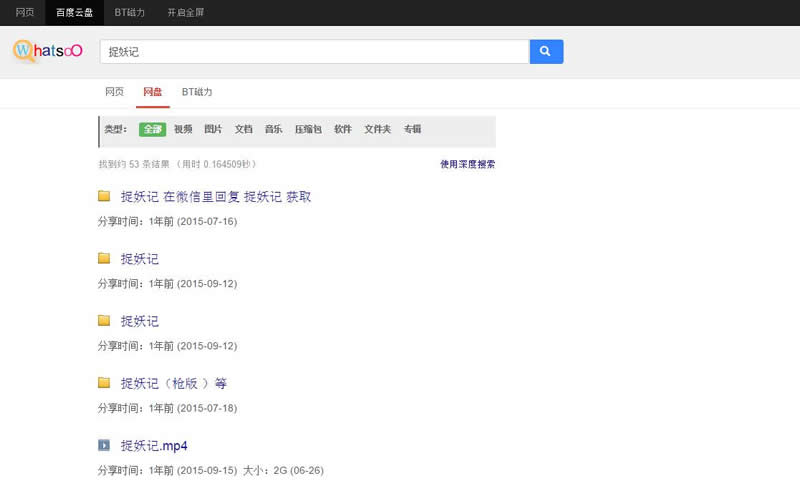
Mesin pencari disk jaringan cloud Baidu v1.0
v0
Mesin pencari disk jaringan cloud Baidu adalah kode sumber mesin pencari disk jaringan yang dikembangkan dengan PHP+MySQL. Lingkungan berjalan: Sebelum memulai, Anda perlu menginstal *PHP5.3.7+*MySQL*Python2.7~*[xunsearch](http://xunsearch.com/) Struktur direktori proyek mesin pencari ___ kira-kira seperti ini- -- pengindeks/#index---spider/#crawler---sql/---web/#situs web---aplikasi/---config/#terkait konfigurasi---config.php---database. php#Konfigurasi database... ---static/# Menyimpan sumber daya statis, css|js|font---system/---index.php Mulai penerapan Buat database Buat database bernama `pan`, dan setel pengkodean ke `utf-8`. Kemudian impor `sql` untuk menyelesaikan pembuatan tabel. Penerapan situs web mendukung server `nginx` dan `apache`. __apache__ perlu mengaktifkan *mod_rewrite*. __nginx__ dikonfigurasi sebagai berikut location/{indexindex.php;try_files$uri$uri//index.php/$uri;}
lokasi~[^/].php(/|$){fastcgi_pass127.0.0.1:9000;fastcgi_indexindex.php;includefastcgi.conf;includepathinfo.conf;}
Modifikasi file konfigurasi: File `config.php` mengubah judul situs web, deskripsi, dan informasi lainnya `database.php` mengubah akun database, kata sandi, dan informasi lainnya> Situs web dikembangkan berdasarkan kerangka CodeIgniter , atau pengembangan sekunder, Silakan merujuk ke [Dokumentasi Resmi](http://codeigniter.org.cn/user_guide/general/welcome.html)###Mulai crawler dan masuk ke direktori `spider/`, dan ubah database informasi di `spider.py`.
Jika ini adalah penerapan pertama Anda, Anda perlu menjalankan perintah berikut untuk menyelesaikan penyemaian: pythonspider.py --seed-user Hal di atas sebenarnya untuk menangkap informasi relevan dari pengguna berbagi populer Baidu Cloud, dan kemudian mulai merayapi data dari mereka lalu jalankan pythonspider .py Pada titik ini crawler sudah mulai bekerja ###Instalasi xunsearch saat ini menggunakan __xunsearch__ sebagai mesin pencari, yang nantinya akan digantikan oleh `elasticsearch`. Silakan lihat proses instalasi (tidak perlu instalasi, PHPSDK, saya sudah mengintegrasikannya ke web) http://xunsearch.com/doc/php/guide/start.installation###Index data Di atas kami telah menyelesaikan data crawler capture, website sudah dibangun, namun belum bisa dicari, mari kita mulai langkah terakhir yaitu pembuatan indeks. Masuk ke direktori `indexer/`, ganti $prefix di `indexer.php` dengan jalur root web Anda require'$prefix/application/helpers/xs/lib/XS.php'; jalankan python./index.php