KoMiniLM
1.0.0
Model bahasa saat ini biasanya terdiri dari ratusan juta parameter yang menghadirkan tantangan dalam penyempurnaan dan penyajian online dalam aplikasi kehidupan nyata karena keterbatasan latensi dan kapasitas. Dalam proyek ini, kami merilis model bahasa Korea yang ringan untuk mengatasi kekurangan model bahasa yang ada di atas.
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "BM-K/ KoMiniLM " ) # 23M model
model = AutoModel . from_pretrained ( "BM-K/ KoMiniLM " )
inputs = tokenizer ( "안녕 세상아!" , return_tensors = "pt" )
outputs = model ( ** inputs )** Pembaruan pada 2022.06.20 **
** Pembaruan pada 2022.05.24 **
Teacher Model : KLUE-BERT(dasar)
Distribusi Perhatian Diri dan Hubungan Nilai Perhatian Diri [Wang et al., 2020] disaring dari setiap lapisan terpisah model guru ke model siswa. Wang dkk. disuling pada lapisan terakhir trafo, namun hal tersebut tidak terjadi pada proyek ini.
| Data | Komentar berita | Artikel berita |
|---|---|---|
| ukuran | 10G | 10G |
Catatan
- Kinerja dapat lebih ditingkatkan dengan menambahkan data wiki ke pelatihan.
- Kode perayapan dan prapemrosesan untuk artikel Berita ada di sini.
{
"architectures" : [
" BertForPreTraining "
],
"attention_probs_dropout_prob" : 0.1 ,
"classifier_dropout" : null ,
"hidden_act" : " gelu " ,
"hidden_dropout_prob" : 0.1 ,
"hidden_size" : 384 ,
"initializer_range" : 0.02 ,
"intermediate_size" : 1536 ,
"layer_norm_eps" : 1e-12 ,
"max_position_embeddings" : 512 ,
"model_type" : " bert " ,
"num_attention_heads" : 12 ,
"num_hidden_layers" : 6 ,
"output_attentions" : true ,
"pad_token_id" : 0 ,
"position_embedding_type" : " absolute " ,
"return_dict" : false ,
"torch_dtype" : " float32 " ,
"transformers_version" : " 4.13.0 " ,
"type_vocab_size" : 2 ,
"use_cache" : true ,
"vocab_size" : 32000
}{
"architectures" : [
" BertForPreTraining "
],
"attention_probs_dropout_prob" : 0.1 ,
"classifier_dropout" : null ,
"hidden_act" : " gelu " ,
"hidden_dropout_prob" : 0.1 ,
"hidden_size" : 768 ,
"initializer_range" : 0.02 ,
"intermediate_size" : 3072 ,
"layer_norm_eps" : 1e-12 ,
"max_position_embeddings" : 512 ,
"model_type" : " bert " ,
"num_attention_heads" : 12 ,
"num_hidden_layers" : 6 ,
"output_attentions" : true ,
"pad_token_id" : 0 ,
"position_embedding_type" : " absolute " ,
"return_dict" : false ,
"torch_dtype" : " float32 " ,
"transformers_version" : " 4.13.0 " ,
"type_vocab_size" : 2 ,
"use_cache" : true ,
"vocab_size" : 32000
}
cd KoMiniLM -Finetune
bash scripts/run_all_ KoMiniLM .sh
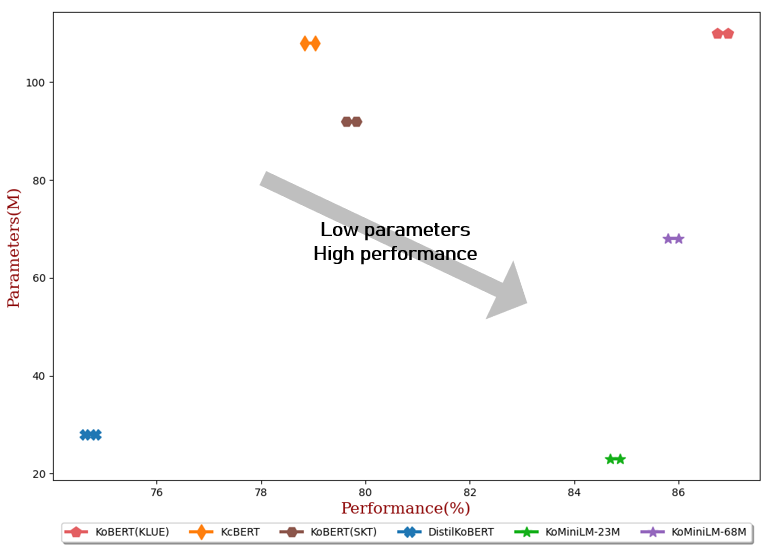
| #Param | Rata-rata | NSMC (Acc) | Naver NER (F1) | cakar (Acc) | KorNLI (Acc) | KorSTS (Tombak) | Pasangan Pertanyaan (Acc) | KorQuaD (Perkembangan) (EM/F1) | |
|---|---|---|---|---|---|---|---|---|---|
| KoBERT(KLUE) | 110M | 86,84 | 90,20±0,07 | 87,11±0,05 | 81,36±0,21 | 81,06±0,33 | 82,47±0,14 | 95,03±0,44 | 84,43±0,18 / 93,05±0,04 |
| KcBERT | 108M | 78,94 | 89,60±0,10 | 84,34±0,13 | 67,02±0,42 | 74,17±0,52 | 76,57±0,51 | 93,97±0,27 | 60,87±0,27 / 85,01±0,14 |
| KoBERT(SKT) | 92M | 79.73 | 89,28±0,42 | 87,54±0,04 | 80,93±0,91 | 78,18±0,45 | 75,98±2,81 | 94,37±0,31 | 51,94±0,60 / 79,69±0,66 |
| DistilasiKoBERT | 28M | 74.73 | 88,39±0,08 | 84,22±0,01 | 61,74±0,45 | 70,22±0,14 | 72,11±0,27 | 92,65±0,16 | 52,52±0,48 / 76,00±0,71 |
| KoMiniLM † | 68M | 85,90 | 89,84±0,02 | 85,98±0,09 | 80,78±0,30 | 79,28±0,17 | 81,00±0,07 | 94,89±0,37 | 83,27±0,08 / 92,08±0,06 |
| KoMiniLM † | 23M | 84,79 | 89,67±0,03 | 84,79±0,09 | 78,67±0,45 | 78,10±0,07 | 78,90±0,11 | 94,81±0,12 | 82,11±0,42 / 91,21±0,29 |
Karya ini dilisensikan di bawah Lisensi Internasional Creative Commons Attribution-ShareAlike 4.0.


