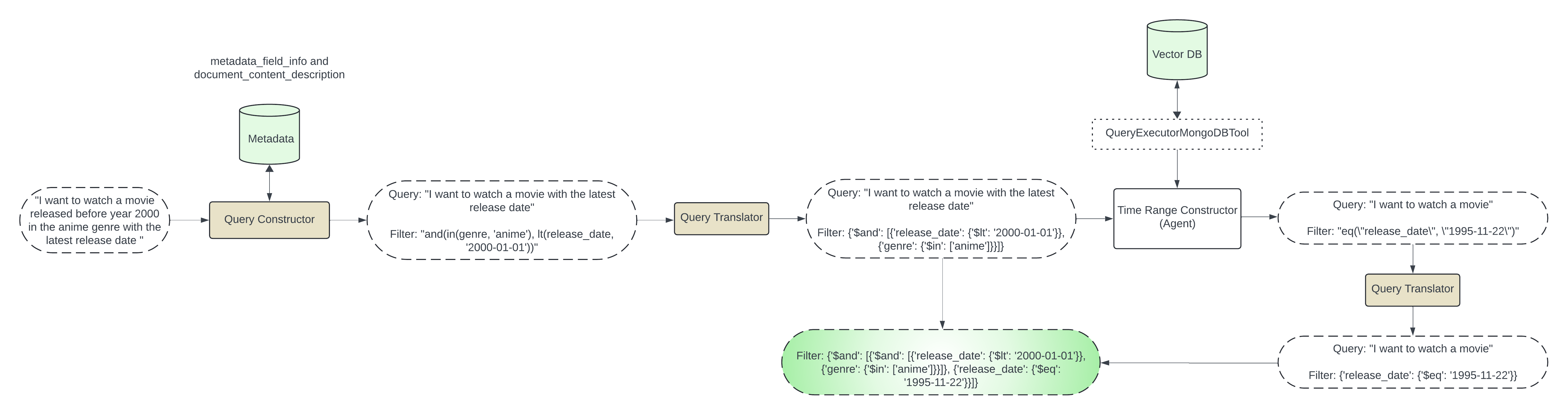
Pemfilteran Cerdas adalah solusi untuk tantangan ini. Ini adalah teknik yang menggunakan metadata kumpulan data untuk membuat filter tertentu, menyempurnakan hasil penelusuran, dan menjadikannya lebih akurat dan efisien. Dengan menganalisis informasi tentang data Anda, seperti struktur, konten, dan atributnya, Pemfilteran Cerdas dapat mengidentifikasi kriteria yang relevan untuk memfilter penelusuran Anda.
Bayangkan menelusuri "film komedi yang dirilis sebelum tahun 2000". Pemfilteran Cerdas akan menggunakan metadata seperti genre, tanggal rilis, dan bahkan kata kunci plot untuk membuat filter yang hanya menyertakan film yang cocok dengan kriteria tersebut. Dengan cara ini, Anda mendapatkan daftar apa yang Anda inginkan, tanpa gangguan yang tidak relevan.
Mari selami lebih dalam cara kerja Smart Filtering di bagian selanjutnya.
Pemfilteran Cerdas adalah proses multi-langkah yang melibatkan penggalian informasi dari data Anda, menganalisisnya, dan membuat filter spesifik berdasarkan kebutuhan Anda. Mari kita uraikan:
Ekstraksi Metadata: Langkah pertama adalah mengumpulkan informasi yang relevan tentang data Anda. Ini termasuk detail seperti:
Pembuatan Pra-filter: Setelah Anda memiliki metadata, Anda dapat mulai membuat pra-filter. Ini adalah kondisi khusus yang harus dipenuhi data agar dapat dimasukkan dalam hasil pencarian. Misalnya, jika Anda mencari film komedi yang dirilis sebelum tahun 2000, Anda dapat membuat pra-filter untuk:
Integrasi dengan Pencarian Vektor: Langkah terakhir adalah menggabungkan pra-filter ini dengan pencarian vektor Anda. Hal ini memastikan bahwa pencarian vektor hanya mempertimbangkan titik data yang cocok dengan kriteria yang telah Anda tentukan sebelumnya.
Dengan mengikuti langkah-langkah ini, Pemfilteran Cerdas secara signifikan meningkatkan akurasi dan efisiensi hasil pencarian Anda.
Ekstraksi Metadata: Untuk menyederhanakan, kami akan menggunakan data sampel dan mendefinisikan metadata secara manual. Rujuk: get_docs_metadata di prepare_test_data.py .
Pembuatan Pra-filter: Kami akan membuat pra-filter dalam dua langkah.
Langkah 1: Filter berbasis metadata
Langkah ini termasuk membuat filter berdasarkan metadata. Kami akan meneruskan kueri pengguna dan metadata ke LLM dan menghasilkan filter metadata.
Kami akan menggunakan query_constructor yang diinisialisasi dengan DEFAULT_SCHEMA_PROMPT ini.
Catatan: Perbarui perintah dan beberapa contoh pengambilan gambar sesuai kasus penggunaan Anda.
Misalnya: Jika metadata memiliki genre dan release_date , dan pengguna meminta film bergenre action yang dirilis sebelum tahun 2020, maka kita dapat menggunakan LLM untuk membuat filter seperti di bawah ini:
{"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}
Langkah 2: Pemfilteran berdasarkan waktu
Pada langkah ini, kami akan menangani kasus di mana pengguna meminta jenis informasi latest , most recent , dan earliest . Kami harus menanyakan data aktual untuk mengambil informasi ini. Kami akan menggunakan Agen LLM pada langkah ini untuk menanyakan koleksi mongodb menggunakan alat pelaksana: QueryExecutorMongoDBTool Kami membuat filter berbasis waktu di generate_time_based_filter. Kami juga akan menggunakan pre_filter yang dihasilkan pada langkah pertama di $match pada tahap agregasi. Misalnya: Jika pengguna menginginkan film terbaru, agen LLM akan menjalankan kueri agregasi di bawah ini menggunakan alat eksekutor:
Invoking: `mongo_db_executor` with `{'pipeline': '[{"$match": {"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}}, { "$sort": { "release_date": -1 } }, { "$limit": 1 }, { "$project": { "release_date": 1 } }]'}`
Integrasi dengan Pencarian Vektor: Pra-filter yang dihasilkan akan digunakan dengan pengambilan MongoDBAtlasVectorSearch:
retriever = vectorstore.as_retriever(
search_kwargs={ ' pre_filter ' : pre_filter}
)Buat lingkungan python baru
python3 -m venv env
source env/bin/activateInstal persyaratannya
pip3 install -r requirements.txtAtur konfigurasi di config.yaml
database_name: < your database name >
collection_name: < your collection name >
vector_index_name: default
embedding_model_dimensions: 1536
similarity: cosine
model: gpt-4o
embedding_model: text-embedding-ada-002Tetapkan variabel lingkungan
export OPEN_AI_API_KEY = " "
export OPEN_API_BASE = " "
# headers are optional
export OPEN_API_DEFAULT_HEADERS= " "
export MONGO_URI= " "Inisialisasi koleksi mongodb dengan data sampel. Perintah ini akan mengindeks beberapa data sampel dan juga membuat indeks pencarian vektor pada koleksi tersebut.
python3 rag/initialize_mongo_collection.pypython3 rag/main.py --queries < list of queries in json format > python3 rag/main.py --queries ' ["I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010", "Recommend an anime movie released before 2023 with the latest release date"] 'Pra_filter yang dihasilkan:
Input Query: "I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010"
Keluaran: 
Permintaan Masukan: "Recommend a thriller or action movie release after Feb, 2010"
Keluaran: 
Input Query: "Recommend an anime movie released before 2023 with the latest release date"
Keluaran: 
Pemfilteran Cerdas menghadirkan sejumlah keuntungan, menjadikannya alat yang berharga untuk meningkatkan pengalaman pencarian:
Peningkatan Akurasi Penelusuran: Dengan secara tepat menargetkan data yang cocok dengan kueri Anda, Pemfilteran Cerdas secara dramatis meningkatkan kemungkinan menemukan hasil yang relevan. Tidak perlu lagi mengarungi informasi yang tidak relevan.
Hasil Pencarian Lebih Cepat: Karena Pemfilteran Cerdas mempersempit cakupan pencarian, sistem dapat memproses informasi dengan lebih efisien, sehingga menghasilkan hasil yang lebih cepat.
Pengalaman Pengguna yang Ditingkatkan: Ketika pengguna menemukan apa yang mereka cari dengan cepat dan mudah, hal ini akan menghasilkan kepuasan yang lebih tinggi dan pengalaman keseluruhan yang lebih baik.
Keserbagunaan: Pemfilteran Cerdas dapat diterapkan ke berbagai domain, mulai dari penelusuran produk e-niaga hingga rekomendasi konten, menjadikannya alat serbaguna.
Dengan memanfaatkan metadata dan membuat pra-filter yang ditargetkan, Pemfilteran Cerdas memberdayakan Anda untuk memberikan hasil penelusuran yang benar-benar memenuhi harapan pengguna.
Pemfilteran Cerdas adalah alat canggih yang mengubah pengalaman dengan menjembatani kesenjangan antara maksud dan hasil pengguna. Dengan memanfaatkan kekuatan pencarian metadata dan vektor, ini memberikan hasil pencarian yang lebih akurat, relevan, dan efisien.
Baik Anda sedang membangun platform e-niaga, sistem rekomendasi konten, atau aplikasi apa pun yang mengandalkan penelusuran efektif, menggabungkan Pemfilteran Cerdas dapat meningkatkan kepuasan pengguna secara signifikan dan mendorong hasil yang lebih baik.
Dengan memahami dasar-dasar Smart Filtering, Anda diperlengkapi untuk mengeksplorasi potensinya dan menerapkannya dalam proyek Anda. Jadi mengapa menunggu? Mulailah memanfaatkan kekuatan Pemfilteran Cerdas hari ini dan merevolusi permainan pencarian Anda!
Terinspirasi oleh Self Query Retriever LangChain.


