content dicovery platform gcp
1.0.0
Repositori ini berisi kode dan otomatisasi yang diperlukan untuk membangun platform penemuan konten sederhana yang didukung oleh model dasar VertexAI. Platform ini harus mampu menangkap konten dokumen (awalnya Google Docs), dan dengan konten tersebut menghasilkan vektor penyematan untuk disimpan dalam database vektor yang didukung oleh VertexAI Matching Engine, nantinya penyematan ini dapat digunakan untuk mengontekstualisasikan pertanyaan umum konsumen eksternal dan dengan konteks tersebut meminta jawaban terhadap model dasar VertexAI untuk mendapatkan jawaban.
Platform ini dapat dipisahkan dalam 4 komponen utama, lapisan layanan akses, saluran pengambilan konten, penyimpanan konten, dan LLM. Lapisan layanan memungkinkan konsumen eksternal untuk mengirimkan permintaan penyerapan dokumen dan kemudian mengirimkan pertanyaan tentang konten yang disertakan dalam dokumen yang diserap sebelumnya. Saluran pengambilan konten bertugas menangkap konten dokumen di NRT, mengekstrak penyematan, dan memetakan penyematan tersebut dengan konten nyata yang nantinya dapat digunakan untuk mengontekstualisasikan pertanyaan pengguna eksternal ke LLM. Penyimpanan konten dipisahkan dalam 3 tujuan berbeda, penyempurnaan LLM, pencocokan penyematan online, dan konten yang dipotong, masing-masing ditangani oleh sistem penyimpanan khusus dan dengan tujuan umum menyimpan informasi yang diperlukan oleh komponen platform untuk mengimplementasikan penyerapan dan kueri menggunakan kasus. Yang terakhir, platform ini menggunakan 2 LLM khusus untuk membuat penyematan waktu nyata dari konten dokumen yang diserap dan satu lagi yang bertugas menghasilkan jawaban yang diminta oleh pengguna platform.
Semua komponen yang dijelaskan sebelumnya diimplementasikan menggunakan layanan GCP yang tersedia untuk umum. Untuk menghitungnya: Cloud Build, Cloud Run, Cloud Dataflow, Cloud Pubsub, Cloud Storage, Cloud Bigtable, Vertex AI Matching Engine, model Dasar Vertex AI (embeddings dan text-bison), bersama dengan Google Docs dan Google Drive sebagai informasi konten sumber.
Gambar berikutnya menunjukkan bagaimana berbagai komponen arsitektur dan teknologi berinteraksi satu sama lain.
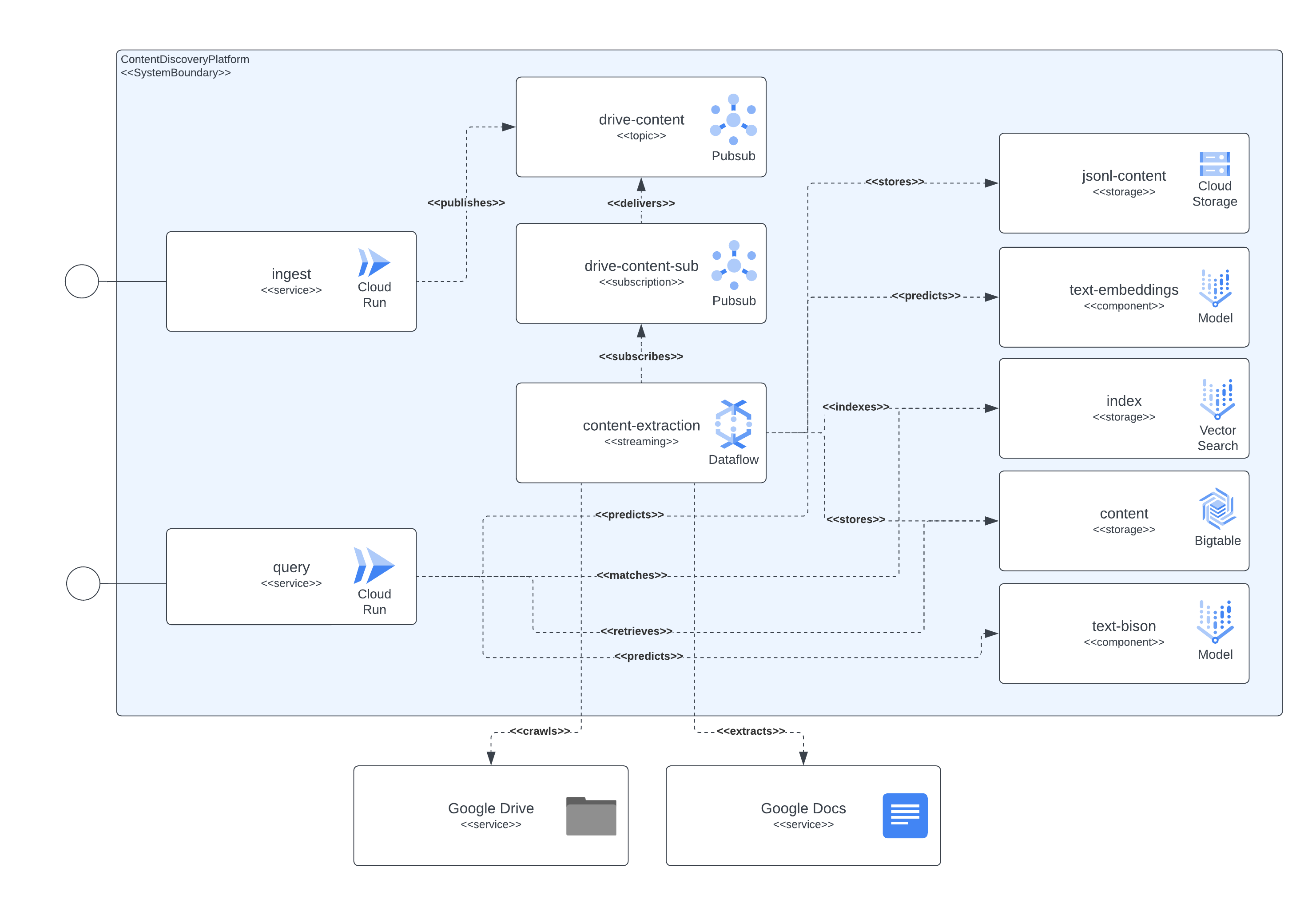
Platform ini menggunakan Terraform untuk setup semua komponennya. Bagi mereka yang saat ini tidak memiliki dukungan asli, kami telah membuat pembungkus null_resource, ini adalah solusi yang baik tetapi cenderung memiliki sisi yang sangat kasar jadi waspadalah terhadap potensi kesalahan.
Penerapan lengkap mulai hari ini (Juni 2023) dapat memakan waktu hingga 90 menit untuk diselesaikan, penyebab terbesarnya adalah komponen terkait Mesin Pencocokan yang menghabiskan sebagian besar waktu tersebut untuk dibuat dan tersedia. Seiring berjalannya waktu, waktu proses yang diperpanjang ini akan semakin membaik.
Penyiapan harus dapat dijalankan dari skrip yang disertakan dalam repositori.
Ada beberapa persyaratan yang harus dipenuhi untuk menerapkan platform ini, yaitu:
Agar semua komponen dapat diterapkan di GCP, kita perlu membangun, membuat infrastruktur, dan kemudian menerapkan layanan dan pipeline.
Untuk mencapai hal ini kami menyertakan skrip start.sh yang pada dasarnya mengatur skrip lain yang disertakan untuk mencapai tujuan penerapan penuh.
Kami juga telah menyertakan skrip cleanup.sh yang bertugas menghancurkan infrastruktur dan membersihkan data yang dikumpulkan.
Dalam kasus normal, dokumen Google Workspace akan dibuat di organisasi yang sama yang menghosting proyek tempat pipeline penyerapan konten dijalankan, jadi untuk memberikan izin pada dokumen tersebut, tambahkan akun layanan yang menjalankan pipeline ke dokumen, atau folder dokumen , seharusnya cukup.
Jika perlu mengakses dokumen atau folder yang ada di luar organisasi proyek, langkah tambahan harus diselesaikan. Setelah infrastruktur disiapkan, proses penerapan akan mencetak petunjuk untuk memberikan izin kepada akun layanan yang menjalankan pipeline ekstraksi konten untuk meniru akses dokumen Google Workspace melalui delegasi seluruh domain. Informasi untuk menyelesaikan langkah-langkahnya dapat dilihat di sini: https://developers.google.com/workspace/guides/create-credentials#optional_set_up_domain-wide_delegation_for_a_service_account
Solusi ini memaparkan beberapa resource melalui GCP CloudRun dan API Gateway, yang dapat digunakan untuk berinteraksi dalam penyerapan konten dan kueri penemuan konten. Dalam semua contoh, kami menggunakan string <service-address> simbolis, yang harus diganti dengan URL yang disediakan oleh CloudRun ( backend_service_url dari keluaran Terraform) atau API Gateway ( sevice_url dari keluaran Terraform) setelah penerapan layanan selesai.
Saat memerlukan interaksi CORS, titik akhir API Gateway dapat digunakan saat ingin menyelesaikan protokol pra-penerbangan. CloudRun saat ini tidak mendukung perintah OPTIONS yang tidak diautentikasi, namun jalur yang diekspos melalui API Gateway mendukung perintah tersebut.
Layanan ini mampu menyerap data dari dokumen yang dihosting di Google Drive atau permintaan multi-bagian mandiri yang berisi pengidentifikasi dokumen dan konten dokumen yang dikodekan sebagai biner.
Penyerapan Google Drive dilakukan dengan mengirimkan permintaan HTTP serupa dengan contoh berikutnya
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' Permintaan ini akan menunjukkan platform untuk mengambil dokumen dari url yang disediakan dan jika akun layanan yang menjalankan penyerapan memiliki izin akses ke dokumen tersebut, maka ia akan mengekstraksi konten dari dokumen tersebut dan menyimpan informasi untuk pengindeksan, kemudian ditemukan dan diambil.
Permintaan dapat berisi url dokumen Google atau folder Google Drive, dalam kasus terakhir penyerapan akan merayapi folder tersebut untuk diproses oleh dokumen. Selain itu, dimungkinkan untuk menggunakan urls properti yang mengharapkan JSONArray nilai string , yang masing-masing merupakan url Dokumen Google yang valid.
Jika ingin memasukkan konten artikel, dokumen, atau halaman yang dapat diakses secara lokal oleh klien penyerapan, penggunaan titik akhir multibagian sudah cukup untuk menyerap dokumen. Lihat perintah curl berikutnya sebagai contoh, layanan mengharapkan kolom formulir documentId diatur untuk mengidentifikasi dan mengindeks konten secara univokal:
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartLayanan ini memaparkan kemampuan kueri kepada pengguna platform, dengan mengirimkan kueri teks alami ke layanan dan mengingat sudah ada indeks konten setelah penyerapan di platform, layanan akan kembali dengan informasi yang dirangkum melalui model LLM.
Interaksi dengan layanan dapat dilakukan melalui pertukaran REST, mirip dengan bagian penyerapan, seperti yang terlihat pada contoh berikutnya.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}Ada kasus khusus di sini, ketika belum ada informasi yang disimpan untuk topik tertentu, jika topik tersebut termasuk dalam lanskap GCP maka model akan bertindak sebagai pakar karena kami menyiapkan perintah yang menunjukkan hal tersebut pada permintaan model.
Jika ingin memiliki jenis pertukaran yang lebih sadar konteks dengan layanan, pengidentifikasi sesi ( properti sessionId dalam permintaan JSON) harus disediakan agar layanan dapat digunakan sebagai kunci pertukaran percakapan. Kunci percakapan ini akan digunakan untuk menyiapkan konteks yang tepat pada model (dengan merangkum pertukaran sebelumnya) dan melacak 5 pertukaran terakhir (setidaknya). Perlu diperhatikan juga bahwa riwayat pertukaran akan dipertahankan selama 24 jam, hal ini dapat diubah sebagai bagian dari kebijakan gc penyimpanan BigTable di platform.
Berikut contoh percakapan sadar konteks:
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

