elastic_transformers
1.0.0
Elasticsearch Semantik dengan Kalimat Transformers. Kami akan menggunakan kekuatan Elastic dan keajaiban BERT untuk mengindeks satu juta artikel dan melakukan pencarian leksikal dan semantik pada artikel tersebut.
Tujuannya adalah untuk memberikan cara yang mudah digunakan dalam menyiapkan Elasticsearch Anda sendiri dengan kemampuan penyematan kontekstual / pencarian semantik yang hampir canggih menggunakan transformator NLP.
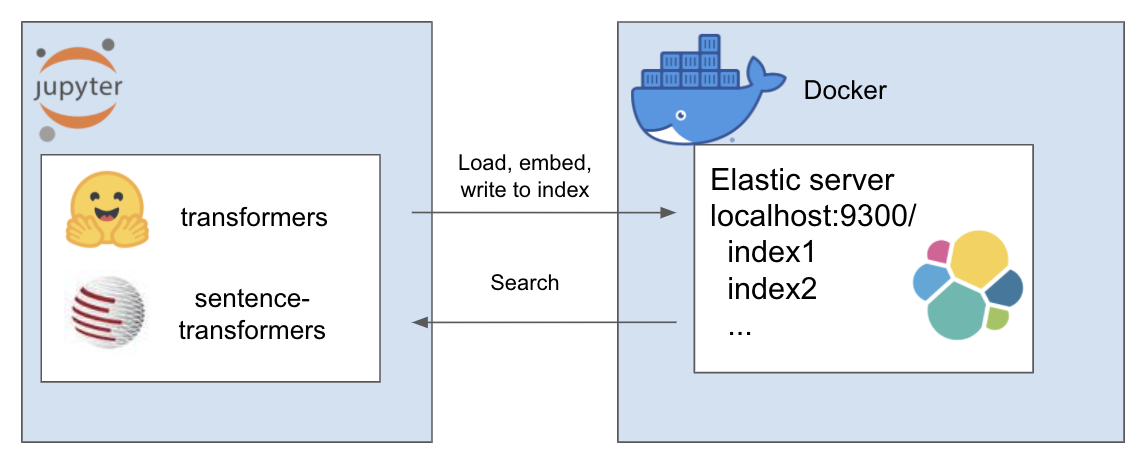
Pengaturan di atas berfungsi sebagai berikut
Lingkungan saya bernama et dan saya menggunakan conda untuk ini. Navigasi di dalam direktori proyek
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtUntuk tutorial ini saya menggunakan A Million News Headlines oleh Rohk dan menempatkannya di folder data di dalam direktori proyek.
elastic_transformers/
├── data/
Anda akan menemukan bahwa langkah-langkahnya cukup abstrak sehingga Anda juga dapat melakukan ini dengan kumpulan data pilihan Anda
Ikuti petunjuk pengaturan Elastic dengan Docker dari halaman Elastic di sini. Untuk tutorial ini, Anda hanya perlu menjalankan dua langkah:
Repo ini memperkenalkan kelas ElasiticTransformers. Utilitas yang membantu membuat, mengindeks, dan menanyakan indeks Elasticsearch yang mencakup penyematan
Mulai tautan koneksi serta (opsional) nama indeks yang akan digunakan
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec mendefinisikan pemetaan untuk indeks. Daftar bidang yang relevan dapat disediakan untuk pencarian kata kunci atau pencarian semantik (vektor padat). Ia juga memiliki parameter untuk ukuran vektor padat karena dapat bervariasi create_index - menggunakan spesifikasi yang dibuat sebelumnya untuk membuat indeks yang siap untuk dicari
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - memecah file csv besar menjadi beberapa bagian dan secara berulang menggunakan utilitas penyematan yang telah ditentukan sebelumnya untuk membuat daftar penyematan untuk setiap bagian dan kemudian memasukkan hasilnya ke indeks
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )pencarian - memungkinkan untuk memilih kata kunci ('cocok' dalam elastis) atau pencarian semantik (padat dalam elastis). Khususnya ini memerlukan fungsi penyematan yang sama dengan yang digunakan di write_large_csv
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )Setelah pengaturan berhasil, gunakan buku catatan berikut agar semuanya berfungsi
Repo ini menggabungkan karya-karya menakjubkan berikut dari orang-orang brilian. Silakan periksa pekerjaan mereka jika Anda belum melakukannya...


