sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
Pengelola: jcudit dan lsgos
Proyek dipertahankan setidaknya hingga (YYYY-MM-DD): 14-03-2023
Ini adalah contoh cara menggunakan Cohere API untuk membangun mesin pencari semantik sederhana. Hal ini tidak dimaksudkan agar siap produksi atau diskalakan secara efisien (meskipun dapat disesuaikan untuk tujuan ini), namun berfungsi untuk menunjukkan kemudahan memproduksi mesin pencari yang didukung oleh representasi yang dihasilkan oleh Model Bahasa Besar (LLM) Cohere.
Algoritme pencarian yang digunakan di sini cukup sederhana: algoritma ini hanya menemukan paragraf yang paling cocok dengan representasi pertanyaan, menggunakan titik akhir co.embed . Hal ini dijelaskan secara lebih rinci di bawah, namun berikut adalah diagram sederhana tentang apa yang terjadi. Pertama kita memecah teks masukan menjadi serangkaian paragraf, menyimpan alamatnya dalam masukan ke dalam daftar dan menghasilkan penyematan vektor untuk setiap paragraf menggunakan co.embed :
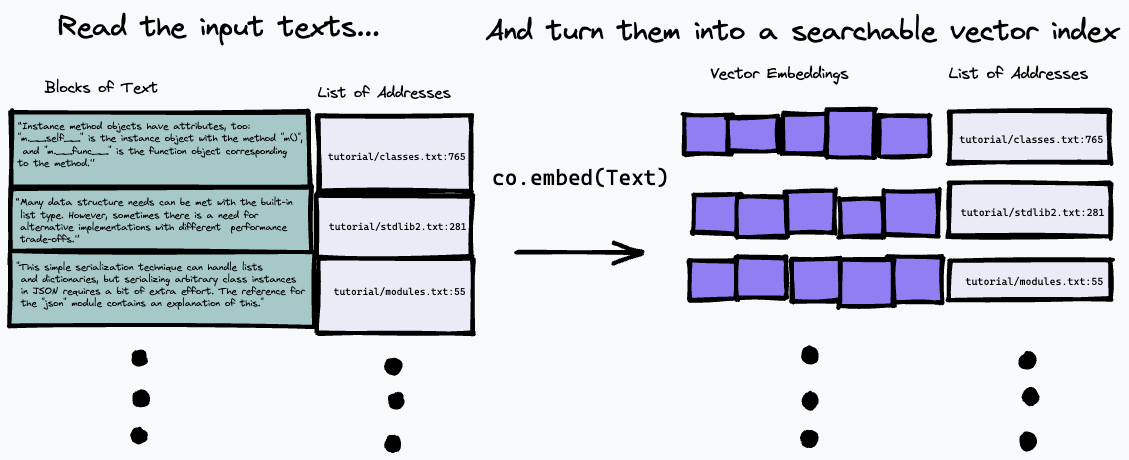
Kemudian, kita dapat mengkueri indeks kita dengan menyematkan kueri teks, dan menemukan paragraf dalam teks sumber yang memiliki kecocokan terdekat menggunakan beberapa ukuran kesamaan vektor (kami menggunakan kesamaan kosinus): 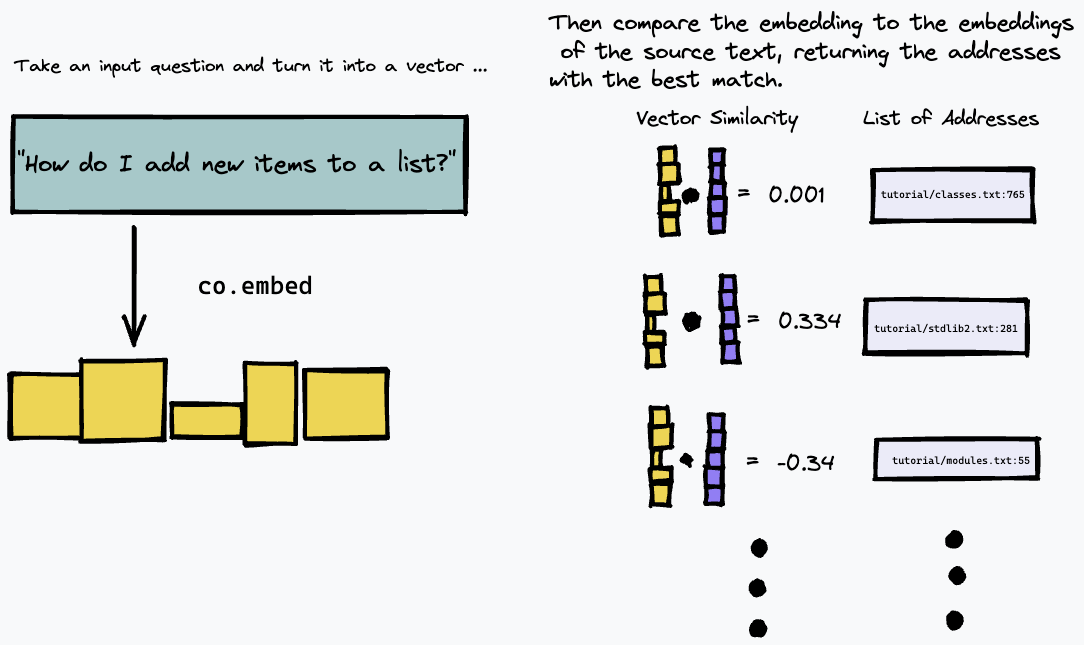
Hasilnya, cara ini berfungsi paling baik pada sumber teks yang jawaban terhadap pertanyaan tertentu kemungkinan besar diberikan melalui paragraf konkret dalam teks, seperti dokumentasi teknis atau wiki internal yang disusun sebagai daftar instruksi atau fakta konkret. Ini tidak bekerja dengan baik, misalnya, menjawab pertanyaan tentang teks berbentuk bebas seperti novel yang informasinya mungkin tersebar di beberapa paragraf; Anda perlu menggunakan metode pengindeksan teks yang berbeda untuk ini.
Sebagai contoh, repositori ini membangun mesin pencari semantik sederhana melalui versi teks dari dokumentasi python terbaru.
Untuk menginstal persyaratan python, pastikan Anda telah menginstal dan menjalankan puisi:
# install python deps
poetry installAnda juga harus menginstal buruh pelabuhan. Di OS X, jika Anda menggunakan homebrew, kami sarankan untuk menjalankannya
brew install --cask dockerSebelum menjalankan buruh pelabuhan (misalnya untuk menjalankan server kami) untuk pertama kalinya di OS X, buka aplikasi Docker dan berikan hak istimewa yang diperlukan untuk dijalankan di sistem Anda.
Anda juga harus memiliki Kunci API Cohere di COHERE_TOKEN . Dapatkan satu dari platform Cohere (buat akun jika diperlukan), dan tuliskan ke lingkungan Anda
export COHERE_TOKEN= < MY_API_KEY > (di mana <MY_API_KEY> adalah kunci yang Anda peroleh, tanpa tanda kurung <...> ).
Alternatifnya, Anda dapat meneruskan COHERE_TOKEN=<MY_API_KEY> sebagai argumen tambahan untuk perintah make apa pun di bawah.
Ikuti langkah-langkah berikut untuk terlebih dahulu membuat indeks semantik koleksi dokumen Anda. Langkah-langkah ini menghasilkan indeks semantik untuk dokumen resmi python, tetapi dapat diadaptasi untuk pengumpulan data sewenang-wenang.
Pertama, unduh dokumentasi python dengan menjalankan salah satu perintah berikut.
Jika Anda ingin memulai dengan cepat, jalankan
make download-python-docs-smalluntuk membatasi kumpulan dokumen ke tutorial python. Kami hanya menyarankan melakukan ini untuk tes cepat, karena hasilnya akan sangat terbatas .
Jika Anda ingin menguji mesin pencari seluruh dokumentasi python, jalankan
make download-python-docsnamun perlu diketahui bahwa pembuatan embeddings akan memakan waktu berjam-jam (walaupun ini hanya perlu dilakukan sekali).
Atau jika Anda ingin bereksperimen dengan teks Anda sendiri, cukup unduh sebagai file .txt ke direktori bernama txt/ di repositori ini.
Setelah Anda memiliki beberapa teks, kami perlu memprosesnya menjadi indeks pencarian embeddings dan alamat.
Hal ini dapat dilakukan dengan menggunakan perintah
make embeddings dengan asumsi teks target Anda berada di bawah direktori ./txt/ .
Perintah ini akan mencari direktori ./txt/ secara rekursif untuk file dengan ekstensi .txt , dan membangun database sederhana berisi embeddings, nama file, dan nomor baris setiap paragraf.
Peringatan: Jika Anda memiliki banyak teks untuk ditelusuri, proses ini memerlukan waktu agak lama untuk diselesaikan!
Setelah Anda membuat file embeddings.npz , Anda dapat menggunakan perintah berikut untuk membuat image buruh pelabuhan yang akan melayani aplikasi REST sederhana untuk memungkinkan Anda menanyakan database yang telah Anda buat:
make buildAnda kemudian dapat memulai server menggunakan
make runHal ini agak berlebihan untuk contoh sederhana, namun dirancang untuk mencerminkan fakta bahwa membuat indeks teks dalam jumlah besar relatif lambat, dan memastikan mesin kueri berjalan cepat.
Jika Anda ingin menggunakan proyek ini sebagai blok penyusun untuk aplikasi nyata, kemungkinan besar Anda ingin memelihara database penyematan teks dalam arsitektur server dan menanyakannya dengan klien yang ringan. Mengemas server sebagai aplikasi buruh pelabuhan berarti sangat mudah untuk mengubahnya menjadi aplikasi 'nyata' dengan menyebarkannya ke layanan cloud.
Jika Anda membuka jendela terminal baru untuk salah satu opsi di bawah ini, ingatlah untuk menjalankannya
export COHERE_TOKEN= < MY_API_KEY > Sejauh ini, opsi termudah adalah menjalankan skrip pembantu kami:
scripts/ask.sh " My query here "untuk menanyakan database. Skrip mengambil argumen opsional kedua yang menentukan jumlah hasil yang diinginkan.
Script memunculkan antarmuka vim yang dimodifikasi, dengan perintah berikut:
q untuk keluar.Panel atas akan menunjukkan posisi dalam dokumen tempat hasilnya ditemukan.
Setelah server berjalan, Anda dapat menanyakannya menggunakan REST api sederhana. Anda dapat menjelajahi API secara langsung dengan membuka /docs#/default/search_search_post di sini. Ini adalah JSON REST API sederhana; inilah cara Anda dapat mengajukan pertanyaan menggunakan curl :
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
Ini akan mengembalikan daftar JSON dengan panjang num_results , masing-masing dengan nama file dan nomor baris ( doc_url dan block_url ) dari blok yang paling cocok secara semantik dengan kueri Anda. Namun Anda mungkin ingin membaca sedikit file yang merupakan jawaban terbaik.
Saat kita menelusuri file teks lokal, sebenarnya lebih mudah untuk menguraikan output menggunakan alat baris perintah; gunakan skrip python yang disediakan utils/query_server.py untuk menanyakannya pada baris perintah. query_server.py mencetak hasilnya dalam format file_name:line_number: standar, sehingga kita dapat menelusuri hasil aktual dengan cara yang baik dengan memanfaatkan mode perbaikan cepat vim .
Dengan asumsi Anda memiliki vim di mesin Anda, Anda bisa melakukannya dengan mudah
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
untuk mendapatkan vim untuk membuka file teks yang diindeks di lokasi yang dikembalikan oleh algoritma pencarian. (gunakan :qall untuk menutup jendela dan navigator perbaikan cepat). Anda dapat menelusuri hasil yang dikembalikan menggunakan :cn dan :cp . Hasilnya tidak sempurna; ini pencarian semantik, jadi Anda mungkin mengira pencocokannya agak kabur. Meskipun demikian, saya sering menemukan Anda bisa mendapatkan jawaban atas pertanyaan Anda di beberapa hasil pertama, dan menggunakan API Cohere memungkinkan Anda mengungkapkan pertanyaan Anda dalam bahasa alami, dan memungkinkan Anda membangun mesin pencari yang sangat efektif hanya dalam beberapa baris kode.
Beberapa pertanyaan yang bagus untuk dicoba dalam kasus python docs yang menunjukkan pencarian berfungsi dengan baik pada pertanyaan umum dan bahasa alami adalah:
How do I put new items in a list? (Perhatikan bahwa pertanyaan ini menghindari penggunaan kata kunci 'tambahkan', dan tidak sama persis dengan cara dokumen menjelaskan penambahan (mereka mengatakan ini digunakan untuk menambahkan item baru ke akhir daftar). Namun pencarian semantik dengan tepat menemukan bahwa paragraf yang relevan masih yang paling cocok.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (perhatikan untuk pertanyaan ini, bahwa hasil pertama bagi saya adalah FAQ tentang topik yang sama persis, tetapi dengan kata-kata pertanyaan yang berbeda. Namun, karena ini adalah pencarian semantik, algoritme kami dengan tepat memilih hasil yang cocok dengan maknanya, bukan hanya kata-kata, dari pertanyaan kami)How do I remove an item from a set?How do list comprehensions work? Repo ini menggunakan strategi yang sangat sederhana untuk mengindeks dokumen, dan mencari yang paling cocok. Pertama, ia memecah setiap dokumen menjadi beberapa paragraf, atau 'blok'. Kemudian, ia memanggil co.embed pada setiap paragraf, untuk menghasilkan penyematan vektor menggunakan model bahasa Cohere. Kemudian menyimpan setiap vektor penyematan, bersama dengan dokumen terkait dan nomor baris paragraf, dalam array sederhana sebagai 'database'.
Untuk benar-benar melakukan pencarian, kami menggunakan perpustakaan pencarian kesamaan FAISS. Saat kami mendapatkan kueri, kami menggunakan panggilan Cohere API yang sama untuk menyematkan kueri. Kami kemudian menggunakan FAISS untuk menemukan puncak
Jika Anda memiliki pertanyaan atau komentar, silakan ajukan masalah atau hubungi kami di Discord.
Jika Anda ingin berkontribusi pada proyek ini, silakan baca CONTRIBUTORS.md di repositori ini, dan tanda tangani Perjanjian Lisensi Kontributor sebelum mengirimkan permintaan penarikan apa pun. Tautan untuk menandatangani Cohere CLA akan dibuat saat pertama kali Anda membuat permintaan tarik ke repositori Cohere.
Toy Semantic Search memiliki lisensi MIT, seperti yang ditemukan dalam file LICENSE.


