ndvr
1.0.0
Peringkat ke-2 untuk Hackathon Penelusuran Neural?
Kita telah menyaksikan pertumbuhan data video yang eksplosif di berbagai situs berbagi video dengan miliaran video tersedia di internet, menjadi tantangan besar untuk melakukan pengambilan video hampir duplikat (NDVR) dari database video berskala besar. NDVR bertujuan untuk mengambil video yang hampir duplikat dari database video yang sangat besar, dimana video yang hampir duplikat didefinisikan sebagai video yang secara visual mirip dengan video aslinya.
Pengguna memiliki insentif yang kuat untuk menyalin video pendek yang sedang tren & mengunggah versi tambahannya untuk mendapatkan perhatian. Dengan pertumbuhan video pendek, kesulitan dan tantangan baru untuk mendeteksi video pendek yang hampir duplikat pun muncul.
Di sini, kami telah membangun solusi Neural Search menggunakan Jina untuk mengatasi tantangan NDVR.
Daftar isi

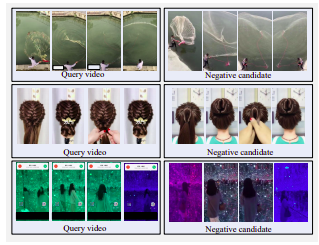
Contoh video kandidat hard positif. Baris atas: morro samping, disaring warna, dan dicuci air. Baris tengah: layar horizontal diubah menjadi layar vertikal dengan margin hitam besar. Baris bawah: diputar
Contoh video negatif keras. Semua kandidat secara visual mirip dengan kueri tetapi tidak hampir duplikat.
Ada tiga strategi untuk memilih kandidat video:
Kami memutuskan untuk menggunakan strategi Transformed Retrieval karena keterbatasan waktu & sumber daya. Dalam aplikasi nyata, pengguna akan menyalin video yang sedang tren untuk insentif pribadi. Pengguna biasanya memilih untuk sedikit memodifikasi video yang disalin untuk melewati deteksi. Modifikasi ini mencakup pemotongan video, penyisipan batas, dan sebagainya.
Untuk meniru perilaku pengguna tersebut, kami mendefinisikan satu transformasi temporal, yaitu kecepatan video, dan tiga transformasi spasial, yaitu pemotongan video, penyisipan batas hitam, dan rotasi video.
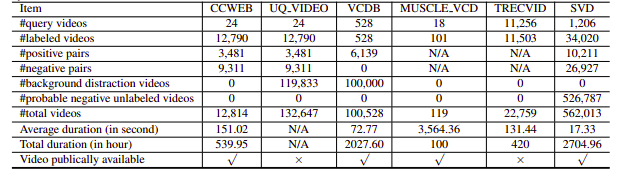
Sayangnya, kumpulan data NDVR yang diteliti memiliki resolusi rendah atau besar, spesifik domain, atau tidak tersedia untuk umum (kami juga menghubungi beberapa orang secara pribadi). Oleh karena itu, kami memutuskan untuk membuat kumpulan data khusus kecil untuk bereksperimen.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexIndeks Arus didefinisikan sebagai berikut:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueIni dipecah menjadi langkah-langkah berikut:
Di sini kita menggunakan file YAML untuk mendefinisikan Aliran dan menggunakannya untuk mengindeks data. Fungsi index mengambil parameter input_fn yang menggunakan Iterator untuk meneruskan jalur file, yang selanjutnya akan dibungkus dalam IndexRequest dan dikirim ke Aliran.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query Anda kemudian dapat membuka Jinabox dengan titik akhir khusus http://localhost:45678/api/search
Aliran kueri didefinisikan sebagai berikut:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlAlur kueri dipecah menjadi langkah-langkah berikut:


