genkitx hnsw
1.0.0

Anda dapat berkontribusi pada plugin ini di Repositori ini.
HNSW adalah grafik Vector Database Hierarchical Navigable Small World (HNSW) yang merupakan salah satu indeks berkinerja terbaik untuk pencarian kesamaan vektor. HNSW adalah teknologi yang sangat populer yang berkali-kali menghasilkan kinerja tercanggih dengan kecepatan pencarian super cepat dan perolehan yang luar biasa. pelajari lebih lanjut tentang HNSW.
Anda dapat memilih database vektor ini jika Anda mau
Dengan ini, Anda dapat mencapai Retrieval Augmentation Generation (RAG) berperforma tinggi di AI Generatif sehingga Anda tidak perlu membuat Model AI sendiri atau melatih ulang Model AI untuk mendapatkan lebih banyak konteks atau pengetahuan, melainkan Anda dapat menambahkan lapisan konteks tambahan sehingga Model AI Anda dapat memahami lebih banyak pengetahuan daripada yang diketahui oleh Model AI dasar. ini berguna jika Anda ingin mendapatkan lebih banyak konteks atau lebih banyak pengetahuan berdasarkan informasi atau pengetahuan spesifik yang Anda definisikan.
Anda memiliki aplikasi atau website Restoran, Anda dapat menambahkan informasi spesifik tentang restoran Anda, alamat, daftar menu makanan beserta harganya dan hal-hal spesifik lainnya, sehingga ketika pelanggan Anda menanyakan sesuatu kepada AI tentang Restoran Anda, AI Anda dapat menjawabnya dengan akurat. . ini dapat menghilangkan usaha Anda untuk membangun Chatbot, sebaliknya Anda dapat menggunakan AI Generatif yang diperkaya dengan pengetahuan khusus.
Contoh percakapan :
You : Berapa daftar harga restoran saya di Kota Surabaya?
AI : Daftar Harga :
Sebelum menginstal plugin, pastikan Anda telah menginstal prasyarat berikut:
npm install -g typescript )Untuk menginstal plugin ini, Anda dapat menjalankan perintah ini atau dengan manajer paket pilihan Anda
npm install genkitx-hnswPlugin ini memiliki beberapa fungsi seperti di bawah ini:
HNSW Indexer Digunakan untuk membuat Indeks Vektor berdasarkan semua data dan informasi yang Anda berikan. Indeks Vektor ini akan digunakan sebagai referensi pengetahuan HNSW Retriever.HNSW Retriever Digunakan untuk mendapatkan respons AI Generatif dengan Model Gemini sebagai basis yang diperkaya dengan pengetahuan dan konteks tambahan berdasarkan Indeks Vektor Anda. Ini adalah penggunaan aliran plugin Genkit untuk menyimpan data ke penyimpanan vektor dengan HNSW Vector Store, Gemini Embedder dan Gemini LLM.
Siapkan data atau dokumen anda dalam sebuah Folder 
Impor plugin ke proyek Genkit Anda
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; Buka Genkit UI dan pilih plugin HNSW Indexer yang terdaftar
Jalankan aliran dengan parameter Input dan Output yang diperlukan
dataPath : Jalur data Anda dan dokumen lain yang akan dipelajari oleh AIindexOutputPath : Jalur keluaran yang Anda harapkan untuk Indeks Penyimpanan Vektor Anda yang diproses berdasarkan data dan dokumen yang Anda berikan 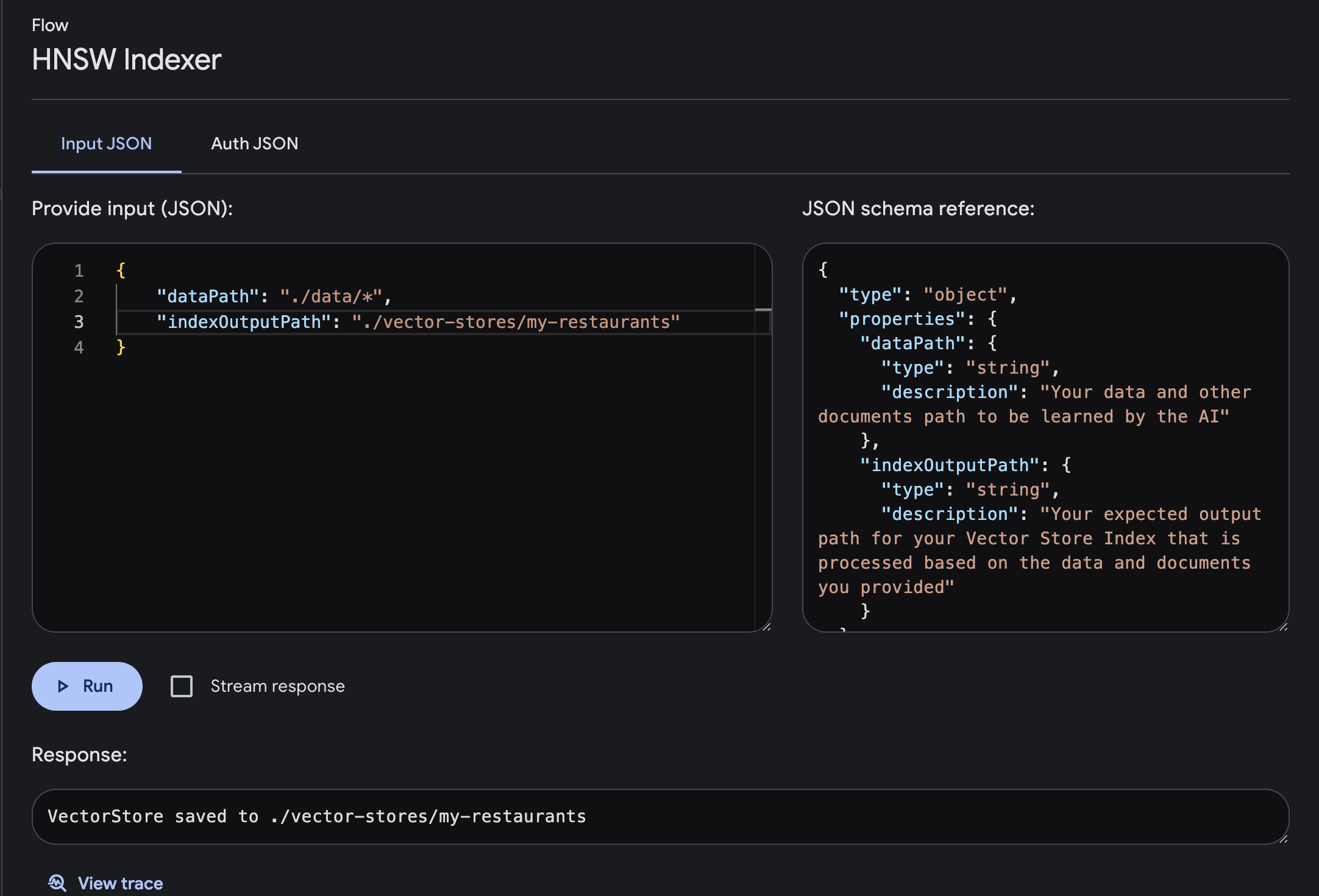
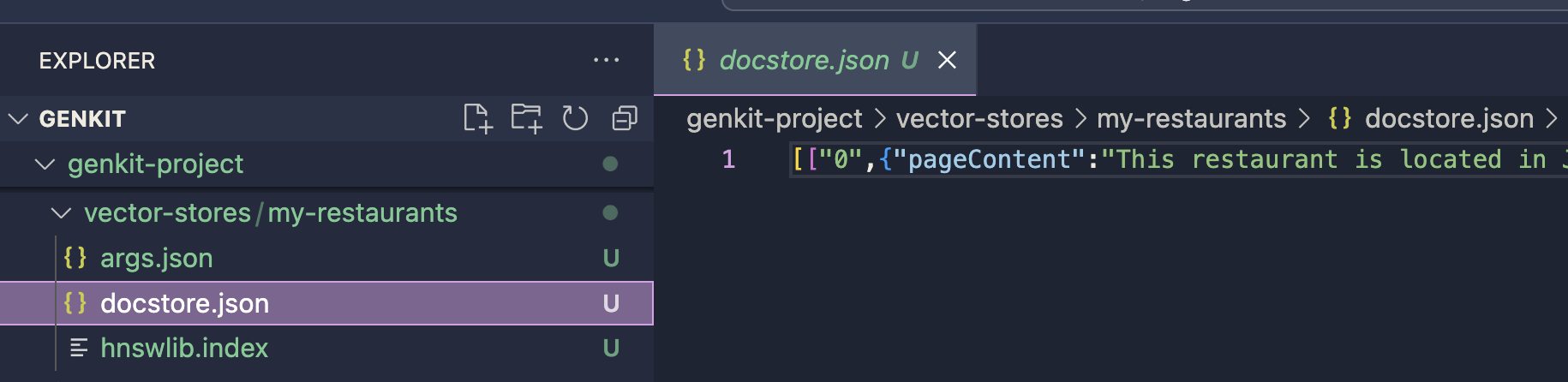 Penyimpanan vektor akan disimpan di jalur keluaran yang ditentukan. indeks ini akan digunakan untuk proses pembuatan prompt dengan plugin HNSW Retriever. Anda dapat melanjutkan penerapannya dengan menggunakan plugin HNSW Retriever
Penyimpanan vektor akan disimpan di jalur keluaran yang ditentukan. indeks ini akan digunakan untuk proses pembuatan prompt dengan plugin HNSW Retriever. Anda dapat melanjutkan penerapannya dengan menggunakan plugin HNSW Retriever
chunkSize: number Berapa banyak data yang diproses dalam satu waktu. Ini seperti memecah tugas besar menjadi bagian-bagian kecil agar lebih mudah dikelola. Dengan menetapkan ukuran potongan, kami memutuskan berapa banyak informasi yang ditangani AI sekaligus, yang dapat memengaruhi kecepatan dan keakuratan proses pembelajaran AI.
default value : 12720
separator: string Selama pembuatan indeks vektor adalah simbol atau karakter yang digunakan untuk memisahkan berbagai informasi dalam data masukan. Hal ini membantu AI memahami di mana satu unit data berakhir dan unit data lainnya dimulai, sehingga memungkinkannya memproses dan belajar dari data dengan lebih efektif.
default value : "n"
Ini adalah penggunaan alur plugin Genkit untuk memproses permintaan Anda dengan Model Gemini LLM yang diperkaya dengan informasi atau pengetahuan tambahan dan spesifik dalam Database Vektor HNSW yang Anda berikan. dengan plugin ini Anda akan mendapatkan respon LLM dengan konteks tambahan yang spesifik.
Impor plugin ke proyek Genkit Anda
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;Pastikan Anda mengimpor plugin GoogleAI untuk penyedia Model Gemini LLM, saat ini plugin ini hanya mendukung Gemini, akan segera menyediakan lebih banyak model!
Buka Genkit UI dan pilih Plugin HNSW Retriever yang terdaftar. Jalankan alur dengan parameter yang diperlukan
prompt : Ketikkan prompt Anda di mana Anda akan mendapatkan jawaban dengan konteks yang lebih kaya berdasarkan vektor yang Anda berikan.indexPath : Tentukan jalur Indeks Vektor folder yang ingin Anda gunakan sebagai referensi pengetahuan, tempat Anda mendapatkan jalur file ini dari plugin HNSW Indexer.Pada contoh ini, mari kita coba bertanya tentang informasi daftar harga sebuah restoran di kota Surabaya yang sudah tersedia dalam Vector Index.
Kita dapat mengetikkan prompt dan menjalankannya, setelah alur selesai, Anda akan mendapatkan respon yang diperkaya dengan pengetahuan spesifik berdasarkan Indeks Vektor Anda.
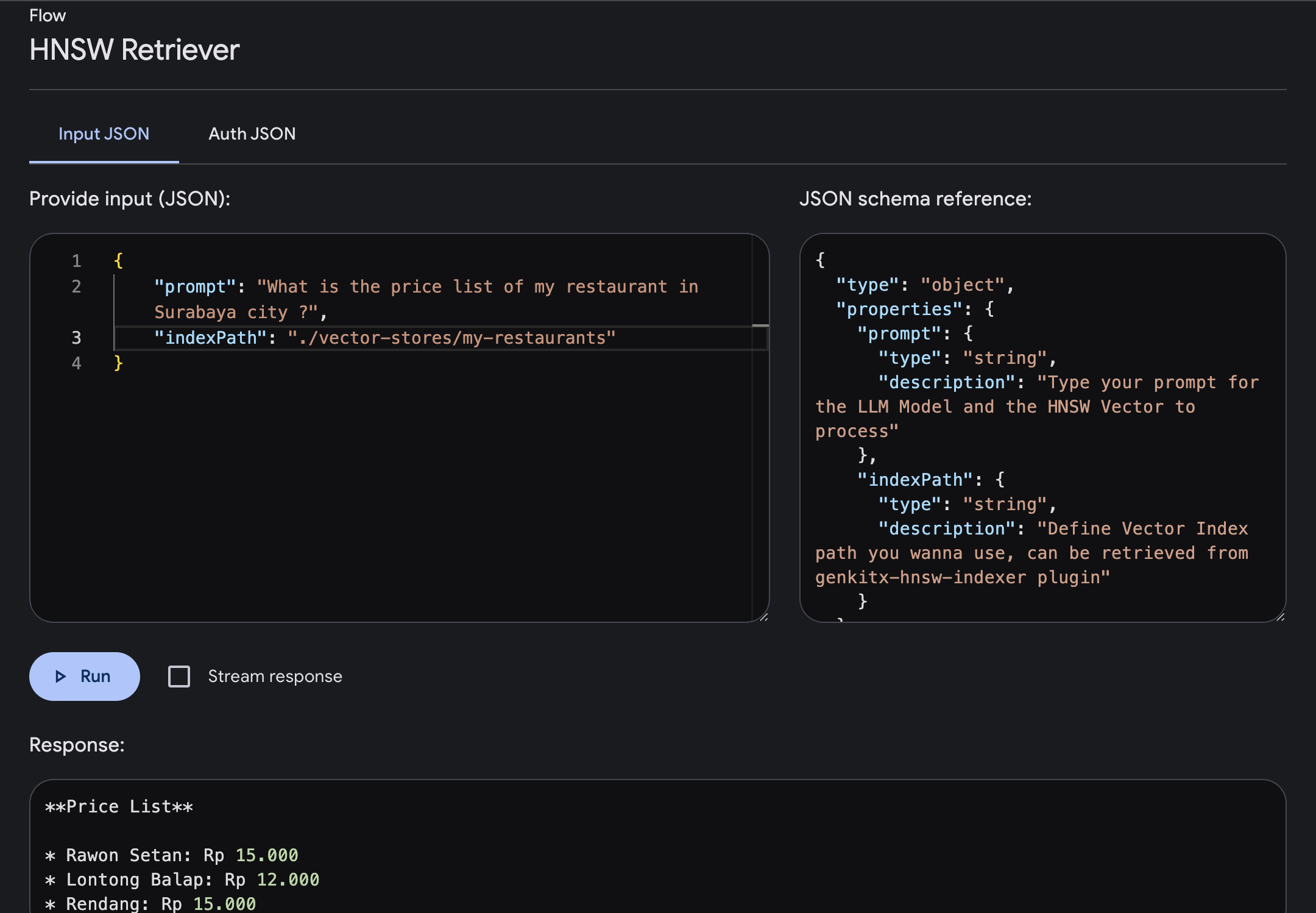
temperature: number mengontrol keacakan keluaran yang dihasilkan. Temperatur yang lebih rendah menghasilkan keluaran yang lebih deterministik, dengan model memilih token yang paling mungkin pada setiap langkah. Temperatur yang lebih tinggi meningkatkan keacakan, memungkinkan model mengeksplorasi token yang lebih kecil kemungkinannya, sehingga berpotensi menghasilkan teks yang lebih kreatif namun kurang koheren.
default value : 0.1
maxOutputTokens: number Parameter ini menentukan jumlah maksimum token (kata atau subkata) yang harus dihasilkan model dalam satu langkah inferensi. Ini membantu mengontrol panjang teks yang dihasilkan.
default value : 500
topK: number Pengambilan sampel Top-K membatasi pilihan model pada K teratas yang kemungkinan besar merupakan token di setiap langkah. Hal ini membantu mencegah model mempertimbangkan token yang terlalu langka atau tidak mungkin, sehingga meningkatkan koherensi teks yang dihasilkan.
default value : 1
topP: number Pengambilan sampel Top-P, juga dikenal sebagai pengambilan sampel inti, mempertimbangkan distribusi probabilitas kumulatif dari token dan memilih kumpulan token terkecil yang probabilitas kumulatifnya melebihi ambang batas yang telah ditentukan (sering dilambangkan dengan P). Hal ini memungkinkan pemilihan dinamis jumlah token yang dipertimbangkan pada setiap langkah, bergantung pada kemungkinan token tersebut.
default value : 0
stopSequences: string[] Ini adalah urutan token yang, ketika dihasilkan, memberi sinyal pada model untuk berhenti menghasilkan teks. Hal ini dapat berguna untuk mengontrol panjang atau konten keluaran yang dihasilkan, seperti memastikan model berhenti menghasilkan setelah mencapai akhir kalimat atau paragraf.
default value : []
Lisensi: Apache 2.0


