build your local ragstack chatbot
1.0.0
Selamat datang di lokakarya ini untuk membangun dan menerapkan Co-Pilot Perusahaan Anda sendiri menggunakan Retrieval Augmented Generation dengan DataStax Enterprise v7, inferensi lokal dan Mistral, Model Bahasa Besar lokal dan terbuka.
Repositori ini berfokus pada keselamatan dan keamanan dengan menyimpan data sensitif Anda di dalam firewall!
Mengapa?
Ini memanfaatkan DataStax RAGStack, yang merupakan tumpukan perangkat lunak sumber terbuka terbaik untuk memudahkan penerapan pola RAG dalam aplikasi siap produksi yang menggunakan DataStax Enterprise, Astra Vector DB, atau Apache Cassandra sebagai penyimpanan vektor.
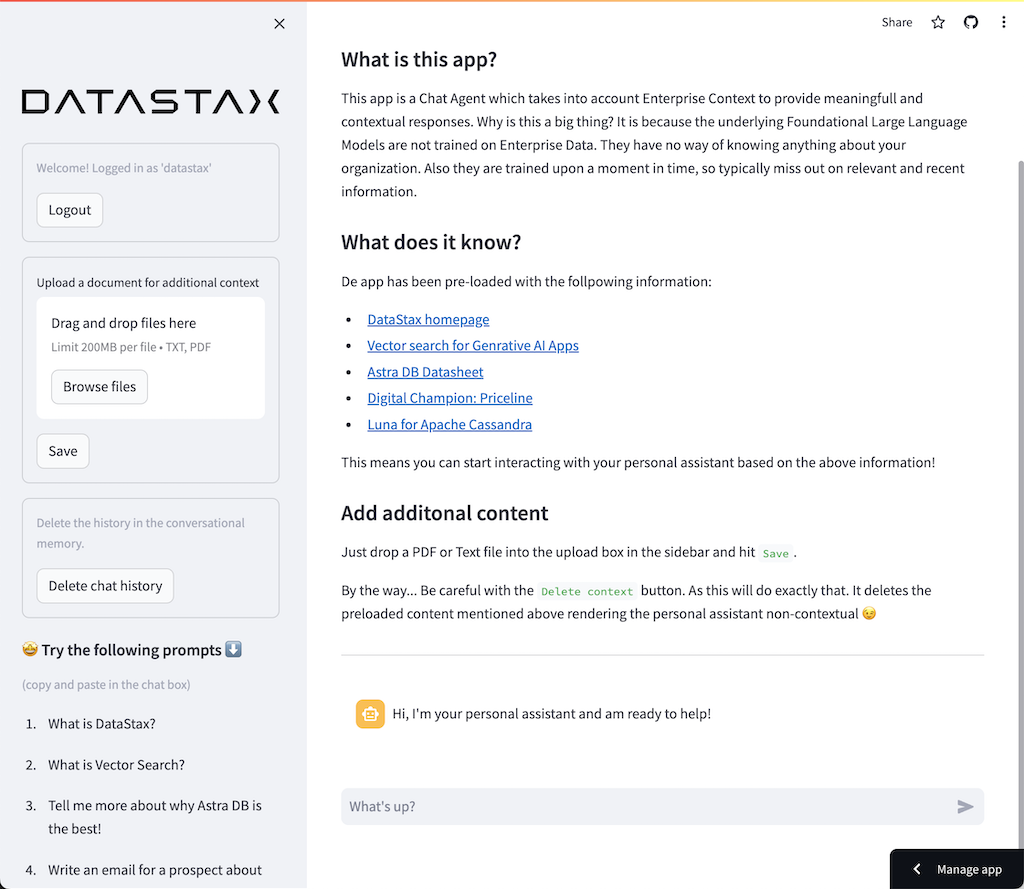
Apa yang akan Anda pelajari:
? Cara memanfaatkan DataStax RAGStack untuk penggunaan komponen berikut yang siap produksi:
? Cara menggunakan Ollama sebagai mesin inferensi lokal
? Cara menggunakan Mistral sebagai Model Bahasa Besar (LLM) lokal dan terbuka untuk chatbot gaya Tanya Jawab
? Cara menggunakan Streamlit untuk menyebarkan aplikasi luar biasa Anda dengan mudah!
Slide presentasi dapat dilihat DI SINI
Lokakarya ini mengasumsikan Anda memiliki akses ke:
Pada langkah selanjutnya kita akan menyiapkan repositori, DataStax Enterprise, Jupyter Notebook, dan Mesin Inferensi Ollama dengan Ollama.
Hal pertama, kita perlu mengkloning repositori ini ke laptop pengembangan lokal Anda.
Buka repositori build-local-ragstack-chatbot Anda
Klik Use this template -> Ceate new repository sebagai berikut:
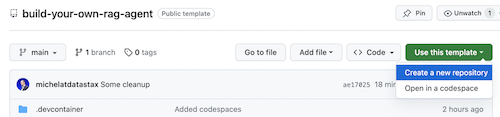
Sekarang pilih akun github Anda dan beri nama repositori baru. Idealnya juga mengatur deskripsinya. Klik Create repository
Dingin! Anda baru saja membuat salinan di akun Gihub Anda sendiri!
cd ke direktori yang masuk akal (seperti /projects atau lebih);git clone <url-to-your-repo>cd ke direktori baru Anda!Dan Anda siap beraksi! ?
Ini berguna untuk membuat Lingkungan Virtual . Gunakan yang di bawah ini untuk mengaturnya:
python3 -m venv myenv
Kemudian aktifkan sebagai berikut:
source myenv/bin/activate # on Linux/Mac
myenvScriptsactivate.bat # on Windows
Sekarang Anda dapat mulai menginstal paket yang diperlukan:
pip3 install -r requirements.txt
Jalankan DSE 7 dengan salah satu dari dua cara berikut dari jendela terminal baru:
docker-compose up
Ini menggunakan file docker-compose.yml di root repositori ini yang juga akan dengan mudah memulai Jupyter Interpreter.
DataStax akan berjalan di http://localhost:9042 dan Jupyter akan dapat diakses dengan menjelajah ke http://localhost:8888
Ada banyak mesin inferensi. Anda bisa menggunakan LM Studio yang memiliki UI yang bagus. Di notebook ini, kita akan menggunakan Ollama.
ollama run mistral di jendela terminal baruJika semuanya gagal, karena keterbatasan RAM, Anda dapat memilih untuk menggunakan tinyllama sebagai model.
Untuk memulai lokakarya ini, pertama-tama kita akan mencoba konsep-konsep dalam buku catatan yang disediakan. Kami berasumsi Anda akan menjalankan dari dalam Jupyter Docker Container, jika tidak, harap ubah nama host dari host.docker.internal menjadi localhost .
Buku catatan ini memperlihatkan langkah-langkah yang harus diambil untuk menggunakan DataStax Enterprise Vector Store sebagai sarana untuk membuat interaksi LLM bermakna dan tanpa halusinasi. Pendekatan yang dilakukan disini adalah Retrieval Augmented Generation.
Anda akan belajar:
Telusuri ke http://localhost:8888 dan buka notebook yang tersedia di root bernama Build_Your_Own_RAG_Meetup.ipnb .
Dalam lokakarya ini kita akan menggunakan Streamlit yang merupakan kerangka kerja yang sangat mudah digunakan untuk membuat aplikasi web front-end.
Untuk memulainya, mari kita buat aplikasi hello world sebagai berikut:
import streamlit as st
# Draw a title and some markdown
st . markdown ( """# Your Enterprise Co-Pilot
Generative AI is considered to bring the next Industrial Revolution.
Why? Studies show a **37% efficiency boost** in day to day work activities!
### Security and safety
This Chatbot is safe to work with sensitive data. Why?
- First of all it makes use of [Ollama, a local inference engine](https://ollama.com);
- On top of the inference engine, we're running [Mistral, a local and open Large Language Model (LLM)](https://mistral.ai/);
- Also the LLM does not contain any sensitive or enterprise data, as there is no way to secure it in a LLM;
- Instead, your sensitive data is stored securely within the firewall inside [DataStax Enterprise v7 Vector Database](https://www.datastax.com/blog/get-started-with-the-datastax-enterprise-7-0-developer-vector-search-preview);
- And lastly, the chains are built on [RAGStack](https://www.datastax.com/products/ragstack), an enterprise version of Langchain and LLamaIndex, supported by [DataStax](https://www.datastax.com/).""" )
st . divider () Langkah pertama adalah mengimpor paket streamlit. Kemudian kita memanggil st.markdown untuk menulis judul dan terakhir kita menulis beberapa konten ke halaman web.
Untuk memulai aplikasi ini secara lokal, Anda perlu menginstal dependensi streamlit sebagai berikut (yang seharusnya sudah dilakukan sebagai bagian dari prasyarat):
pip install streamlitSekarang jalankan aplikasinya:
streamlit run app_1.pyIni akan memulai server aplikasi dan membawa Anda ke halaman web yang baru saja Anda buat.
Sederhana, bukan? ?
Pada langkah ini kita akan mulai mempersiapkan aplikasi untuk memungkinkan interaksi chatbot dengan pengguna. Kita akan menggunakan komponen Streamlit berikut: 1. 2. st.chat_input agar pengguna dapat memasukkan pertanyaan 2. st.chat_message('human') untuk menarik masukan pengguna 3. st.chat_message('assistant') untuk menarik respons chatbot
Ini menghasilkan kode berikut:
# Draw the chat input box
if question := st . chat_input ( "What's up?" ):
# Draw the user's question
with st . chat_message ( 'human' ):
st . markdown ( question )
# Generate the answer
answer = f"""You asked: { question } """
# Draw the bot's answer
with st . chat_message ( 'assistant' ):
st . markdown ( answer ) Cobalah menggunakan app_2.py dan mulai sebagai berikut.
Jika aplikasi Anda sebelumnya masih berjalan, matikan saja dengan menekan ctrl-c terlebih dahulu.
streamlit run app_2.pySekarang ketikkan sebuah pertanyaan, dan ketikkan pertanyaan lainnya lagi. Anda akan melihat bahwa hanya pertanyaan terakhir yang disimpan.
Mengapa???
Ini karena Streamlit akan menggambar ulang seluruh layar berulang kali berdasarkan masukan terbaru. Karena kami tidak mengingat pertanyaannya, hanya pertanyaan terakhir yang ditampilkan.
Pada langkah ini kami akan memastikan untuk melacak pertanyaan dan jawaban sehingga setiap kali menggambar ulang, riwayatnya ditampilkan.
Untuk melakukan ini, kami akan mengambil langkah berikutnya:
st.session_state yang disebut messagesst.session_state yang disebut messagesfor message in st.session_state.messages Pendekatan ini berhasil karena session_state bersifat stateful di seluruh proses Streamlit.
Lihat kode lengkapnya di app_3.py.
Seperti yang akan Anda lihat, kami menggunakan kamus untuk menyimpan role (yang dapat berupa Manusia atau AI) dan question atau answer . Melacak peran itu penting karena akan memberikan gambaran yang tepat di browser.
Jalankan dengan:
streamlit run app_3.pySekarang tambahkan beberapa pertanyaan dan Anda akan melihat ini digambar ulang di layar setiap kali Streamlit diputar ulang. ?
Di sini kami akan menautkan kembali ke pekerjaan yang kami lakukan menggunakan Jupyter Notebook dan mengintegrasikan pertanyaan dengan panggilan ke Model Obrolan Mistral.
Ingat bahwa Streamlit menjalankan kembali kode setiap kali pengguna berinteraksi? Oleh karena itu, kami akan menggunakan cache data dan sumber daya di Streamlit sehingga koneksi hanya disiapkan satu kali. Kami akan menggunakan @st.cache_data() dan @st.cache_resource() untuk mendefinisikan caching. cache_data biasanya digunakan untuk struktur data. cache_resource sebagian besar digunakan untuk sumber daya seperti database.
Ini menghasilkan kode berikut untuk menyiapkan Model Prompt dan Obrolan:
# Cache prompt for future runs
@ st . cache_data ()
def load_prompt ():
template = """You're a helpful AI assistent tasked to answer the user's questions.
You're friendly and you answer extensively with multiple sentences. You prefer to use bulletpoints to summarize.
QUESTION:
{question}
YOUR ANSWER:"""
return ChatPromptTemplate . from_messages ([( "system" , template )])
prompt = load_prompt ()
# Cache Mistral Chat Model for future runs
@ st . cache_resource ()
def load_chat_model ():
# parameters for ollama see: https://api.python.langchain.com/en/latest/chat_models/langchain_community.chat_models.ollama.ChatOllama.html
# num_ctx is the context window size
return ChatOllama (
model = "mistral:latest" ,
num_ctx = 18192 ,
base_url = st . secrets [ 'OLLAMA_ENDPOINT' ]
)
chat_model = load_chat_model ()Daripada jawaban statis yang kita gunakan pada contoh sebelumnya, sekarang kita akan beralih ke pemanggilan Chain:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'question' : lambda x : x [ 'question' ]
})
chain = inputs | prompt | chat_model
response = chain . invoke ({ 'question' : question })
answer = response . contentLihat kode lengkapnya di app_4.py.
Sebelum melanjutkan, kami harus menyediakan OLLAMA_ENDPOINT di ./streamlit/secrets.toml . Ada contoh yang disediakan di secrets.toml.example :
# Ollama/Mistral Endpoint
OLLAMA_ENDPOINT = " http://localhost:11434 "Untuk memulai aplikasi ini secara lokal, Anda perlu menginstal RAGStack yang berisi versi stabil LangChain dan semua dependensi (yang seharusnya sudah dilakukan sebagai bagian dari prasyarat):
pip install ragstackSekarang jalankan aplikasinya:
streamlit run app_4.pyAnda sekarang dapat memulai interaksi tanya jawab dengan Chatbot. Tentu saja, karena tidak ada integrasi dengan DataStax Enterprise Vector Store, tidak akan ada jawaban yang dikontekstualisasikan. Karena belum ada streaming bawaan, harap berikan sedikit waktu kepada agen untuk memberikan jawaban lengkap sekaligus.
Mari kita mulai dengan pertanyaan:
What does Daniel Radcliffe get when he turns 18?
Seperti yang akan Anda lihat, Anda akan menerima jawaban yang sangat umum tanpa informasi yang tersedia di data CNN.
Sekarang segalanya menjadi sangat menarik! Pada langkah ini kami akan mengintegrasikan DataStax Enterprise Vector Store untuk memberikan konteks secara real-time untuk Model Obrolan. Langkah-langkah yang diambil untuk mengimplementasikan Retrieval Augmented Generation:
Kami akan menggunakan kembali data CNN yang kami masukkan berkat buku catatan.
Untuk mengaktifkan ini, pertama-tama kita harus menyiapkan koneksi ke DataStax Enterprise Vector Store:
# Cache the DataStax Enterprise Vector Store for future runs
@ st . cache_resource ( show_spinner = 'Connecting to Datastax Enterprise v7 with Vector Support' )
def load_vector_store ():
# Connect to DSE
cluster = Cluster (
[ st . secrets [ 'DSE_ENDPOINT' ]]
)
session = cluster . connect ()
# Connect to the Vector Store
vector_store = Cassandra (
session = session ,
embedding = HuggingFaceEmbeddings (),
keyspace = st . secrets [ 'DSE_KEYSPACE' ],
table_name = st . secrets [ 'DSE_TABLE' ]
)
return vector_store
vector_store = load_vector_store ()
# Cache the Retriever for future runs
@ st . cache_resource ( show_spinner = 'Getting retriever' )
def load_retriever ():
# Get the retriever for the Chat Model
retriever = vector_store . as_retriever (
search_kwargs = { "k" : 5 }
)
return retriever
retriever = load_retriever ()Satu-satunya hal lain yang perlu kita lakukan adalah mengubah Rantai untuk menyertakan panggilan ke Toko Vektor:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'context' : lambda x : retriever . get_relevant_documents ( x [ 'question' ]),
'question' : lambda x : x [ 'question' ]
})Lihat kode lengkapnya di app_5.py.
Sebelum melanjutkan, kita harus menyediakan DSE_ENDPOINT , DSE_KEYSPACE dan DSE_TABLE di ./streamlit/secrets.toml . Ada contoh yang disediakan di secrets.toml.example :
# DataStax Enterprise Endpoint
DSE_ENDPOINT = " localhost "
DSE_KEYSPACE = " default_keyspace "
DSE_TABLE = " dse_vector_table "Dan jalankan aplikasinya:
streamlit run app_5.pyMari kita kembali bertanya:
What does Daniel Radcliffe get when he turns 18?
Seperti yang akan Anda lihat, sekarang Anda akan menerima jawaban yang sangat kontekstual karena Vector Store menyediakan data CNN yang relevan ke Model Obrolan.
Betapa kerennya melihat jawabannya muncul di layar saat dihasilkan! Ya, itu mudah.
Pertama-tama, kami akan membuat Streaming Call Back Handler yang dipanggil pada setiap pembuatan token baru sebagai berikut:
# Streaming call back handler for responses
class StreamHandler ( BaseCallbackHandler ):
def __init__ ( self , container , initial_text = "" ):
self . container = container
self . text = initial_text
def on_llm_new_token ( self , token : str , ** kwargs ):
self . text += token
self . container . markdown ( self . text + "▌" )Kemudian kami menjelaskan Model Obrolan untuk menjadikan pengguna StreamHandler:
response = chain . invoke ({ 'question' : question }, config = { 'callbacks' : [ StreamHandler ( response_placeholder )]}) response_placeholer pada kode di atas menentukan tempat di mana token perlu ditulis. Kita dapat membuat ruang tersebut dengan callint st.empty() sebagai berikut:
# UI placeholder to start filling with agent response
with st . chat_message ( 'assistant' ):
response_placeholder = st . empty ()Lihat kode lengkapnya di app_6.py.
Dan jalankan aplikasinya:
streamlit run app_6.pySekarang Anda akan melihat bahwa respons akan ditulis secara real-time ke jendela browser.
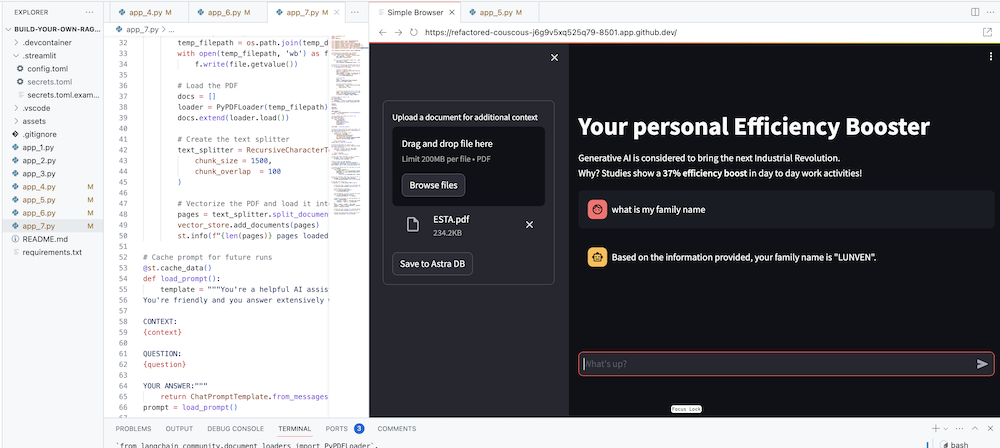
Tujuan utamanya tentu saja adalah menambahkan konteks perusahaan Anda ke agen. Untuk melakukan hal ini, kami akan menambahkan kotak unggah yang memungkinkan Anda mengunggah file PDF yang kemudian akan digunakan untuk memberikan respons yang bermakna dan kontekstual!
Pertama kita memerlukan formulir unggah yang mudah dibuat dengan Streamlit:
# Include the upload form for new data to be Vectorized
with st . sidebar :
with st . form ( 'upload' ):
uploaded_file = st . file_uploader ( 'Upload a document for additional context' , type = [ 'pdf' ])
submitted = st . form_submit_button ( 'Save to DataStax Enterprise' )
if submitted :
vectorize_text ( uploaded_file )Sekarang kita memerlukan fungsi untuk memuat PDF dan memasukkannya ke dalam DataStax Enterprise sambil membuat vektor konten.
# Function for Vectorizing uploaded data into DataStax Enterprise
def vectorize_text ( uploaded_file , vector_store ):
if uploaded_file is not None :
# Write to temporary file
temp_dir = tempfile . TemporaryDirectory ()
file = uploaded_file
temp_filepath = os . path . join ( temp_dir . name , file . name )
with open ( temp_filepath , 'wb' ) as f :
f . write ( file . getvalue ())
# Load the PDF
docs = []
loader = PyPDFLoader ( temp_filepath )
docs . extend ( loader . load ())
# Create the text splitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1500 ,
chunk_overlap = 100
)
# Vectorize the PDF and load it into the DataStax Enterprise Vector Store
pages = text_splitter . split_documents ( docs )
vector_store . add_documents ( pages )
st . info ( f" { len ( pages ) } pages loaded." )Lihat kode lengkapnya di app_7.py.
Untuk memulai aplikasi ini secara lokal, Anda perlu menginstal ketergantungan PyPDF sebagai berikut (yang seharusnya sudah dilakukan sebagai bagian dari prasyarat):
pip install pypdfDan jalankan aplikasinya:
streamlit run app_7.pySekarang unggah dokumen PDF (semakin banyak semakin bagus) yang relevan bagi Anda dan mulailah mengajukan pertanyaan tentangnya. Anda akan melihat bahwa jawabannya relevan, bermakna, dan kontekstual! ? Lihat keajaiban terjadi!