SeekStorm
v0.11.0

SeekStorm adalah perpustakaan pencarian teks lengkap sub-milidetik & server multi-tenancy sumber terbuka yang diterapkan di Rust .
Pengembangan dimulai pada tahun 2015, diproduksi sejak tahun 2020, port Rust pada tahun 2023, open source pada tahun 2024, sedang dalam proses.
SeekStorm adalah sumber terbuka yang dilisensikan di bawah Lisensi Apache 2.0
Postingan Blog: SeekStorm sekarang menjadi Open Source dan SeekStorm mendapatkan pencarian Faceted, pencarian kedekatan Geo, Penyortiran hasil
Jenis kueri
Jenis hasil
Pertunjukan
Latensi lebih rendah, throughput lebih tinggi, biaya & konsumsi energi lebih rendah, khususnya. untuk kueri multi-bidang dan bersamaan.
Latensi rendah memastikan pengalaman pengguna yang lancar dan mencegah hilangnya pelanggan dan pendapatan.
Meskipun beberapa perusahaan mengandalkan akselerator perangkat keras berpemilik (FPGA/ASIC) atau cluster untuk meningkatkan kinerja,
SeekStorm mencapai peningkatan serupa secara algoritmik pada satu server komoditas.
Konsistensi
Tidak ada latensi kueri yang tidak dapat diprediksi selama dan setelah pengindeksan volume besar karena SeekStorm tidak memerlukan penggabungan segmen yang intensif sumber daya.
Latensi stabil - tidak ada biaya cold start karena kompilasi tepat waktu, tidak ada penundaan pengumpulan sampah yang tidak dapat diprediksi.
Penskalaan
Mempertahankan latensi rendah, throughput tinggi, dan konsumsi RAM rendah bahkan untuk indeks skala miliaran.
Nomor bidang, panjang bidang & ukuran indeks tidak terbatas.
Relevansi
Jangka proximity ranking memberikan hasil yang lebih relevan dibandingkan dengan BM25.
Waktu nyata
Pencarian real-time yang sebenarnya, berbeda dengan NRT: setiap dokumen yang diindeks dapat segera dicari, bahkan sebelum dan selama penerapan.
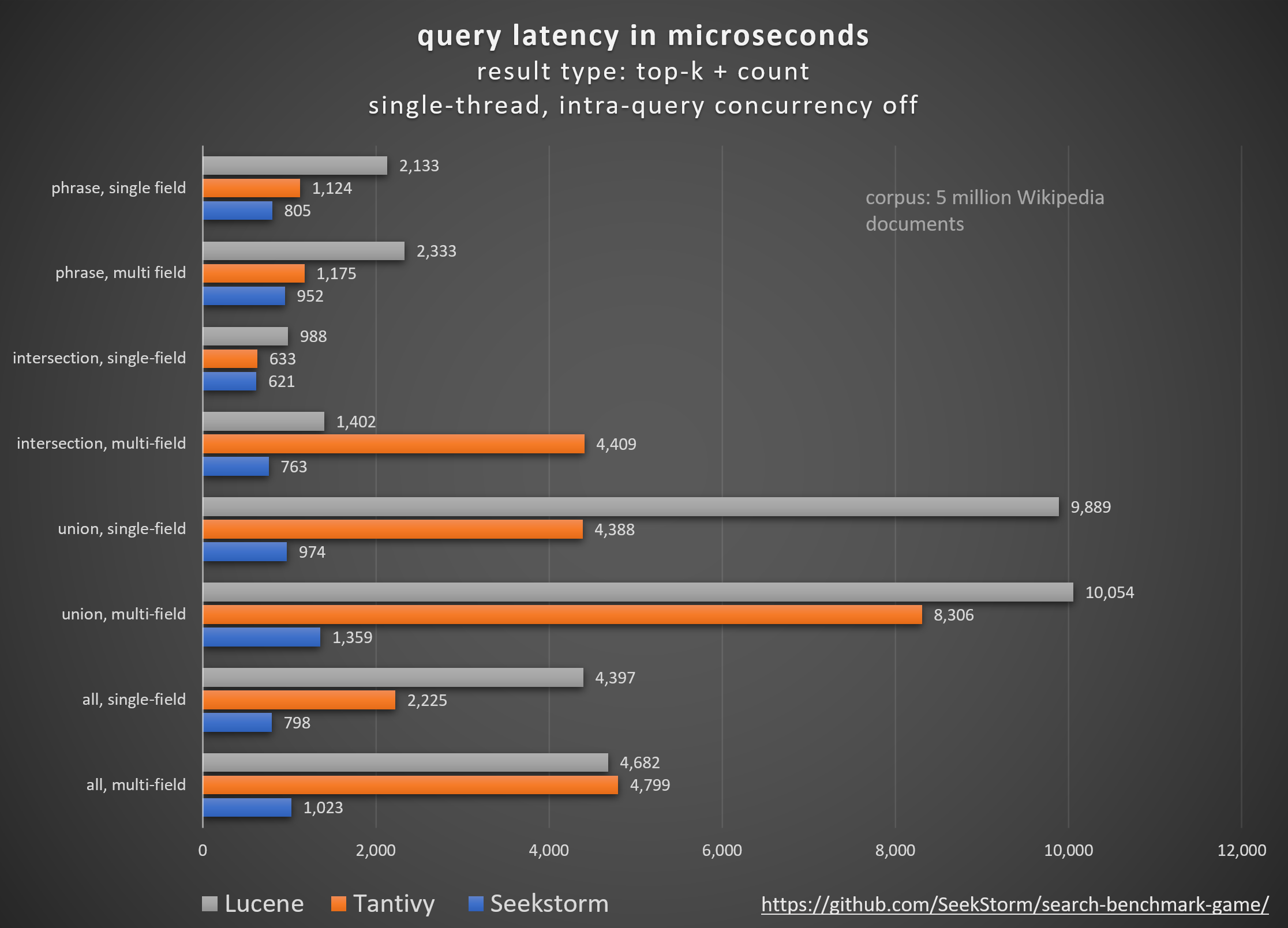
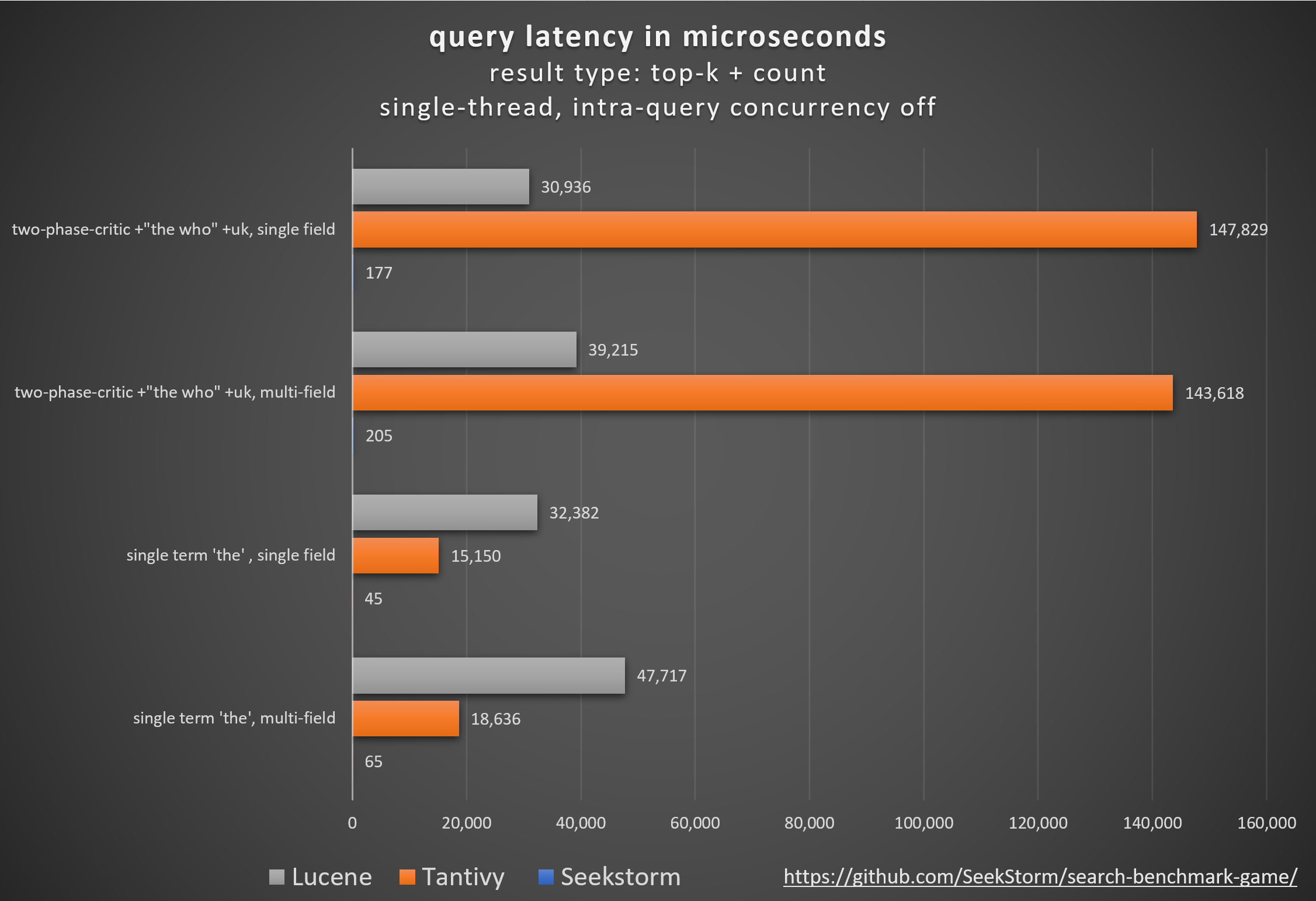
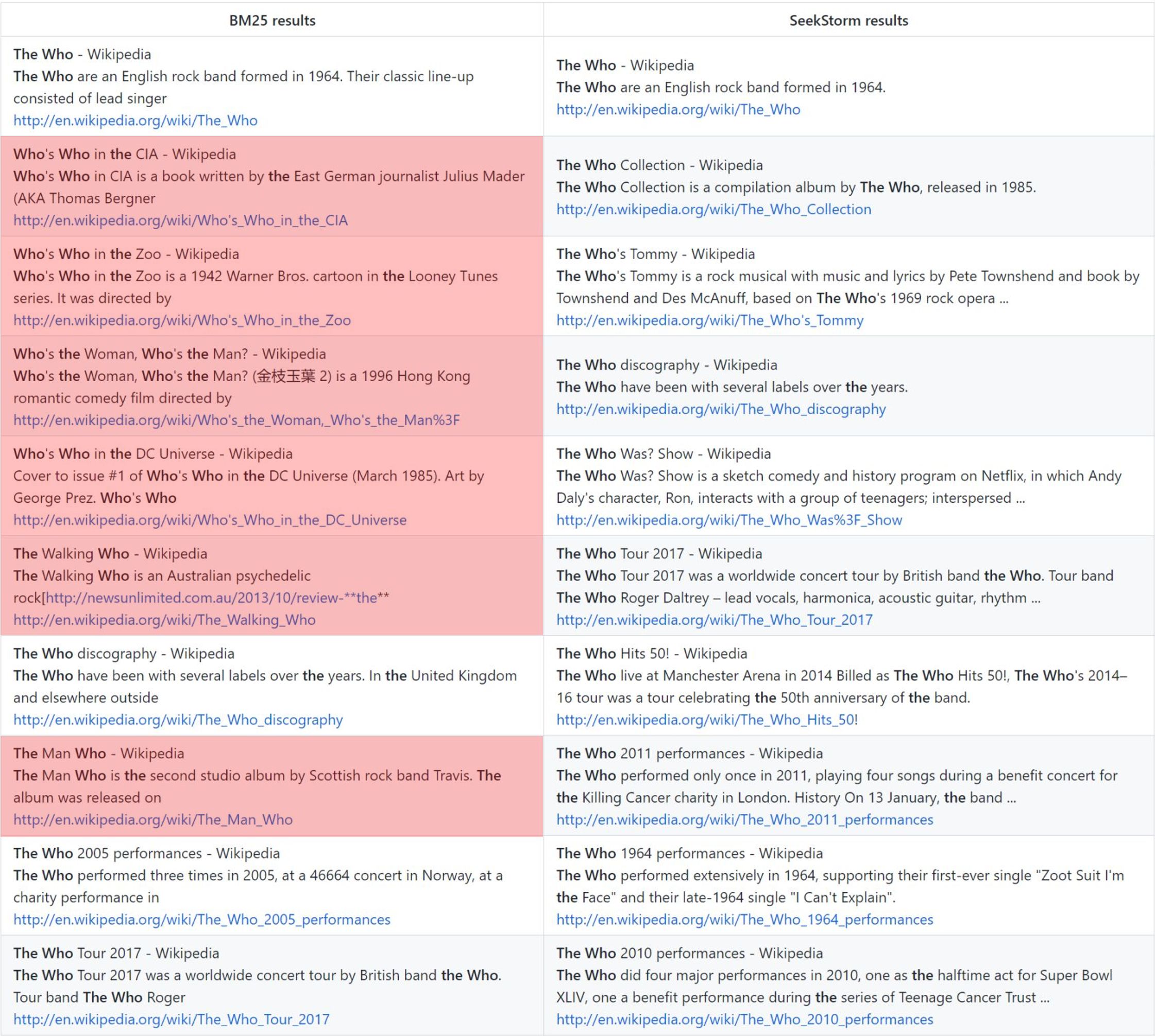
siapa: peringkat vanilla BM25 vs. peringkat kedekatan SeekStorm
Metodologi
Membandingkan perpustakaan mesin pencari sumber terbuka yang berbeda (pencarian leksikal BM25) menggunakan pencarian_benchmark_game sumber terbuka yang dikembangkan oleh Tantivy dan Jason Wolfe.
Manfaat
Hasil benchmark terperinci https://seekstorm.github.io/search-benchmark-game/
Repositori kode tolok ukur https://github.com/SeekStorm/search-benchmark-game/
Lihat posting blog kami untuk informasi lebih rinci: SeekStorm sekarang Open Source dan SeekStorm mendapatkan pencarian Faceted, pencarian Geo proximity, Penyortiran hasil
Terlepas dari apa yang https://www.bitecode.dev/p/hype-cycles ingin Anda percayai, pencarian kata kunci tidak mati, karena NoSQL bukanlah kematian SQL.
Anda harus memelihara kotak peralatan, dan memilih alat terbaik untuk tugas Anda. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
Pencarian kata kunci hanyalah filter untuk sekumpulan dokumen, mengembalikan dokumen tempat kata kunci tertentu muncul, biasanya dikombinasikan dengan metrik peringkat seperti BM25. Fungsionalitas yang sangat mendasar dan inti, yang sangat menantang untuk diterapkan dalam skala besar dengan latensi rendah. Karena fungsinya sangat mendasar, jumlah bidang aplikasi tidak terbatas. Ini adalah sebuah komponen, untuk digunakan bersama dengan komponen lainnya. Ada kasus penggunaan yang saat ini dapat diselesaikan dengan lebih baik dengan penelusuran vektor dan LLM, namun bagi banyak kasus lainnya, penelusuran kata kunci masih merupakan solusi terbaik. Pencarian kata kunci tepat, tanpa kerugian, dan sangat cepat, dengan penskalaan yang lebih baik, latensi yang lebih baik, biaya dan konsumsi energi yang lebih rendah. Pencarian vektor bekerja dengan kesamaan semantik, mengembalikan hasil dengan kedekatan dan probabilitas tertentu.
Jika Anda mencari hasil yang tepat seperti nama diri, nomor, plat nomor, nama domain, dan frasa (misalnya deteksi plagiarisme) maka pencarian kata kunci adalah teman Anda. Pencarian vektor di sisi lain akan mengubur hasil persis yang Anda cari di antara banyak sekali hasil yang hanya terkait secara semantik. Pada saat yang sama, jika Anda tidak mengetahui istilah persisnya, atau Anda tertarik pada topik, makna, atau sinonim yang lebih luas, apa pun istilah persisnya yang digunakan, pencarian kata kunci akan mengecewakan Anda.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.Penelusuran vektor sempurna jika Anda tidak mengetahui istilah kueri persisnya, atau Anda tertarik pada topik, makna, atau sinonim yang lebih luas, apa pun istilah kueri persisnya yang digunakan. Namun jika Anda mencari istilah yang tepat, misalnya nama diri, nomor, plat nomor, nama domain, dan frasa (misalnya deteksi plagiarisme) maka Anda harus selalu menggunakan pencarian kata kunci. Pencarian vektor hanya akan mengubur hasil persis yang Anda cari di antara banyak sekali hasil yang hanya terkait satu sama lain. Ia memiliki daya ingat yang baik, tetapi presisi rendah, dan latensi lebih tinggi. Hal ini rentan terhadap kesalahan positif, misalnya dalam deteksi plagiarisme karena kata-kata dan urutan kata yang tepat hilang.
Pencarian vektor memungkinkan Anda untuk mencari tidak hanya teks serupa, tetapi segala sesuatu yang dapat diubah menjadi vektor: teks, gambar (pengenalan wajah, sidik jari), audio dan memungkinkan Anda melakukan hal-hal ajaib seperti ratu - wanita + pria = raja .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationPencarian vektor bukanlah pengganti pencarian kata kunci, namun tambahan pelengkap - paling baik digunakan dalam solusi hibrid yang menggabungkan kekuatan kedua pendekatan. Pencarian kata kunci tidak ketinggalan jaman, namun sudah teruji oleh waktu .
Kami telah (sebagian) mem-porting basis kode SeekStorm dari C# ke Rust
Rust sangat bagus untuk aplikasi dengan kinerja penting yang menangani data besar dan/atau banyak pengguna secara bersamaan. Algoritma yang cepat akan semakin bersinar dengan bahasa pemrograman yang memperhatikan kinerja?
lihat ARSITEKTUR.md
cargo build --release
PERINGATAN : pastikan untuk menyetel variabel lingkungan MASTER_KEY_SECRET ke rahasia, jika tidak, kunci API yang Anda buat akan disusupi.
https://docs.rs/seekstorm
Bangun dokumentasi
cargo doc --no-deps
Akses dokumentasi secara lokal
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
Tambahkan peti yang diperlukan ke proyek Anda
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;gunakan runtime Rust asinkron
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {membuat indeks
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;buka indeks (sebagai alternatif untuk membuat indeks)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; dokumen indeks
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; melakukan dokumen
index_arc . commit ( ) . await ;indeks pencarian
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;menampilkan hasil
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}pencarian multi-utas
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}indeks file JSON dalam format JSON, JSON yang dibatasi baris baru, dan JSON gabungan
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;indeks semua file PDF di direktori dan subdirektori
ingest ): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;indeks file PDF
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;indeks byte file PDF
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;dapatkan byte file PDF
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;indeks yang jelas
index . clear_index ( ) ;hapus indeks
index . delete_index ( ) ;tutup indeks
index . close_index ( ) ;string versi perpustakaan seekstorm
let version= version ( ) ;
println ! ( "version {}" ,version ) ;Aspek didefinisikan di 3 tempat berbeda:
Contoh kerja minimal pengindeksan & pencarian segi hanya memerlukan 60 baris kode. Namun menyatukan semuanya dari dokumentasi saja mungkin membosankan. Inilah sebabnya kami memberikan contoh memulai cepat di sini:
Tambahkan peti yang diperlukan ke proyek Anda
cargo add seekstorm
cargo add tokio
cargo add serde_jsonTambahkan deklarasi penggunaan
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;gunakan runtime Rust asinkron
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {membuat indeks
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;dokumen indeks
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; melakukan dokumen
index_arc . commit ( ) . await ;indeks pencarian
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;menampilkan hasil
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}aspek tampilan
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;akhir fungsi utama
Ok ( ( ) )
} Tutorial singkat langkah demi langkah tentang cara membuat mesin pencari Wikipedia dari korpus Wikipedia menggunakan server SeekStorm dalam 5 langkah mudah.

Unduh SeekStorm
Unduh SeekStorm dari repositori GitHub
Buka zip di direktori pilihan Anda, buka dalam kode Visual Studio.
atau sebagai alternatif
git clone https://github.com/SeekStorm/SeekStorm.git
Bangun SeekStorm
Instal Rust (jika belum ada): https://www.rust-lang.org/tools/install
Di terminal Visual Studio Code ketik:
cargo build --release
Dapatkan korpus Wikipedia
Korpus Wikipedia bahasa Inggris yang telah diproses sebelumnya (5.032.105 dokumen, 8,28 GB didekompresi). Meskipun wiki-articles.json memiliki ekstensi .JSON, ini bukan file JSON yang valid. Ini adalah file teks, di mana setiap baris berisi objek JSON dengan atribut url, judul, dan isi. Formatnya disebut ndjson ("JSON yang dibatasi baris baru").
Unduh korpus Wikipedia
Dekompresi korpus Wikipedia.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
Pindahkan wiki-articles.json yang telah didekompresi ke direktori rilis
Mulai server SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Pengindeksan
Ketik 'ingest' ke dalam baris perintah server SeekStorm yang sedang berjalan:
ingest
Ini menciptakan indeks demo dan mengindeks file wikipedia lokal.
Mulai mencari di dalam WebUI yang tertanam
Buka UI Web tertanam di browser: http://127.0.0.1
Masukkan kueri ke dalam kotak pencarian
Menguji titik akhir REST API
Buka src/seekstorm_server/test_api.rest di VSC bersama dengan ekstensi VSC "Rest client" untuk menjalankan panggilan API dan memeriksa respons
contoh titik akhir API interaktif
Setel 'kunci API individual' di test_api.rest ke kunci api yang ditampilkan di konsol server saat Anda mengetik 'indeks' di atas.
Hapus indeks demo
Ketik 'hapus' ke dalam baris perintah server SeekStorm yang sedang berjalan:
delete
Server dimatikan
Ketik 'keluar' pada baris perintah server SeekStorm yang sedang berjalan.
quit
Menyesuaikan
Apakah Anda ingin menggunakan sesuatu yang serupa untuk proyek Anda sendiri? Lihat dokumentasi penyerapan dan UI web.
Tutorial singkat langkah demi langkah tentang cara membuat mesin pencari PDF dari direktori yang berisi file PDF menggunakan server SeekStorm.
Jadikan semua makalah ilmiah, eBook, resume, laporan, kontrak, dokumentasi, manual, surat, laporan bank, faktur, catatan pengiriman Anda dapat dicari - di rumah atau di organisasi Anda.
Bangun SeekStorm
Instal Rust (jika belum ada): https://www.rust-lang.org/tools/install
Di terminal Visual Studio Code ketik:
cargo build --release
Unduh PDFium
Unduh dan salin perpustakaan Pdfium ke folder yang sama dengan seekstorm_server.exe: https://github.com/bblanchon/pdfium-binaries
Mulai server SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Pengindeksan
Pilih direktori yang berisi file PDF yang ingin Anda indeks dan cari, misalnya dokumen atau direktori download Anda.
Ketik 'ingest' ke dalam baris perintah server SeekStorm yang sedang berjalan:
ingest C:UsersJohnDoeDownloads
Ini membuat pdf_index dan mengindeks semua file PDF dari direktori yang ditentukan, termasuk subdirektori.
Mulai mencari di dalam WebUI yang tertanam
Buka UI Web tertanam di browser: http://127.0.0.1
Masukkan kueri ke dalam kotak pencarian
Hapus indeks demo
Ketik 'hapus' ke dalam baris perintah server SeekStorm yang sedang berjalan:
delete
Server dimatikan
Ketik 'keluar' pada baris perintah server SeekStorm yang sedang berjalan.
quit
Pencarian teks lengkap 30 juta postingan Berita Peretas DAN halaman web tertaut
DeepHN.org
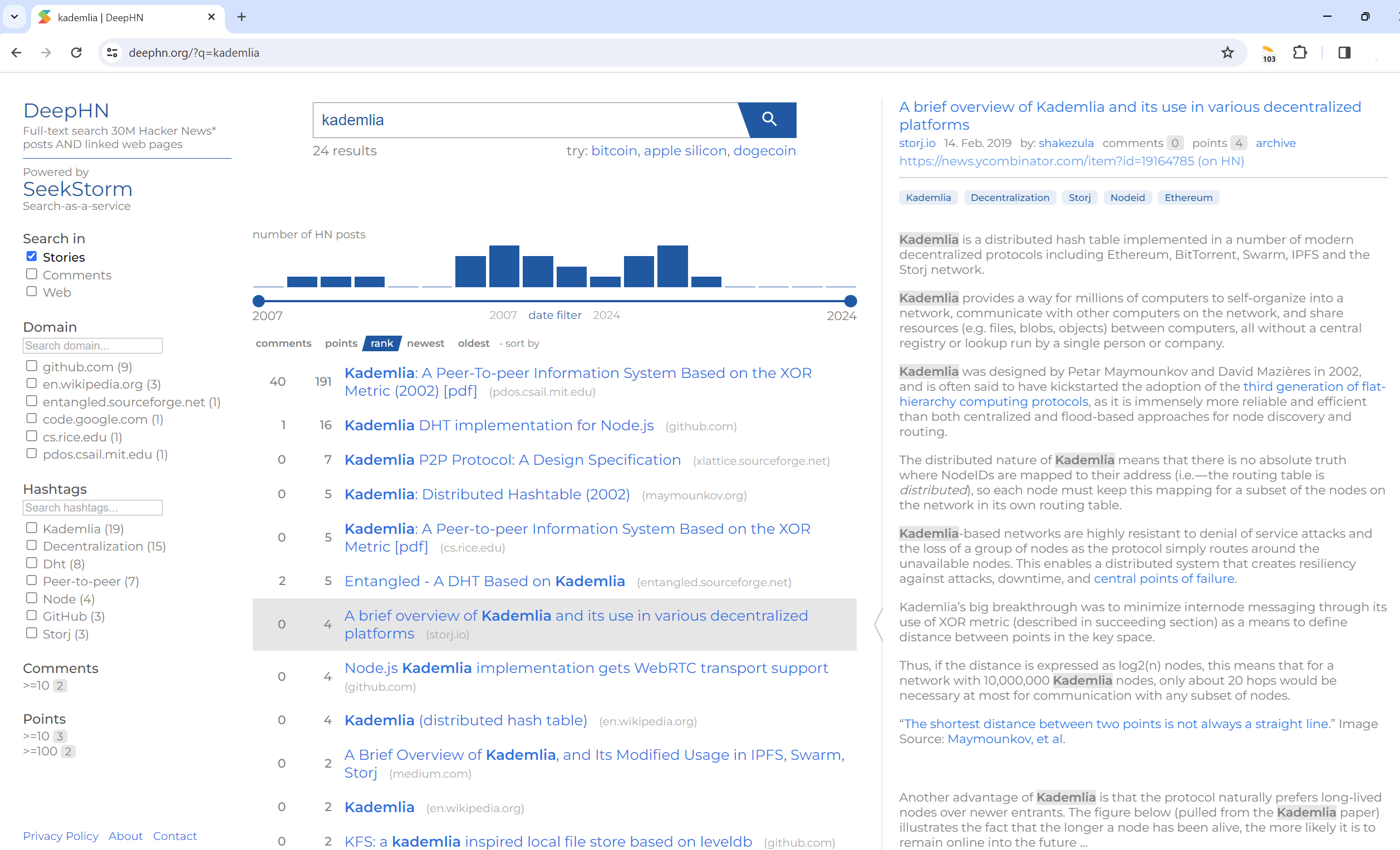
Demo DeepHN masih didasarkan pada basis kode SeekStorm C#.
Saat ini kami sedang mem-porting semua fitur yang diperlukan dan hilang.
Lihat peta jalan di bawah.
Port Rust belum memiliki fitur yang lengkap. Fitur-fitur berikut sedang di-porting.
Pemindahan
Perbaikan
Fitur baru


