Qmedia
1.0.0
Bahasa Inggris | 简体中文
Changelog - Laporkan Masalah - Fitur Permintaan
1 kartu konten2 kain konten multimodal3 model multimodal lokal murniQMedia adalah mesin pencari konten AI multimedia sumber terbuka, menyediakan metode ekstraksi informasi yang kaya untuk teks/gambar dan konten video pendek. Ini mengintegrasikan teks/gambar tidak terstruktur dan informasi video pendek untuk membangun sistem Tanya Jawab konten RAG multimodal. Tujuannya adalah untuk berbagi dan bertukar ide tentang pembuatan konten AI secara open-source. masalah
Bagikan QMedia dengan teman Anda.
Bangkitkan ide-ide baru untuk pembuatan konten
| Bergabunglah dengan komunitas Perselisihan kami! | |
|---|---|
 | Bergabunglah dengan grup WeChat kami! |
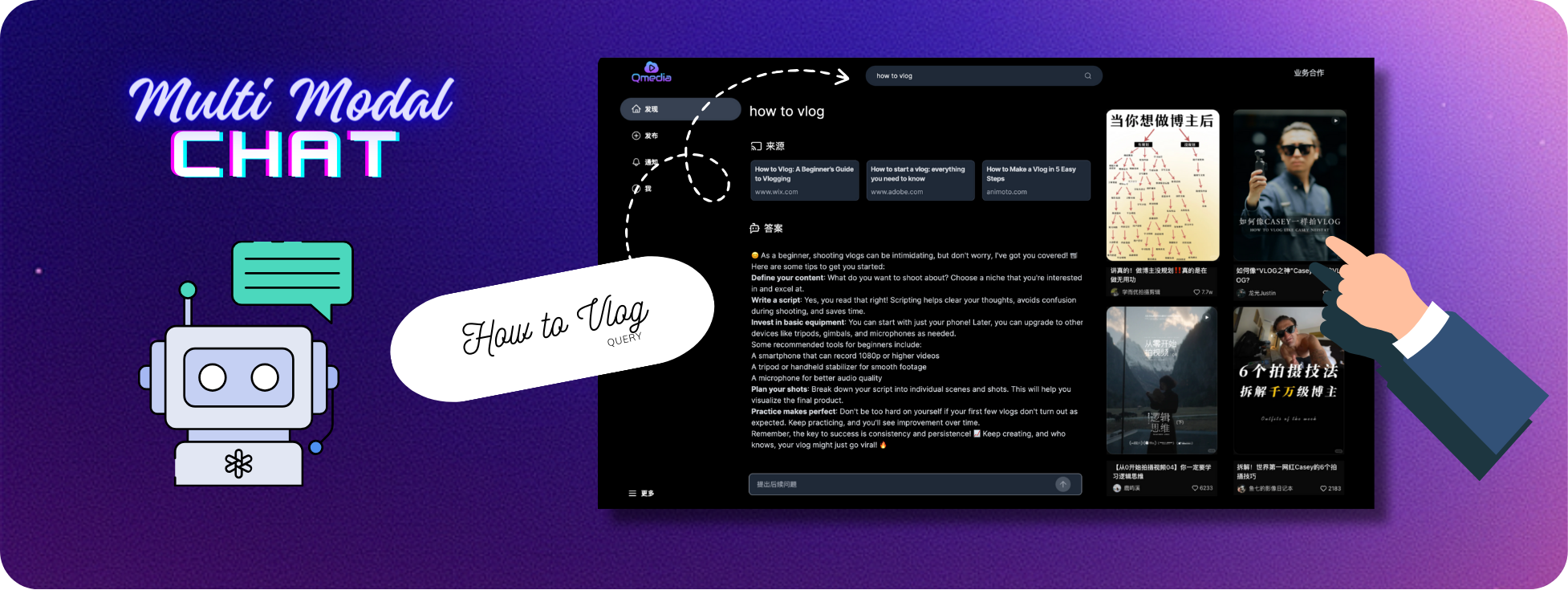
Web Service terinspirasi oleh versi web XHS, diimplementasikan menggunakan tumpukan teknologi TypeScript, Next.js, TailwindCSS, dan Shadcn/UIRAG Search/Q&A Service dan Image/Text/Video Model Service diimplementasikan menggunakan kerangka Python dan aplikasi LlamaIndexRAG Search/Q&A Service , dan Image/Text/Video Model Service dapat diterapkan secara terpisah untuk penerapan fleksibel berdasarkan sumber daya pengguna, dan dapat disematkan ke sistem lain untuk ekstraksi konten gambar/teks dan video. 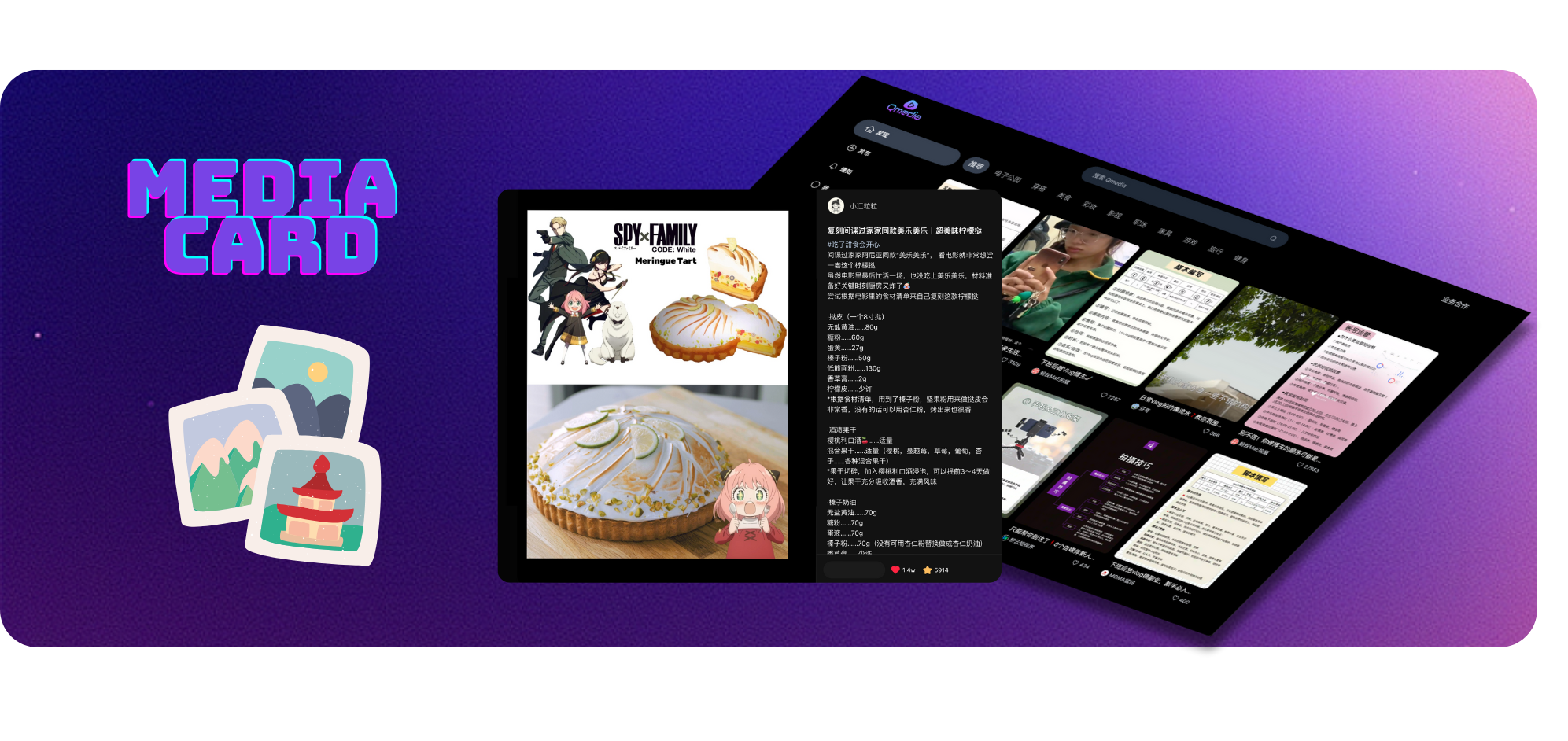
Penerapan berbagai jenis model secara lokal Pemisahan dari lapisan aplikasi RAG, sehingga memudahkan penggantian model yang berbeda Manajemen siklus hidup model lokal, dapat dikonfigurasi untuk rilis manual atau otomatis guna mengurangi beban server
Model Bahasa :
Fitur Model Penyematan :
Model Gambar :
Model Pemahaman Visual:
Model Video
Layanan QMedia: Tergantung pada ketersediaan sumber daya, layanan tersebut dapat diterapkan secara lokal atau layanan model dapat diterapkan di cloud
Layanan Model Multimodal mm_server :
Penerapan model multimodal dan panggilan API
Model Ollama LLM
Model gambar
Model video
Fitur penyematan model
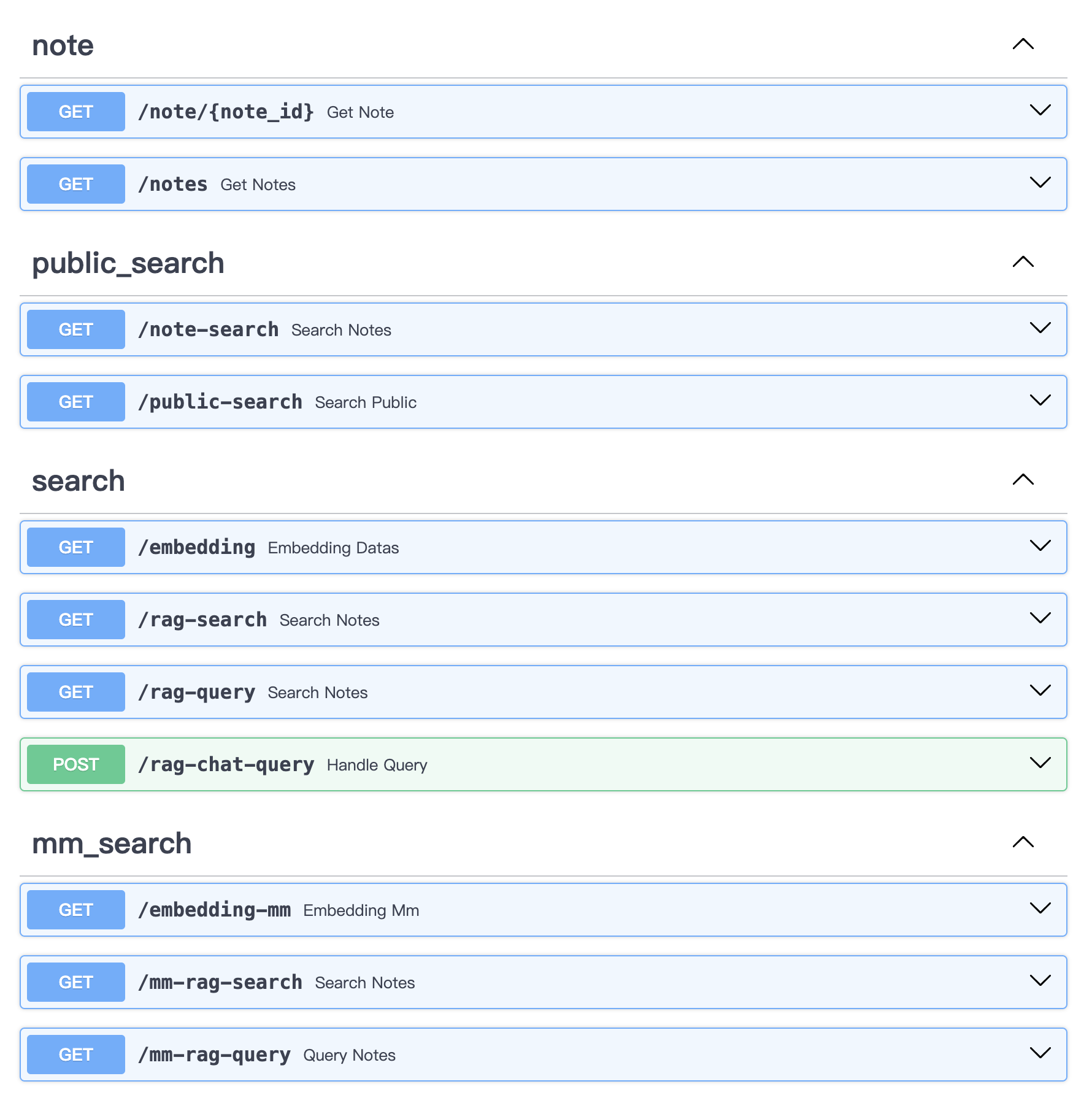
Pencarian Konten dan Layanan Tanya Jawab mmrag_server :
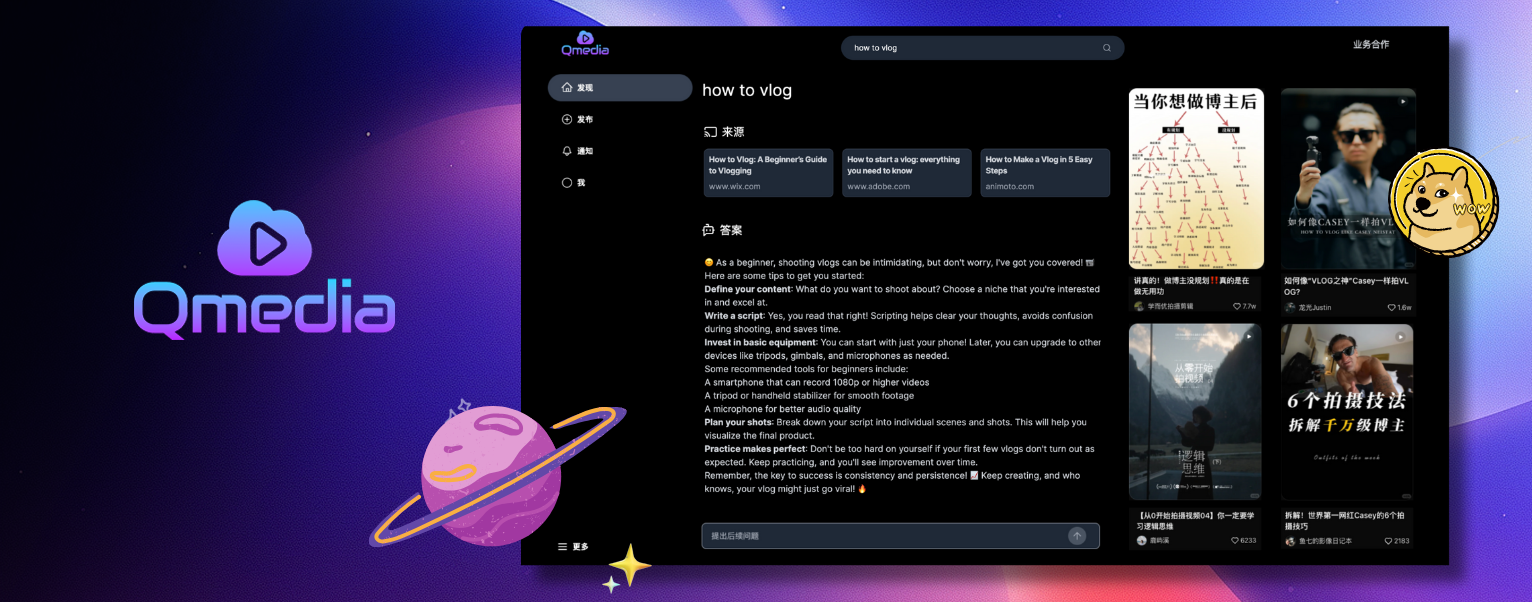
Tampilan dan Kueri Kartu Konten
Layanan Ekstraksi, Penyematan, dan Penyimpanan Konten Gambar/Teks/Video Pendek
Layanan Pengambilan RAG Data Multimodal
Layanan Tanya Jawab Konten
qmedia_web : Bahasa: Kerangka TypeScript: Next.js Gaya: Komponen CSS Tailwind: shadcn/ui mm_server + qmedia_web + mmrag_server Tampilan Konten Halaman Web, Pencarian dan Tanya Jawab RAG Konten, Layanan Model
# Start mm_server service
cd mm_server
source activate qllm
python main.py
# Start mmrag_server service
cd mmrag_server
source activate qmedia
python main.py
# Start qmedia_web service
cd qmedia_web
pnpm devmmrag_server akan membaca data semu dari assets/medias dan assets/mm_pseudo_data.json , dan memanggil mm_server untuk mengekstrak dan menyusun informasi dari teks/gambar dan video pendek menjadi informasi node , yang kemudian disimpan di db . Pengambilan dan tanya jawab akan didasarkan pada data di db . # assets file structure
assets
├── mm_pseudo_data.json # Content card data
└── medias # Image/Video files Ganti konten di assets dan hapus file db yang disimpan secara historis. assets/medias berisi file gambar/video, yang dapat diganti dengan file gambar/video Anda sendiri. assets/mm_pseudo_data.json berisi data kartu konten, yang dapat diganti dengan data kartu konten Anda sendiri. Setelah menjalankan layanan, model akan secara otomatis mengekstrak informasi dan menyimpannya di db .
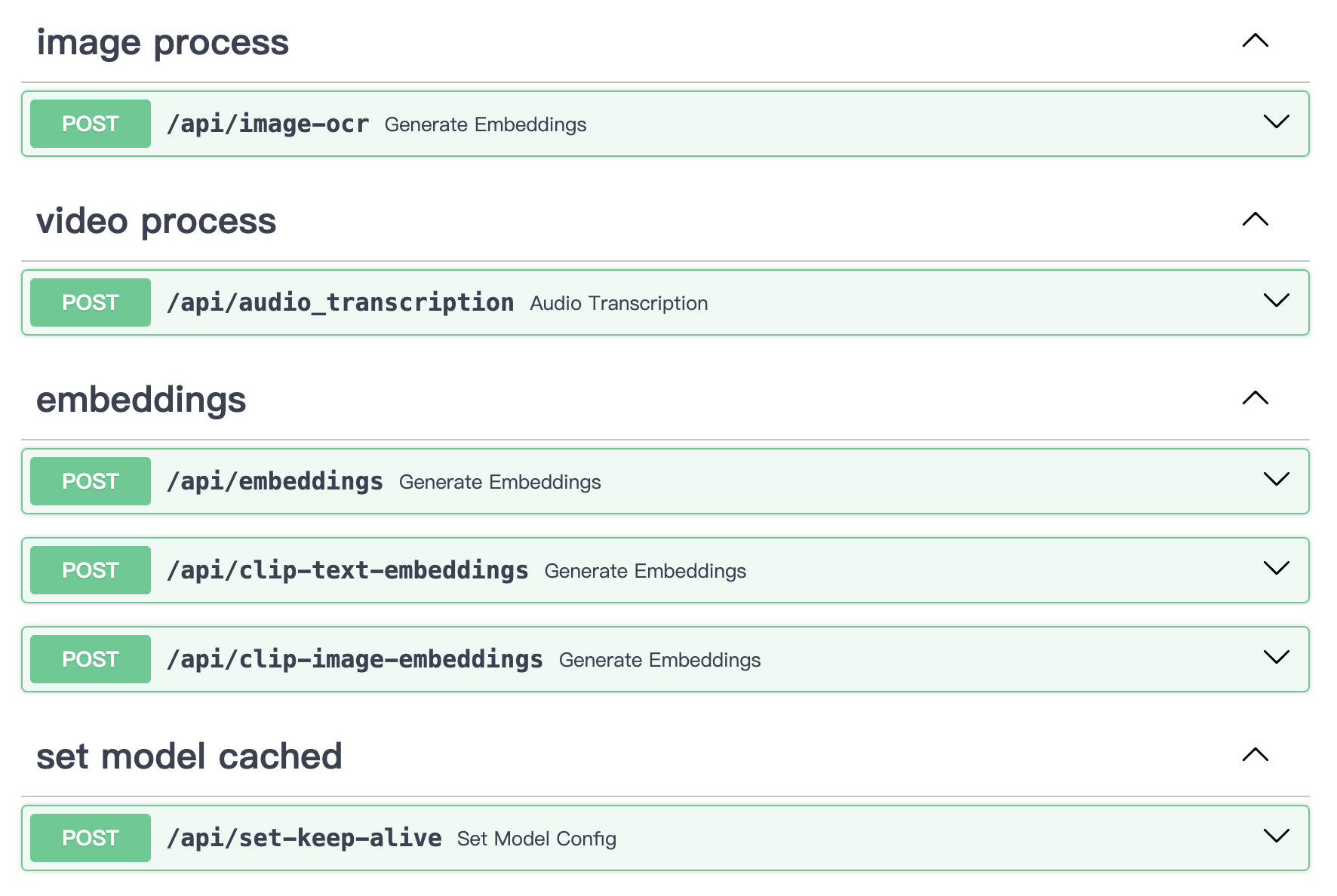
Dapat menggunakan layanan ekstraksi informasi gambar/teks/video lokal mm_server secara mandiri. Ini dapat digunakan sebagai pengkodean gambar mandiri, pengkodean teks, ekstraksi transkripsi video, dan layanan OCR gambar, dapat diakses melalui API dalam skenario apa pun.
# Start mm_server service independently
cd mm_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110Konten API:
Dapat menggunakan mm_server + qmedia_web secara bersamaan untuk melakukan ekstraksi konten dan pengambilan RAG di lingkungan Python murni melalui API.
# Start mmrag_server service independently
cd mmrag_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110Konten API:
QMedia dilisensikan di bawah Lisensi MIT
Terima kasih kepada QAnything untuk model OCR yang kuat.
Terima kasih kepada llava-llama3 untuk model visi llm yang kuat.


