pianola
1.0.0
 pianola beraksi" style="max-width: 100%;">
pianola beraksi" style="max-width: 100%;">
pianola adalah aplikasi yang memainkan musik piano yang dihasilkan AI. Pengguna menyemai (yaitu "prompt") model AI dengan memainkan not di keyboard, atau memilih cuplikan contoh dari karya klasik.
Dalam bacaan ini, kami menjelaskan cara kerja AI dan menjelaskan secara detail arsitektur model.
Musik dapat direpresentasikan dalam banyak cara, mulai dari bentuk gelombang audio mentah hingga standar MIDI semi-terstruktur. Di pianola , kami membagi ketukan musik menjadi interval yang teratur dan seragam (misalnya nada keenam belas/semiquaver). Not-not yang dimainkan dalam suatu interval dianggap termasuk dalam langkah waktu yang sama, dan serangkaian langkah waktu membentuk suatu urutan. Dengan menggunakan urutan berbasis grid sebagai masukan, model AI memprediksi not pada langkah waktu berikutnya, yang selanjutnya digunakan sebagai masukan untuk memprediksi langkah waktu berikutnya secara autoregresif.
Selain not yang dimainkan, model juga memprediksi durasi (lamanya not ditekan) dan kecepatan (seberapa keras tuts dipukul) setiap not.
Model ini terdiri dari tiga modul: embedder, transformator, dan decoder. Modul-modul ini meminjam dari arsitektur terkenal seperti jaringan Inception, transformator LLaMA, dan rantai pengklasifikasi multi-label, tetapi diadaptasi untuk bekerja dengan data musik dan digabungkan dalam pendekatan baru.
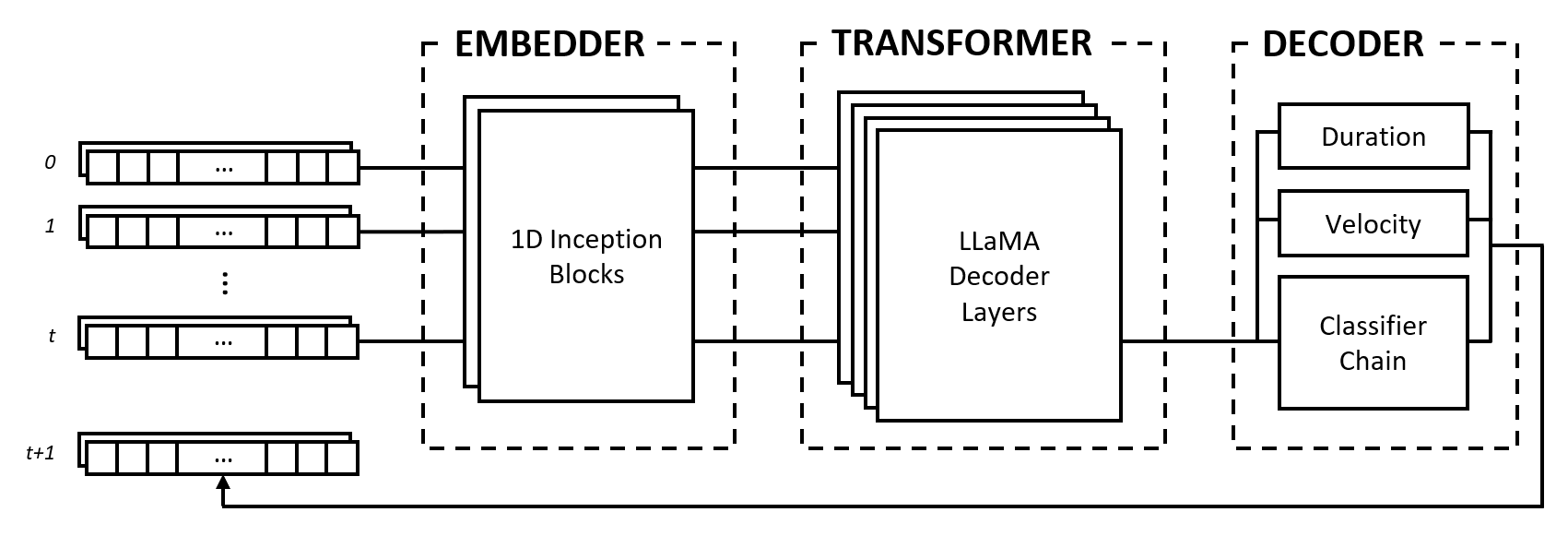
Penyemat mengubah setiap langkah waktu masukan bentuk (num_notes, num_features) menjadi vektor penyematan yang dapat dimasukkan ke dalam transformator. Namun, tidak seperti penyematan teks yang memetakan vektor one-hot ke ruang dimensi lain, kami memberikan bias induktif dengan menerapkan lapisan konvolusional dan penggabungan pada masukan. Kami melakukan ini karena beberapa alasan:
2^num_notes , dengan num_notes adalah 64 atau 88 untuk piano pendek hingga normal), oleh karena itu tidak mungkin untuk merepresentasikannya sebagai vektor one-hot.Agar penyemat dapat mempelajari jarak mana yang berguna, kami mengambil inspirasi dari jaringan Inception dan menumpuk konvolusi dengan berbagai ukuran kernel.
Modul trafo terdiri dari lapisan trafo LLaMA yang menerapkan perhatian mandiri pada urutan vektor penyematan masukan.
Seperti banyak model AI generatif, modul ini hanya menggunakan bagian "decoder" dari model Transformers asli oleh Vaswani dkk. (2017). Kami menggunakan label "transformator" di sini untuk membedakan modul ini dari modul berikutnya, yang melakukan penguraian kode sebenarnya dari keadaan yang dihasilkan oleh lapisan perhatian-diri.
Kami memilih arsitektur LLaMA dibandingkan jenis transformator lainnya terutama karena arsitektur ini menggunakan penyematan posisi putar (RoPE), yang mengkodekan posisi relatif dengan peluruhan jarak seiring dengan rentang waktu. Mengingat kami merepresentasikan data musik sebagai interval tetap, posisi relatif serta jarak antar rentang waktu merupakan informasi penting yang dapat digunakan secara eksplisit oleh transformator untuk memahami dan menghasilkan musik dengan ritme yang konsisten.
Decoder mengambil status yang dihadiri dan memprediksi not yang akan dimainkan beserta durasi dan kecepatannya. Modul ini terdiri dari beberapa subkomponen, yaitu rantai pengklasifikasi untuk prediksi nada dan multi-layer perceptrons (MLPs) untuk prediksi fitur.
Rantai pengklasifikasi terdiri dari pengklasifikasi biner num_notes , yaitu satu untuk setiap tuts piano, untuk membuat pengklasifikasi multi-label. Untuk meningkatkan korelasi antar not, pengklasifikasi biner dirangkai sedemikian rupa sehingga hasil not sebelumnya memengaruhi prediksi untuk not berikutnya. Misalnya, jika ada korelasi positif antara nada-nada oktaf, nada rendah yang aktif (misalnya C3 ) menghasilkan probabilitas yang lebih tinggi untuk memprediksi nada yang lebih tinggi (misalnya C4 ). Hal ini juga bermanfaat dalam kasus korelasi negatif, di mana seseorang dapat memilih antara dua not yang berdekatan yang menghasilkan skala mayor atau minor (misalnya CDE vs CD-Eb ), namun tidak keduanya.
Untuk efisiensi komputasi, kami membatasi panjang rantai menjadi 12 link, yaitu satu oktaf. Terakhir, strategi decoding pengambilan sampel digunakan untuk memilih nada relatif terhadap probabilitas prediksinya.
Fitur durasi dan kecepatan diperlakukan sebagai masalah regresi dan diprediksi menggunakan MLP vanilla. Meskipun fitur diprediksi untuk setiap catatan, kami menggunakan fungsi kerugian khusus selama pelatihan yang hanya menggabungkan kehilangan fitur dari catatan aktif, mirip dengan fungsi kerugian yang digunakan dalam klasifikasi gambar dengan tugas pelokalan.
Pilihan kami untuk merepresentasikan data musik sebagai grid memiliki kelebihan dan kekurangan. Kami mendiskusikan poin-poin ini dengan membandingkannya dengan kosakata berbasis peristiwa yang dikemukakan oleh Oore dkk. (2018), kontribusi yang banyak dikutip dalam generasi musik.
Salah satu keuntungan utama dari pendekatan kami adalah pemisahan pemahaman mikro dan makro musik, yang mengarah pada pemisahan tugas yang jelas antara penyemat dan transformator. Peran yang pertama adalah untuk menafsirkan interaksi nada-nada pada tingkat mikro, seperti bagaimana jarak relatif antara nada-nada membentuk hubungan musik seperti akord, dan tugas yang terakhir adalah untuk mensintesis informasi ini dalam dimensi waktu untuk memahami gaya musik secara makro. tingkat.
Sebaliknya, representasi berbasis peristiwa menempatkan seluruh beban pada model urutan untuk menafsirkan token one-hot yang dapat mewakili nada, waktu, atau kecepatan, tiga konsep berbeda. Huang dkk. (2018) menemukan bahwa perlu untuk menambahkan mekanisme perhatian relatif pada model Transformer mereka untuk menghasilkan kelanjutan yang koheren, yang menunjukkan bahwa model tersebut memerlukan bias induktif agar dapat bekerja dengan baik dengan representasi ini.
Dalam representasi grid, pilihan panjang interval merupakan trade-off antara fidelitas dan ketersebaran data. Interval yang lebih panjang mengurangi granularitas pengaturan waktu nada, mengurangi ekspresi musik, dan berpotensi menekan elemen cepat seperti getar dan nada berulang. Di sisi lain, interval yang lebih pendek secara eksponensial meningkatkan ketersebaran dengan memasukkan banyak langkah waktu kosong, yang merupakan masalah signifikan bagi model Transformer karena panjangnya dibatasi.
Selain itu, data musik dapat dipetakan ke grid baik melalui perjalanan waktu ( 1 timestep == X milliseconds ) atau seperti yang tertulis dalam skor ( 1 timestep == 1 sixteenth note/semiquaver ), masing-masing dengan trade-offnya sendiri . Representasi berbasis peristiwa menghindari masalah ini sama sekali dengan menentukan berlalunya waktu sebagai suatu peristiwa.
Terlepas dari kekurangannya, representasi grid memiliki keuntungan praktis karena lebih mudah digunakan dalam pengembangan pianola . Keluaran model dapat dibaca manusia dan jumlah langkah waktu sesuai dengan jumlah waktu yang tetap, sehingga pengembangan fitur baru menjadi lebih cepat.
Selain itu, penelitian tentang perluasan panjang urutan model Transformer dan peningkatan berkelanjutan pada perangkat keras akan semakin mengurangi masalah yang disebabkan oleh ketersebaran data, dan pada akhir tahun 2023 kita melihat model bahasa besar yang dapat menangani puluhan ribu token. Seiring dengan semakin optimalnya teknik dan perangkat keras canggih yang semakin mudah diakses, kami percaya bahwa fidelitas akan terus meningkat, seperti yang terjadi pada pembuatan gambar, sehingga menghasilkan ekspresi dan nuansa yang lebih besar dalam musik yang dihasilkan AI.
Kode sumber untuk proyek ini dapat dilihat oleh publik untuk tujuan penelitian akademis dan berbagi pengetahuan. Semua hak dipegang oleh pencipta kecuali izin telah diberikan secara eksplisit.
Ikon situs dimodifikasi dari Freepik - Flaticon.
Hubungi Outlook.com di alamat bruce <dot> ckc .


