aiwhispr
version 0.941
AIWhispr adalah alat tanpa kode/rendah untuk mengotomatisasi saluran penyematan vektor untuk pencarian semantik. Konfigurasi sederhana menggerakkan alur untuk membaca file, mengekstraksi teks, membuat penyematan vektor, dan menyimpannya dalam database vektor.
AIWhispr

AIWhispr memiliki konektor untuk database vektor berikut
1 Qdran
2 Milvus
3 Weaviasi
4 Akal budi
5 MongoDB
6 Postgres - PGVektor
Harap pastikan bahwa Anda telah menginstal dan memulai database vektor Anda.
Variabel lingkungan AIWHISPR_HOME_DIR harus menjadi path lengkap ke direktori aiwhispr.
Variabel lingkungan AIWHISPR_LOG_LEVEL dapat diatur ke DEBUG / INFO / WARNING / ERROR
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
Ingatlah untuk menambahkan variabel lingkungan di skrip login shell Anda
Jalankan perintah di bawah ini
$AIWHISPR_HOME/shell/install_python_packages.sh
Jika pemasangan uwsgi gagal, pastikan Anda telah memasang gcc, python-dev, python3-dev.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr hadir dengan aplikasi sederhana untuk membantu Anda memulai.
Jalankan aplikasi streamlit
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
Ini akan memulai aplikasi streamlit pada port default 8501 dan memulai sesi di browser web Anda
Ada 3 langkah untuk mengonfigurasi alur pengindeksan konten Anda untuk pencarian semantik.
1. Konfigurasikan untuk membaca file dari lokasi penyimpanan
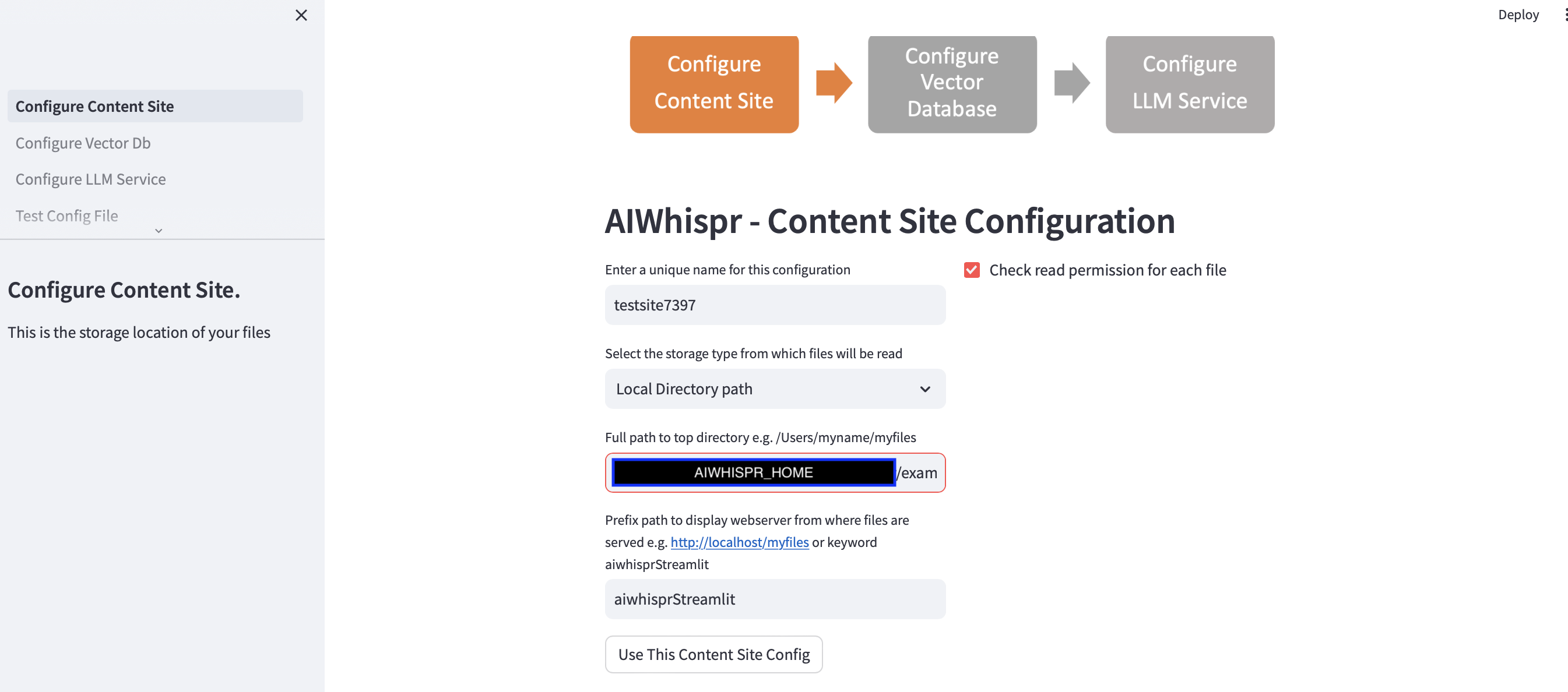
Anda dapat melanjutkan konfigurasi default dengan mengklik tombol "Gunakan Konfigurasi Situs Konten ini"
dan lanjutkan ke langkah berikutnya untuk mengonfigurasi koneksi database vektor.
Contoh default akan mengindeks berita dari BBC untuk pencarian semantik.
Aplikasi streamlit berasumsi bahwa Anda memulai konfigurasi baru dan akan menetapkan nama konfigurasi acak. Anda dapat menimpanya untuk memberinya nama yang lebih bermakna. Nama konfigurasi harus unik; tidak boleh berisi spasi putih atau karakter khusus.
Konfigurasi default akan membaca konten dari jalur direktori lokal $AIWHISPR_HOME/examples/http/bbc
Ini berisi lebih dari 2000+ berita dari BBC yang diindeks untuk pencarian semantik.
Anda dapat memilih untuk membaca konten yang disimpan di AWS S3, Azure Blob, Google Cloud Storage.
Konfigurasi jalur awalan digunakan untuk membuat tautan web href untuk hasil pencarian. Anda dapat melanjutkan dengan kata kunci default "aiwhisprStreamlit"
Klik pada tombol "Gunakan Konfigurasi Situs Konten ini" dan lanjutkan ke langkah berikutnya untuk mengonfigurasi koneksi basis data vektor dengan mengklik "Konfigurasi Db Vektor" di sidebar kiri.
2. Konfigurasikan Vektor Db
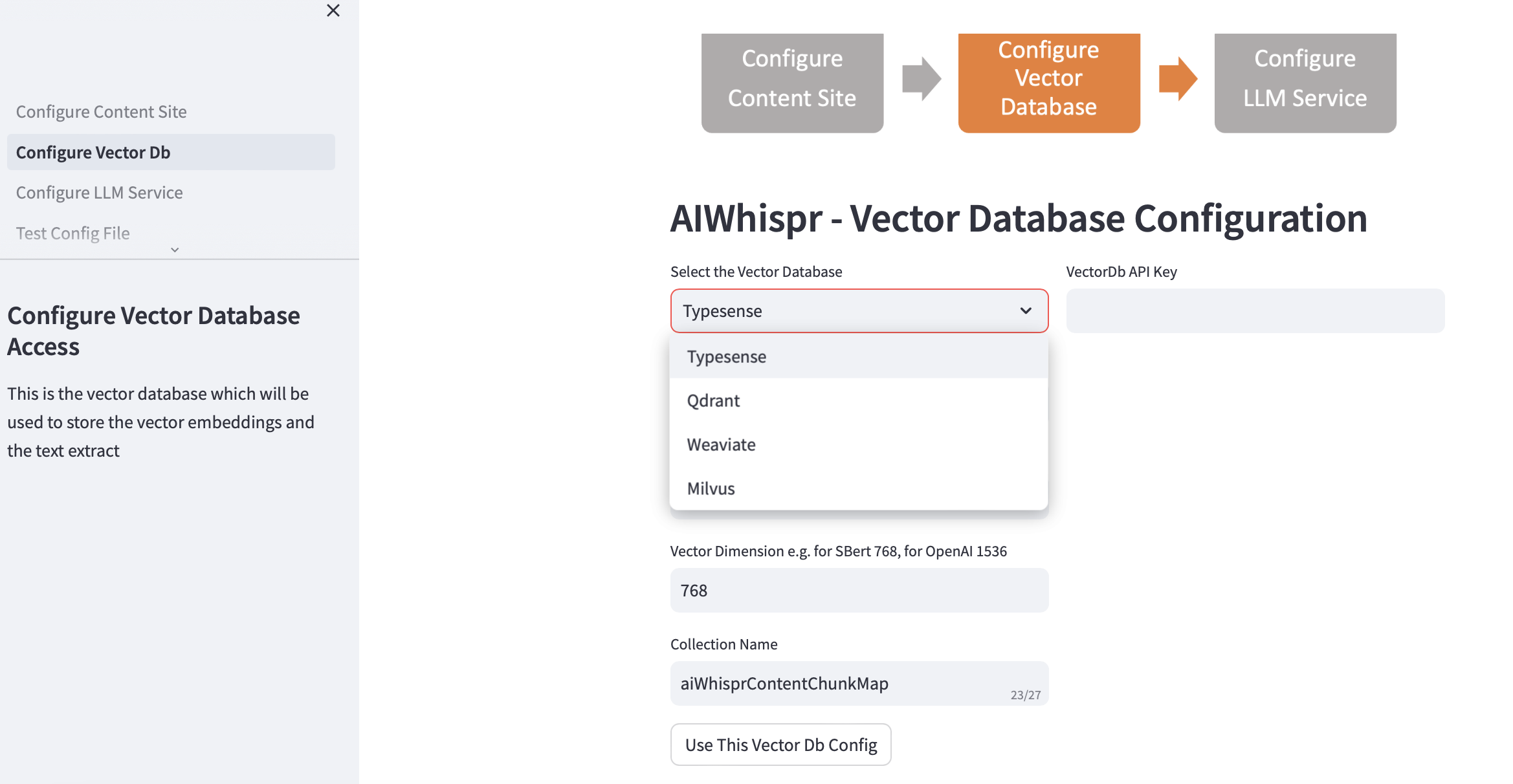
Pilih vectordb Anda dan berikan detail koneksi.
Saat Anda memilih database vektor, alamat IP Vector Db dan nomor Port diisi berdasarkan instalasi default. Anda dapat mengubahnya berdasarkan pengaturan Anda.
Basis data vektor Anda harus dikonfigurasi untuk otentikasi. Dalam kasus Qdrant, Weaviate, Typesense, Kunci API diperlukan. Untuk Milvus, user-id, kombinasi kata sandi harus dikonfigurasi.
Ukuran dimensi vektor harus ditentukan berdasarkan LLM yang ingin Anda gunakan untuk menyandikan teks sebagai penyematan vektor. Contoh: untuk Open AI "text-embedding-ada-002" ini harus dikonfigurasi sebagai 1536, yang merupakan ukuran vektor yang dikembalikan oleh layanan penyematan OpenAI.
Nama koleksi default yang dibuat dalam database vektor adalah aiwhisprContentChunkMap. Anda dapat menentukan nama koleksi Anda sendiri.
Klik pada tombol "Gunakan Konfigurasi Db Vektor Ini" dan kemudian lanjutkan ke langkah berikutnya dengan mengklik "Konfigurasi Layanan LLM" di sidebar kiri.
3. Konfigurasikan Layanan LLM
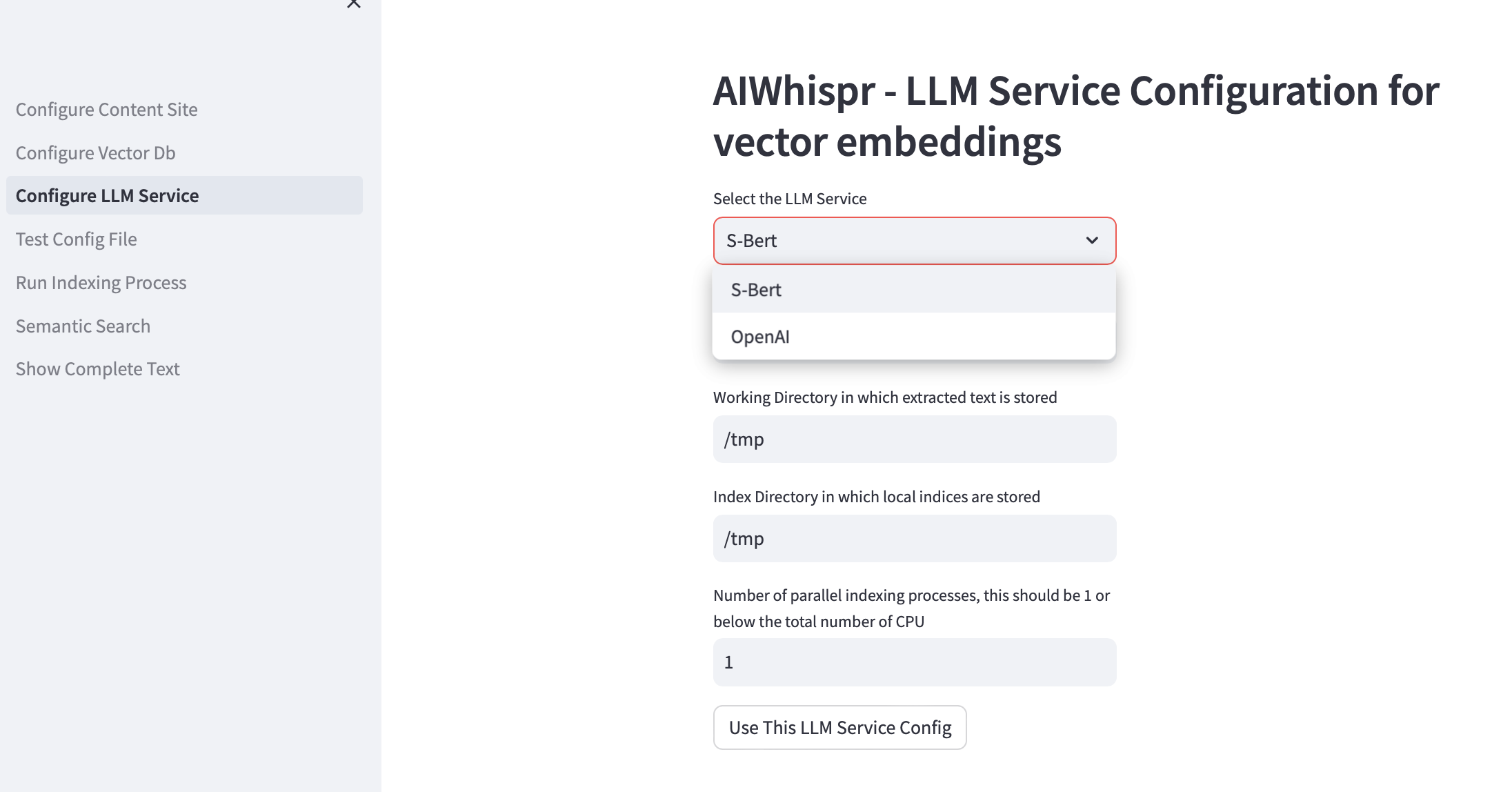
Anda dapat memilih untuk membuat penyematan vektor menggunakan model terlatih Sbert yang dijalankan secara lokal atau menggunakan OpenAI API.
Untuk keluarga model SBert, model default yang digunakan adalah all-mpnet-base-v2. Anda dapat menentukan model SBert lainnya.
Untuk OpenAI, model penyematan default adalah text-embedding-ada-002
Direktori kerja default adalah /tmp
Direktori kerja adalah lokasi pada mesin lokal yang akan digunakan sebagai direktori kerja untuk memproses file yang dibaca/diunduh dari lokasi penyimpanan Anda. Teks yang diekstrak dari dokumen Anda kemudian dipotong menjadi ukuran yang lebih kecil, biasanya 700 kata, yang kemudian dikodekan sebagai penyematan vektor. Dir kerja digunakan untuk menyimpan potongan teks.
Direktori pengindeksan lokal default adalah /tmp
Anda dapat menentukan jalur direktori lokal persisten untuk direktori kerja dan indeks.
Index-dir digunakan untuk menyimpan daftar pengindeksan file konten yang harus dibaca. AIWhispr mendukung banyak proses untuk pengindeksan, setiap proses akan menggunakan daftar pengindeksannya sendiri sehingga memungkinkan Anda memanfaatkan banyak CPU di mesin Anda.
Jika Anda ingin memanfaatkan beberapa CPU untuk pengindeksan (membaca konten, membuat penyematan vektor, menyimpannya dalam database vektor) maka tentukan ini di kotak pengujian untuk jumlah proses paralel. Rekomendasi kami adalah ini harus 1 atau maksimal (Jumlah CPU/2). Contoh pada mesin 8 CPU ini harus disetel ke 4. AIWhispr menggunakan multiprosesor untuk melewati batasan Python GIL.
Klik "Gunakan Konfigurasi Layanan LLM Ini" untuk membuat versi final file konfigurasi saluran penyematan vektor Anda.
Isi file konfigurasi dan lokasinya di mesin Anda akan ditampilkan.
Anda dapat menguji konfigurasi ini dengan mengklik "Test Config File" di sidebar kiri.
4. Uji Konfigurasi
Anda sekarang akan melihat pesan yang menunjukkan lokasi file konfigurasi pipa penyematan vektor Anda dan tombol "Uji File Konfigurasi"
Mengklik tombol tersebut akan memulai proses yang akan menguji konfigurasi pipeline
Anda akan melihat pesan "TANPA KESALAHAN" di akhir log yang memberi tahu Anda bahwa konfigurasi saluran pipa ini dapat digunakan.
Klik "Jalankan proses Pengindeksan" di sidebar kiri untuk memulai alur.
5. Jalankan Proses Pengindeksan
Anda akan melihat tombol "Mulai Pengindeksan".
Klik tombol ini untuk memulai alur. Log diperbarui setiap 15 detik.
Contoh default mengindeks 2000+ berita BBC yang memakan waktu sekitar 20 menit.
Jangan keluar dari halaman ini saat proses pengindeksan sedang berjalan, yaitu saat status Streamlit "Berjalan" ditampilkan di kanan atas.
Anda juga dapat memeriksa apakah proses pengindeksan berjalan menggunakan grep di mesin Anda.
ps -ef | grep python3 | grep index_content_site.py
6. Pencarian Semantik
Anda sekarang dapat menjalankan kueri penelusuran semantik.
Plot semantik yang menampilkan jarak cosinus, dan analisis PCA 3 teratas, untuk hasil pencarian juga ditampilkan bersama dengan hasil pencarian teks.