CrawlerTutorial
1.0.0
Saat kita browsing di internet, kita sering melihat berbagai konten menarik, seperti berita, produk, video, gambar, dan lain-lain. Namun jika Anda ingin mengumpulkan informasi spesifik dalam jumlah besar dari halaman web ini, pengoperasian manual akan memakan waktu dan tenaga.
Saat ini, perayap web (Web Crawler) sangat berguna! Sederhananya, web crawler adalah program yang dapat meniru perilaku browser manusia dan secara otomatis meng-crawl informasi web. Dengan menggunakan kemampuan otomatisasi program ini, kita dapat dengan mudah "merangkak" data yang kita minati dari situs web dan kemudian menyimpan data tersebut untuk dianalisis nanti.
Cara kerja perayap web adalah dengan terlebih dahulu mengirimkan permintaan HTTP ke situs web target, kemudian memperoleh respons HTML dari situs web, menguraikan konten halaman, dan kemudian mengekstrak data yang berguna. Misalnya, jika kita ingin mengumpulkan judul, penulis, waktu, dan informasi lain dari artikel di papan gosip PTT, kita dapat menggunakan teknologi web crawler untuk secara otomatis menangkap informasi ini dan menyimpannya. Dengan cara ini Anda bisa mendapatkan informasi yang Anda perlukan tanpa menelusuri situs web secara manual.
Perayap web memiliki banyak aplikasi praktis, seperti:
Tentu saja, saat menggunakan perayap web, kami harus mematuhi persyaratan penggunaan dan kebijakan privasi situs web, dan tidak boleh merayapi informasi yang melanggar peraturan situs web. Pada saat yang sama, untuk memastikan pengoperasian normal situs web, kami juga perlu merancang strategi perayapan yang tepat untuk menghindari beban berlebihan pada situs web.
Tutorial ini menggunakan Python3 dan akan menggunakan pip untuk menginstal paket yang diperlukan. Paket-paket berikut perlu diinstal:
requests : digunakan untuk mengirim dan menerima permintaan dan tanggapan HTTP.requests_html : digunakan untuk menganalisis dan merayapi elemen dalam HTML.rich : Biarkan informasi ditampilkan ke konsol dengan indah, seperti menampilkan tabel yang indah.lxml atau PyQuery : digunakan untuk mengurai elemen dalam HTML.Gunakan instruksi berikut untuk menginstal paket-paket ini:
pip install requests requests_html rich lxml PyQueryPada bab dasar, kami akan memperkenalkan secara singkat cara mengumpulkan data dari halaman web PTT, seperti judul artikel, penulis, dan waktu.
Mari gunakan artikel pembaca versi PTT sebagai target perayap kita!
Saat merayapi laman web, kami menggunakan fungsi requests.get() untuk menyimulasikan browser mengirimkan permintaan HTTP GET untuk "menelusuri" laman web. Fungsi ini akan mengembalikan objek requests.Response , yang berisi konten respons halaman web. Namun perlu diperhatikan bahwa konten ini disajikan dalam bentuk kode sumber teks murni dan tidak dirender oleh browser. Kita bisa mendapatkannya melalui properti response.text .
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )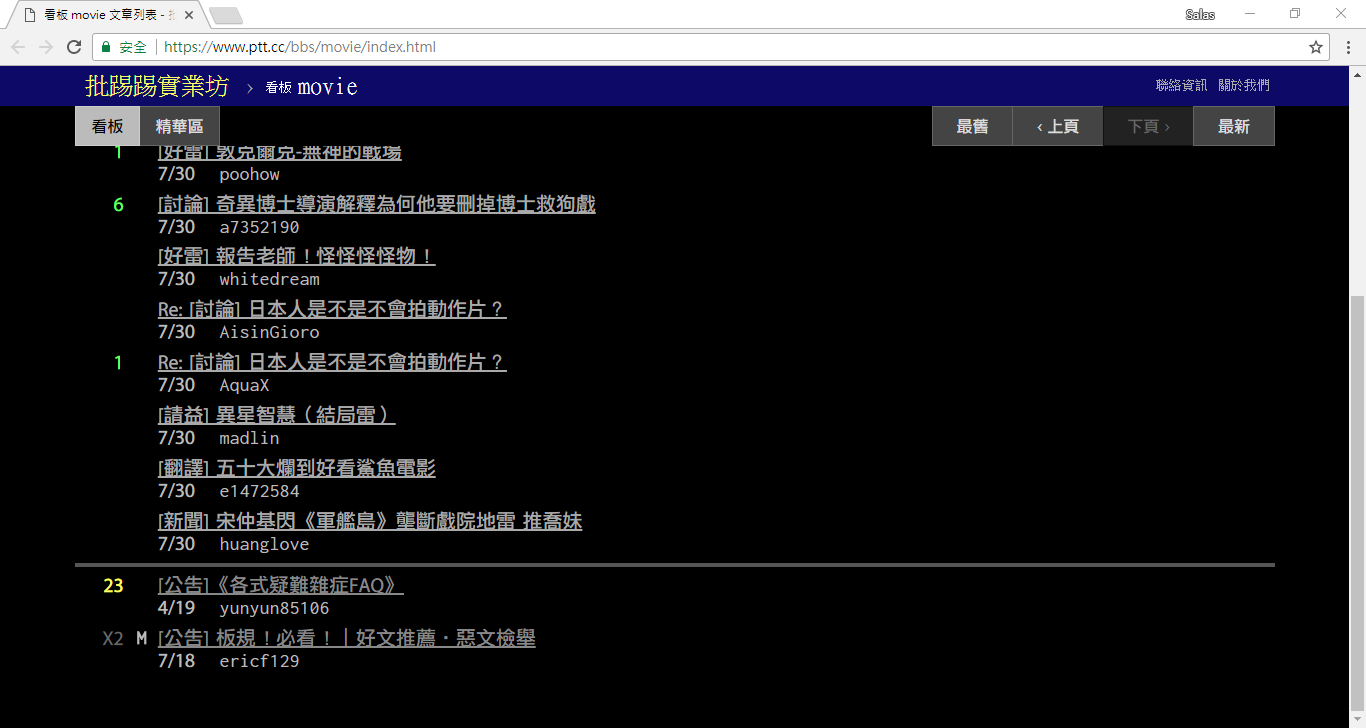
Dalam penggunaan selanjutnya, kita perlu menggunakan requests_html untuk memperluas requests Selain menjelajah seperti browser, kita juga perlu mengurai halaman web HTML. requests_html akan mengemas kode sumber teks biasa ke requests_html.HTML response.text digunakan nanti. Menulis ulang juga sangat sederhana. Gunakan session.get() untuk menggantikan requests.get() di atas.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )Namun, ketika kami mencoba menerapkan metode ini pada Gosip, kami mungkin mengalami kesalahan. Ini karena ketika kita menelusuri papan gosip untuk pertama kalinya, situs web akan mengonfirmasi apakah kita berusia di atas 18 tahun; ketika kita mengklik untuk mengonfirmasi, browser akan mencatat cookie yang sesuai sehingga kita tidak akan menanyakannya lagi di lain waktu masuk (Anda dapat mencoba menggunakan mode penyamaran untuk membuka tes dan melihat halaman beranda versi Bagua). Namun, untuk perayap web, kami perlu mencatat cookie khusus ini sehingga kami dapat berpura-pura telah lulus ujian delapan belas tahun saat menjelajah.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) Selanjutnya, kita bisa menggunakan metode response.html.find() untuk menemukan elemen dan menggunakan pemilih CSS untuk menentukan elemen target. Pada langkah ini kita dapat mengamati bahwa pada versi web PTT, informasi judul setiap artikel terletak pada tag div dengan kategori r-ent . Oleh karena itu, kita dapat menggunakan div.r-ent pemilih CSS untuk menargetkan elemen ini.
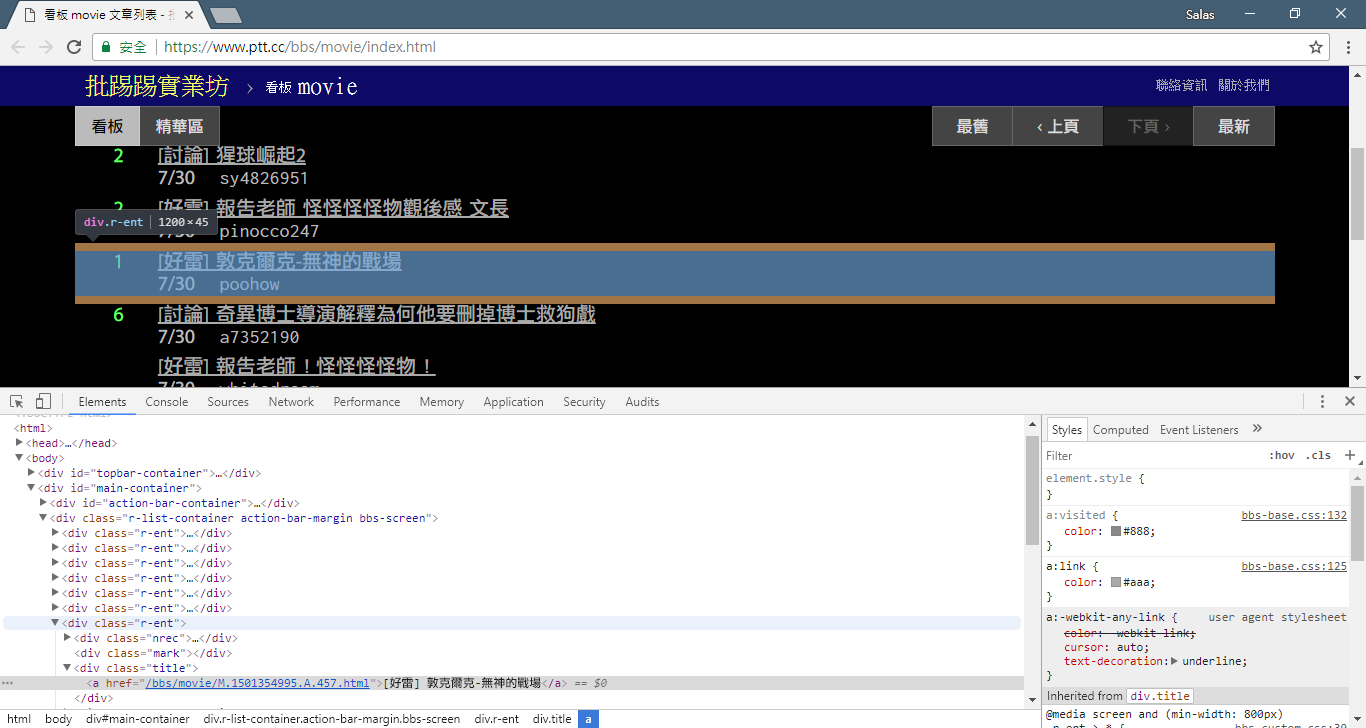
Menggunakan metode response.html.find() akan mengembalikan daftar elemen yang memenuhi ketentuan, sehingga kita dapat menggunakan perulangan for untuk memproses elemen ini satu per satu. Di dalam setiap elemen, kita dapat menggunakan metode element.find() untuk mengurai elemen lebih lanjut dan menggunakan pemilih CSS untuk menentukan informasi yang akan diekstraksi. Dalam contoh ini, kita dapat menggunakan pemilih CSS div.title untuk menargetkan elemen judul. Demikian pula, kita dapat menggunakan properti element.text untuk mendapatkan konten teks suatu elemen.
Berikut ini contoh kode menggunakan requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... Pada langkah sebelumnya, kita menggunakan metode response.html.find() untuk menemukan lokasi elemen setiap artikel. Elemen-elemen ini ditargetkan menggunakan pemilih CSS div.r-ent . Anda dapat menggunakan fitur Alat Pengembang untuk mengamati struktur elemen halaman web. Setelah membuka halaman web dan menekan tombol F12, panel alat pengembang akan ditampilkan, yang berisi struktur HTML halaman web dan informasi lainnya.
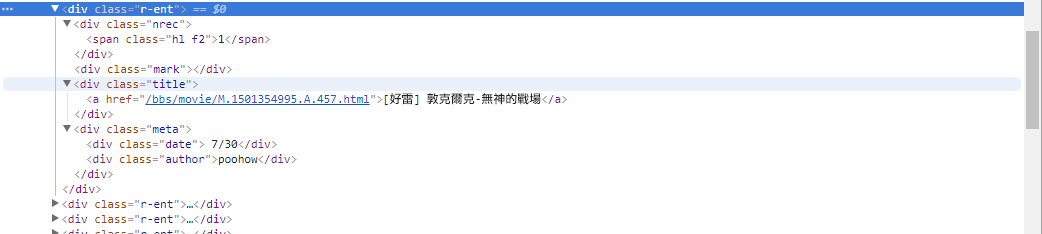
Dengan menggunakan alat pengembang, Anda dapat menggunakan penunjuk tetikus untuk memilih elemen tertentu di laman web, lalu melihat struktur HTML elemen, atribut CSS, dan detail lainnya di panel alat pengembang. Ini membantu Anda menentukan elemen mana yang akan ditargetkan dan pemilih CSS yang sesuai. Selain itu, Anda mungkin mengetahui mengapa program terkadang bermasalah? ! Melihat versi web, saya menemukan bahwa ketika sebuah artikel di halaman tersebut dihapus,結構kode sumber elemen <本文已被刪除> di halaman web berbeda dari yang asli! Jadi kita bisa lebih memperkuatnya untuk menangani situasi penghapusan artikel.
Sekarang, mari kembali ke kode contoh untuk ekstraksi informasi menggunakan requests_html :
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )Pengolahan kata keluaran:
Di sini kita dapat menggunakan rich untuk menampilkan output yang indah. Pertama, buat objek tabel rich , lalu ganti print di loop kode contoh di atas dengan add_row ke tabel. Terakhir, kami menggunakan fungsi rich print untuk menampilkan tabel dengan benar ke terminal.
Hasil eksekusi
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )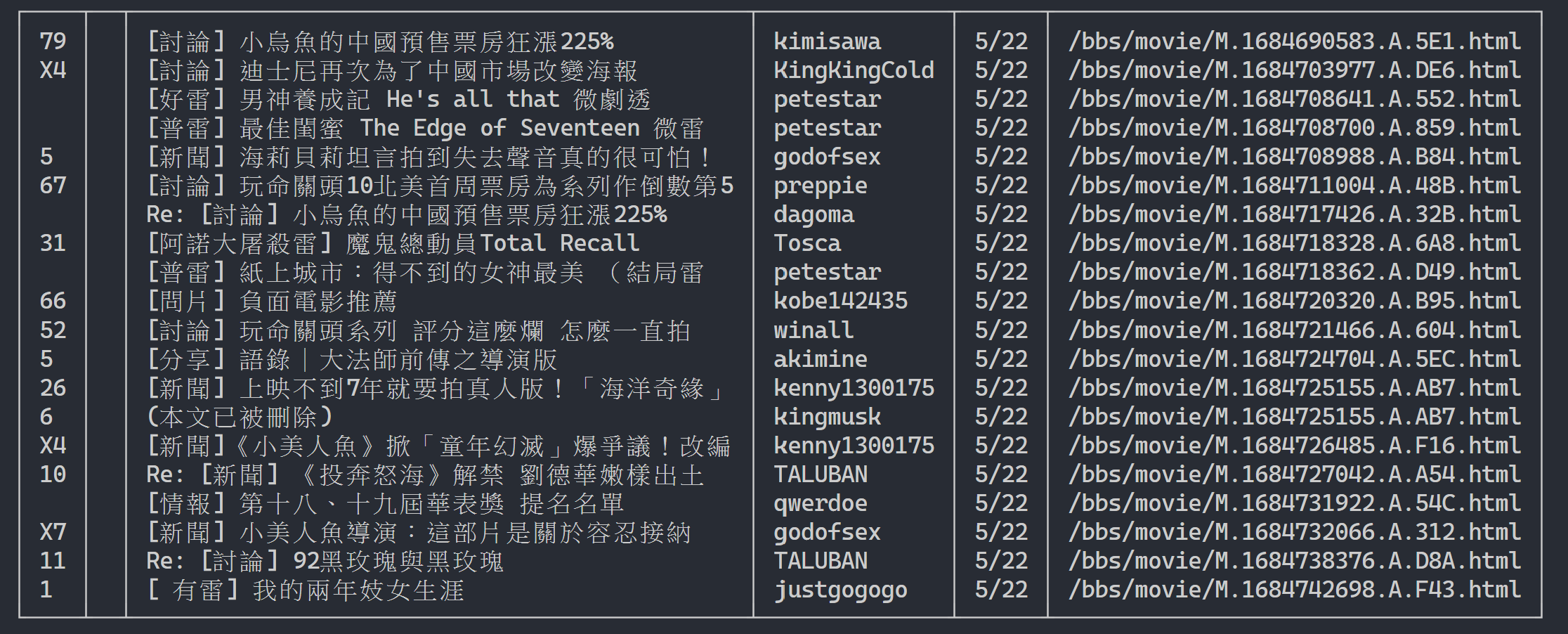
Sekarang, kita akan menggunakan "metode observasi" untuk menemukan link ke halaman sebelumnya. Tidak, saya tidak menanyakan di mana letak tombol di browser Anda, tetapi "pohon sumber" di alat pengembang. Saya yakin Anda telah menemukan bahwa hyperlink untuk lompatan halaman terletak di elemen <a class="btn wide"> dari <div class="action-bar"> . Oleh karena itu, kita dapat mengekstraknya seperti ini:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )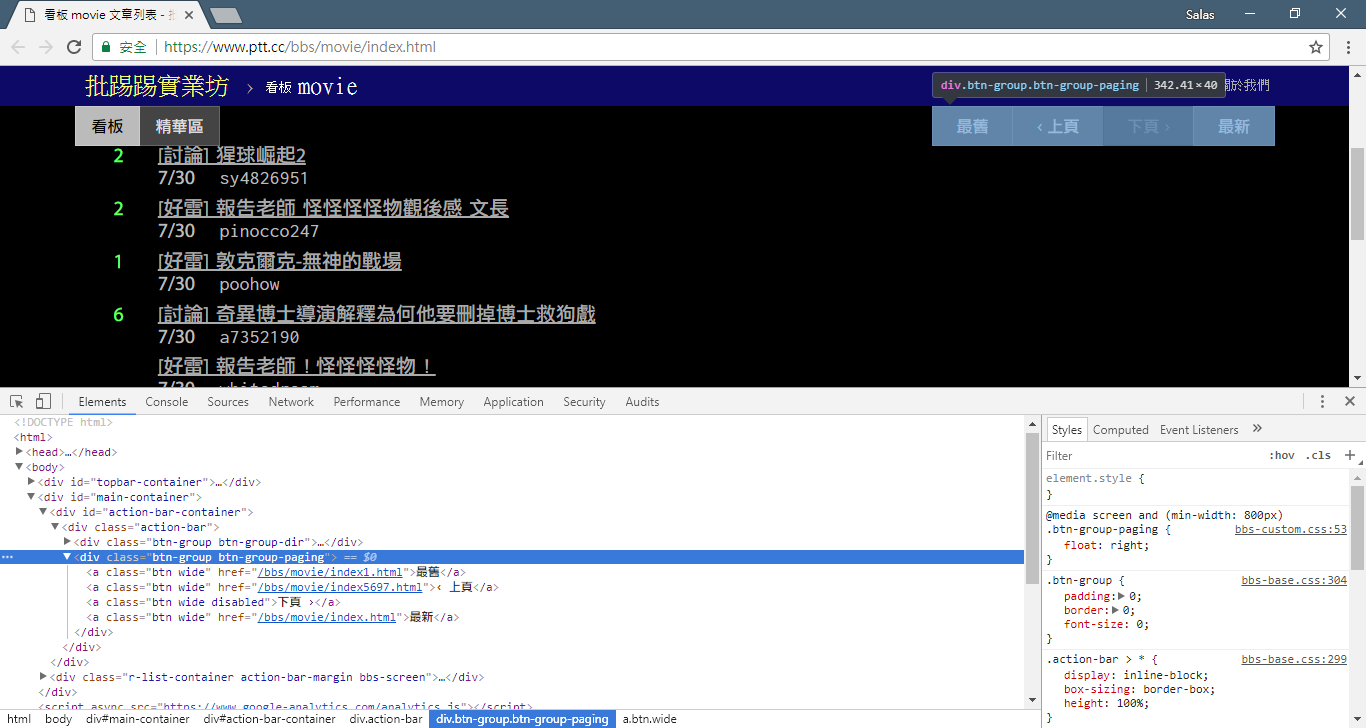
Yang kita butuhkan adalah fungsi "halaman sebelumnya". Karena artikel terbaru di PTT ditampilkan paling depan, jadi jika ingin menggali informasi harus scroll ke depan.
Jadi bagaimana cara menggunakannya? Pertama ambil href kedua di control (indeksnya 1), maka akan terlihat seperti ini /bbs/movie/index3237.html ; dan alamat website lengkap (URL) harus https://www.ptt.cc/ ( url domain), jadi gunakan urljoin() (atau koneksi string langsung) untuk membandingkan dan menggabungkan tautan beranda Film dengan tautan baru menjadi URL lengkap!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url Sekarang mari kita atur ulang fungsinya untuk memudahkan penjelasan selanjutnya. Mari kita ubah contoh pemrosesan setiap elemen artikel di Langkah 3: Mari kita lihat pesan judul ini menjadi fungsi independen parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsSelanjutnya, kita dapat menangani konten multi-halaman
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlHasil keluaran:
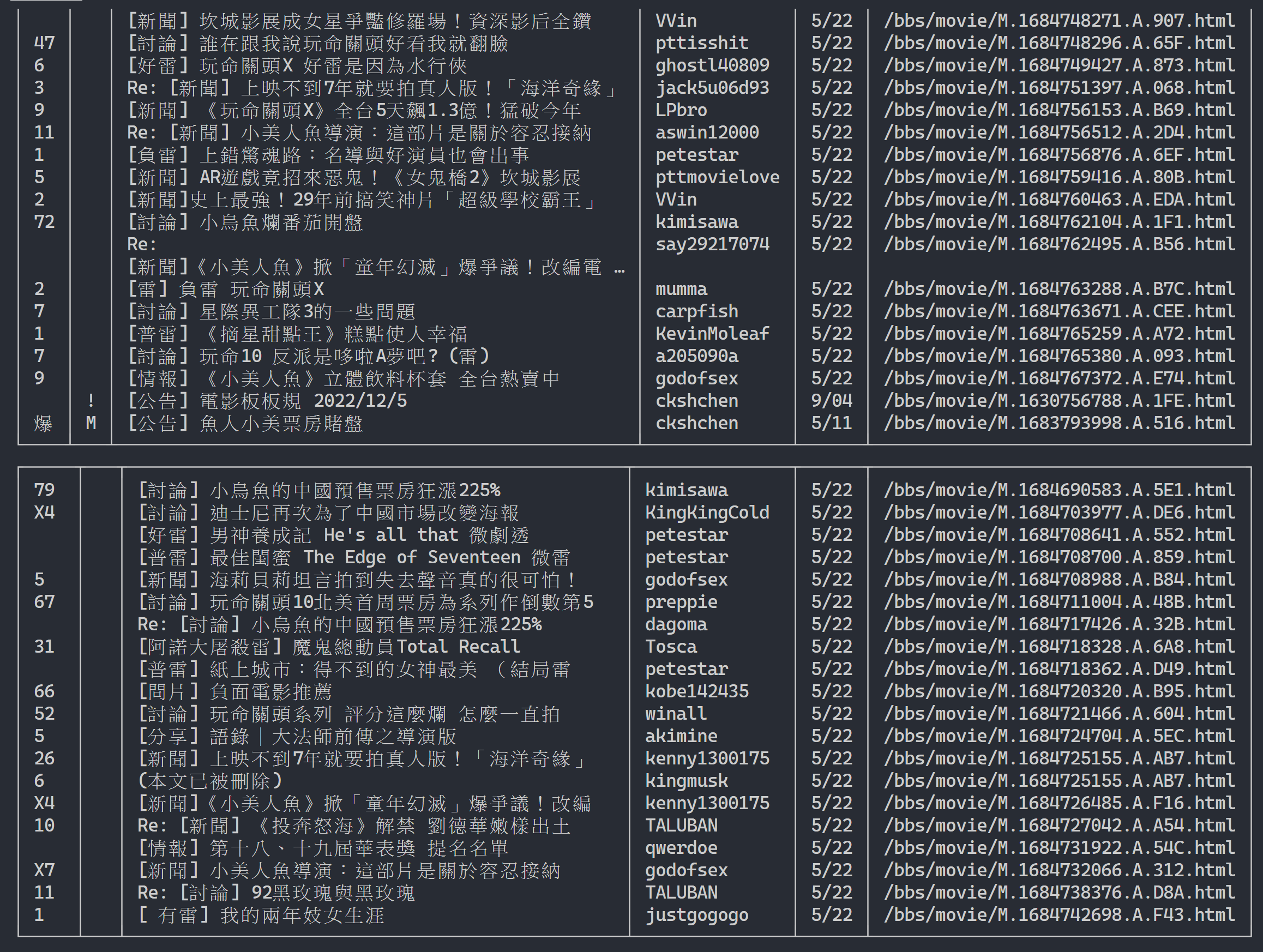
Setelah mendapatkan informasi daftar artikel, langkah selanjutnya adalah mendapatkan konten artikel (artikel PO) (konten postingan)! link dalam metadata adalah tautan setiap artikel. Kami juga menggunakan urllib.parse.urljoin untuk menggabungkan URL lengkap dan kemudian mengeluarkan HTTP GET untuk mendapatkan konten artikel. Kita dapat mengamati bahwa tugas menangkap konten setiap artikel sangat berulang dan sangat cocok untuk diproses menggunakan metode paralelisasi.
Dengan Python, Anda dapat menggunakan multiprocessing.Pool untuk melakukan pemrograman multiproses tingkat tinggi ~ Ini adalah cara termudah untuk menggunakan multi-proses dengan Python! Sangat cocok untuk skenario aplikasi SIMD (Single instruction Multiple Data) ini. Gunakan sintaks pernyataan with untuk melepaskan sumber daya proses secara otomatis setelah digunakan. Penggunaan ProcessPool juga sangat sederhana, pool.map(function, items) , yang mirip dengan konsep pemrograman fungsional. Terapkan fungsi ke setiap item, dan akhirnya dapatkan jumlah daftar hasil yang sama dengan item.
Digunakan dalam tugas merayapi konten artikel yang diperkenalkan sebelumnya:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )Terlampir hasil percobaannya:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章Dapat dilihat bahwa kecepatan eksekusi keseluruhan telah dipercepat hampir lima kali lipat, namun semakin banyak Process semakin baik. Selain spesifikasi perangkat keras seperti CPU, hal ini terutama bergantung pada keterbatasan perangkat eksternal seperti kartu jaringan dan kecepatan jaringan.
Kode di atas dapat ditemukan di ( src/basic_crawler.py )!
Fitur baru di Web PTT: Pencarian! Akhirnya tersedia di versi web
Mari gunakan juga PTT versi film sebagai target perayap kita! Konten yang dapat dicari di fitur baru ini meliputi:
Tiga yang pertama semuanya dapat menemukan aturan dari kode sumber halaman versi baru dan mengirim permintaan, tetapi pencarian jumlah tweet tampaknya tidak muncul di antarmuka UI versi web, jadi berikut adalah parameter yang ditambang oleh penulis dari PTT 網站原始碼. PTT yang biasa kita jelajahi sebenarnya mencakup server BBS (yaitu BBS) dan server Web front-end (versi web). Server Web front-end ditulis dalam bahasa Go (Golang) dan dapat langsung mengakses back-end Data dan penggunaan BBS Mode interaksi situs web umum menjadikan konten menjadi halaman web untuk dijelajahi.
Faktanya, sangat mudah untuk menggunakan fungsi-fungsi baru ini. Anda hanya perlu menggunakan permintaan HTTP GET dan menambahkan string kueri standar untuk mendapatkan informasi ini. URL endpoint yang menyediakan fungsi pencarian adalah /bbs/{看板名稱}/search . Pertama, ambil kata kunci judul sebagai contoh,
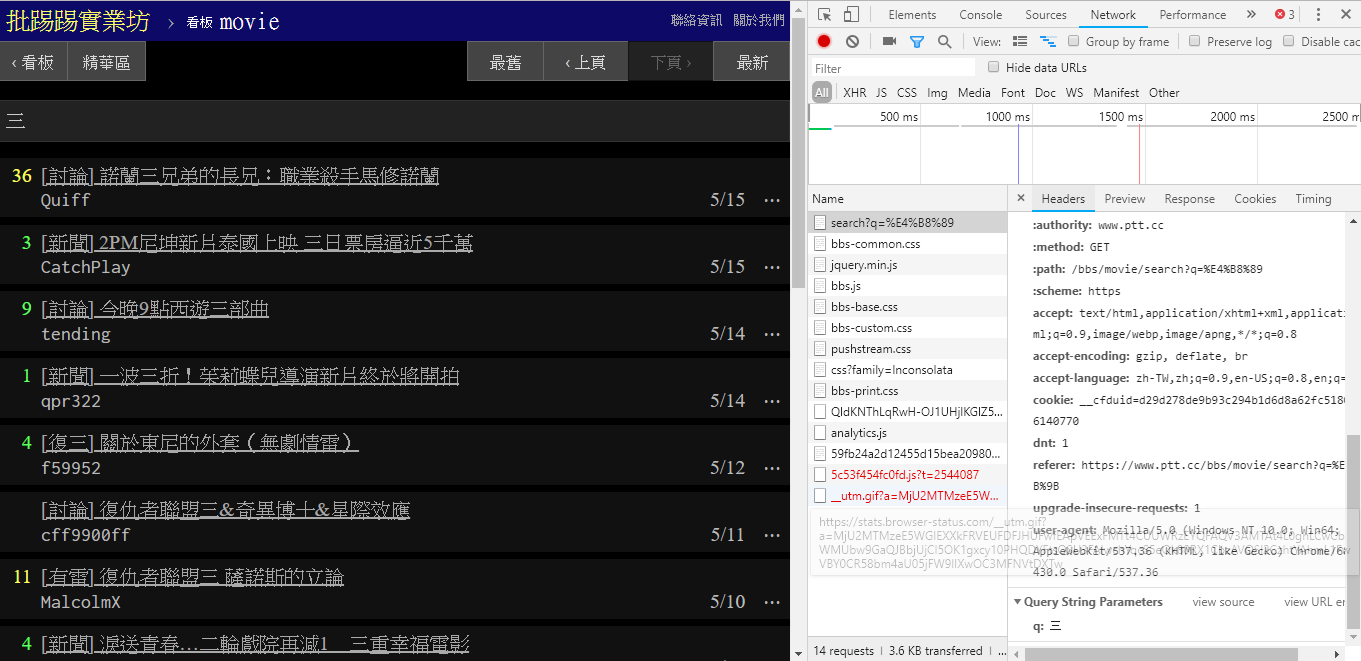
Seperti terlihat dari pojok kanan bawah gambar, saat melakukan pencarian, request GET dengan q=三sebenarnya dikirim ke endpoint , sehingga keseluruhan URL lengkapnya akan seperti https://www.ptt.cc/bbs/movie/search?q=三, URL yang disalin dari bilah alamat dapat berupa https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 karena bahasa Mandarin telah HTML dikodekan tetapi Mewakili arti yang sama. Dalam requests , jika Anda ingin menambahkan parameter kueri tambahan, Anda tidak perlu membuat sendiri formulir string secara manual. Anda hanya perlu memasukkannya ke dalam parameter fungsi melalui dict() dari param= , seperti ini:
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })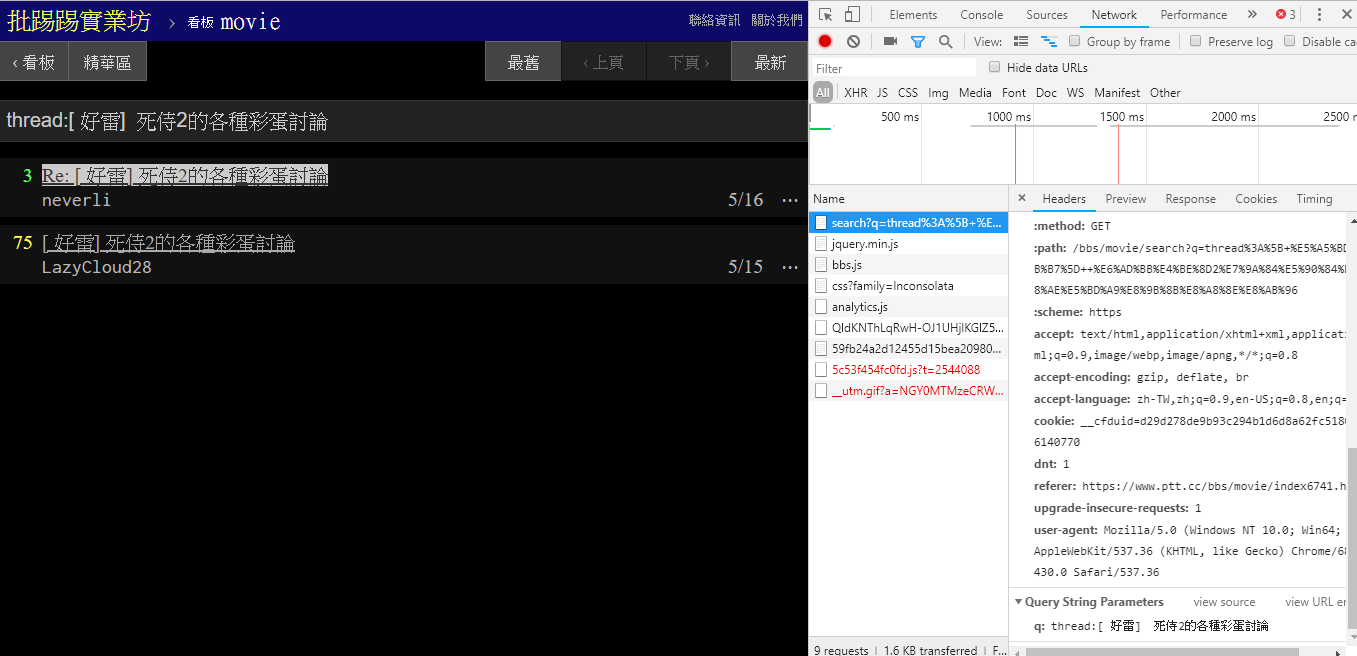
Saat mencari artikel (utas) yang sama, Anda dapat melihat dari informasi di pojok kanan bawah bahwa Anda sebenarnya merangkai thread: di depan judul dan mengirimkan kueri.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })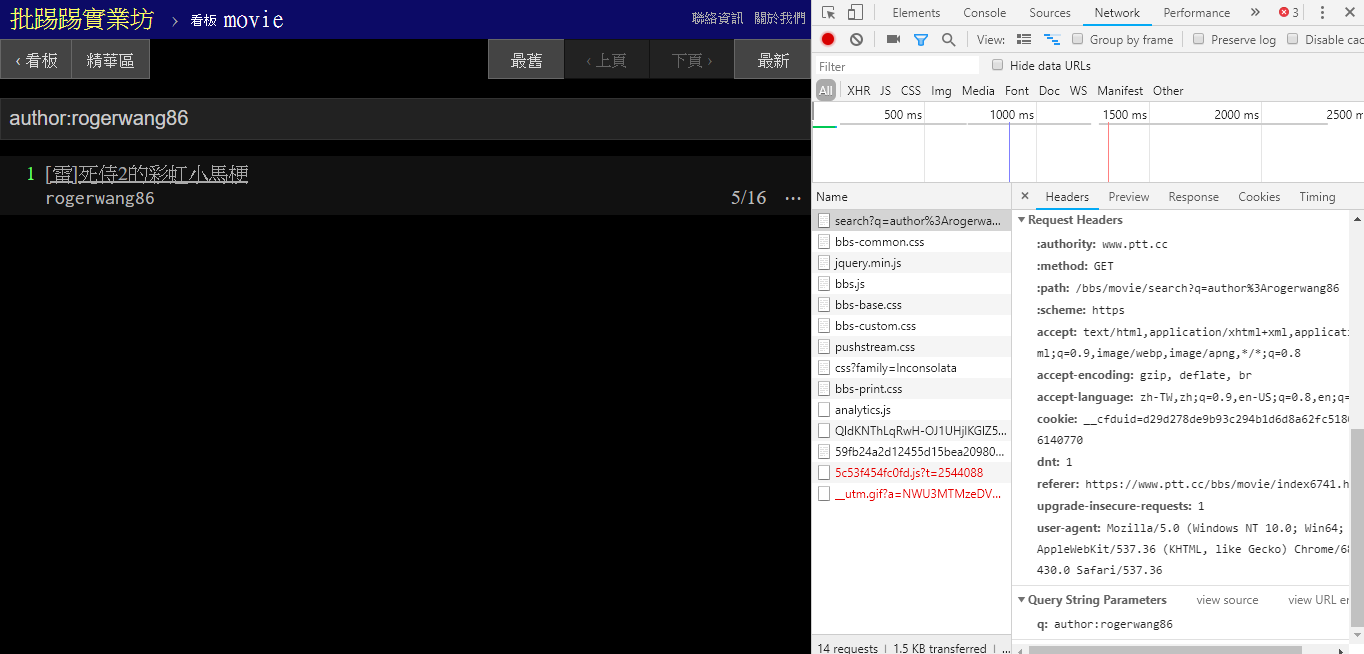
Saat mencari artikel dengan penulis (author) yang sama, juga terlihat dari informasi di pojok kanan bawah bahwa string author: dirangkai dengan nama penulis dan kemudian query dikirim.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })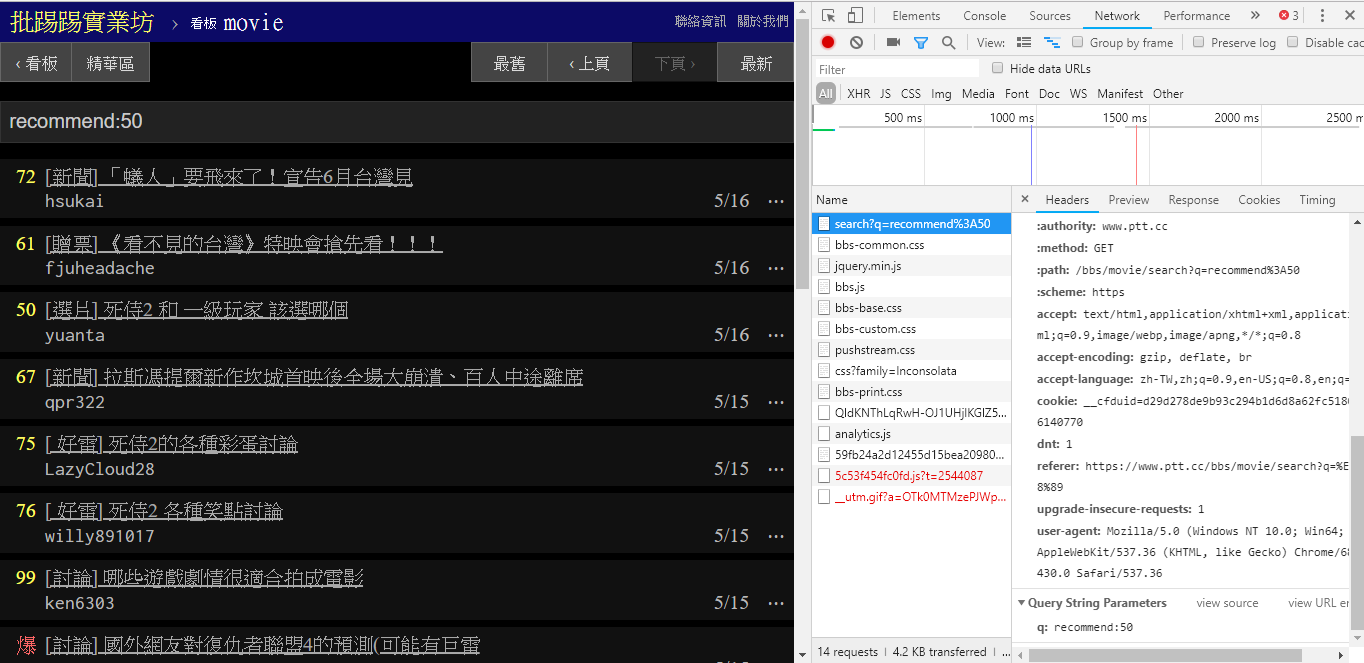
Saat mencari artikel dengan jumlah tweet lebih besar dari (recommended), string recommend: dengan jumlah minimum tweet yang ingin Anda cari dan kemudian kirimkan query. Selain itu, dapat ditemukan dari kode sumber server Web PTT bahwa jumlah tweet hanya dapat diatur dalam ±100.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })Kode sumber fungsi parsing Web PTT dari parameter ini
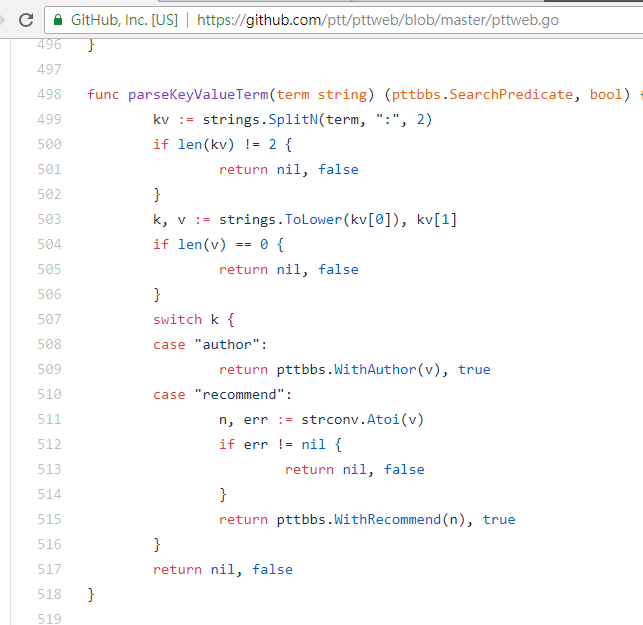
Perlu juga disebutkan bahwa penyajian akhir hasil pencarian sama dengan tata letak umum yang disebutkan di dasar, sehingga Anda dapat langsung menggunakan Don't do it again! fungsi sebelumnya.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] Ada parameter lain dalam pencarian, jumlah page sama seperti pencarian Google, hal yang dicari mungkin memiliki banyak halaman, sehingga Anda dapat menggunakan parameter tambahan ini untuk mengontrol halaman hasil mana yang ingin Anda dapatkan tanpa harus mengurai link halaman.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) Mengintegrasikan semua fungsi sebelumnya ke dalam ptt-parser dapat menyediakan fungsi baris perintah dan爬蟲dalam bentuk API yang dapat dipanggil secara terprogram.
scrapy untuk merayapi data PTT secara stabil.
Karya ini diproduksi oleh leVirve dan dirilis di bawah Lisensi Internasional Creative Commons Attribution 4.0.


