nnl
gpt2-xl assets
nnl adalah mesin inferensi untuk model besar pada platform GPU dengan memori rendah.
Model besar terlalu besar untuk dimasukkan ke dalam memori GPU. nnl mengatasi masalah ini dengan trade-off antara bandwidth PCIE dan memori.
Pipa inferensi yang umum adalah sebagai berikut:
Dengan kumpulan memori GPU dan defragmentasi memori, NNIL memungkinkan inferensi model besar pada platform GPU kelas bawah.
Ini hanyalah proyek hobi yang ditulis dalam beberapa minggu, saat ini hanya backend CUDA yang didukung.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aPerintah ini akan membangun dua perpustakaan statis: lib/lib nnl _cuda.a dan lib/lib nnl _cuda_kernels.a . Yang pertama adalah perpustakaan inti dengan backend CUDA di C++, dan yang kedua adalah untuk kernel CUDA.
Program demo GPT2-XL (1.6B) disediakan di sini. Program ini dapat dikompilasi dengan perintah ini:
make gpt2_1558mSetelah mengunduh semua bobot dari rilis, kita dapat menjalankan perintah berikut pada platform GPU kelas bawah seperti GTX 1050 (memori 2 GB):
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " Dan outputnya seperti ini: 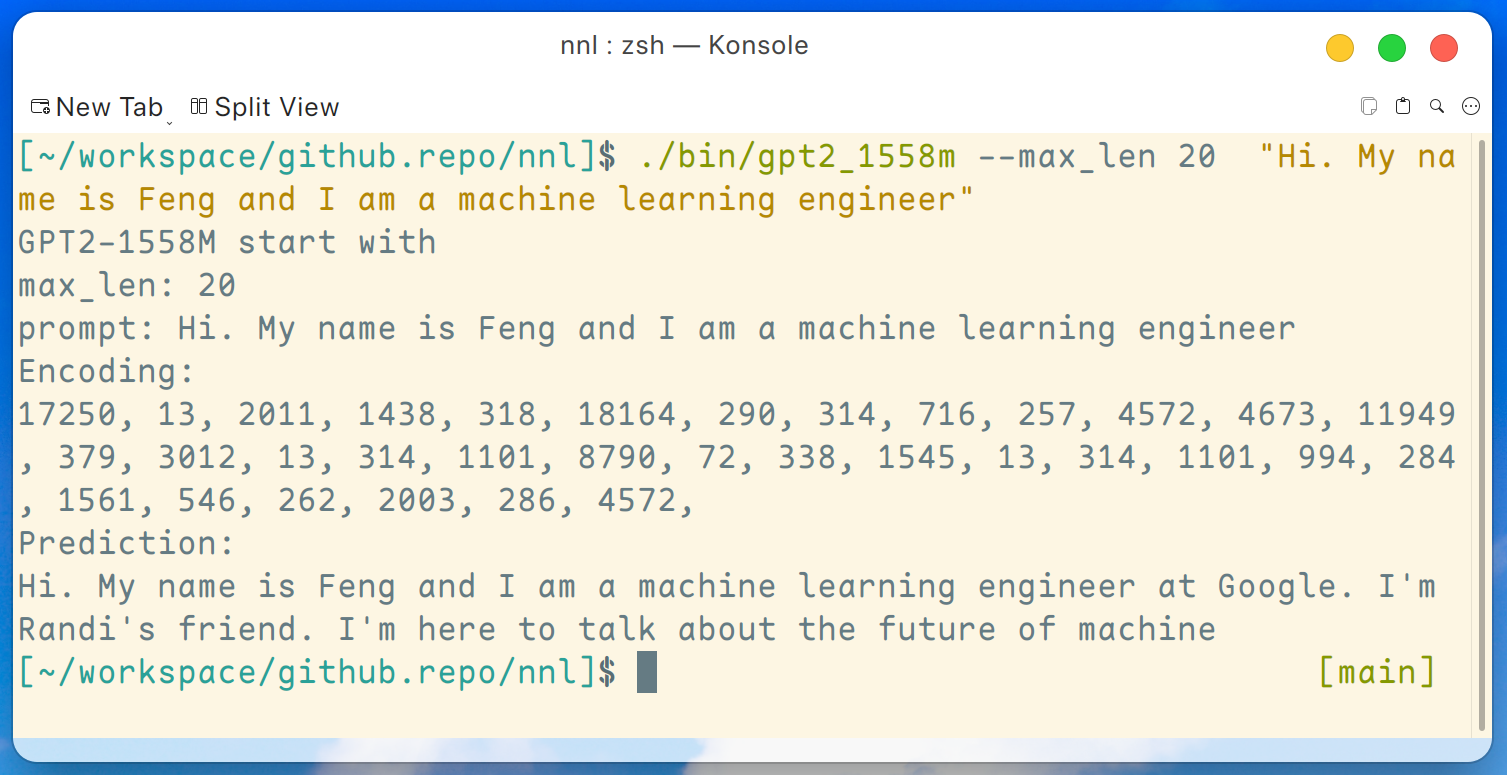
Penafian: ini hanyalah contoh yang dihasilkan oleh gpt2-xl, saya tidak bekerja di Google dan saya tidak mengenal Randi.
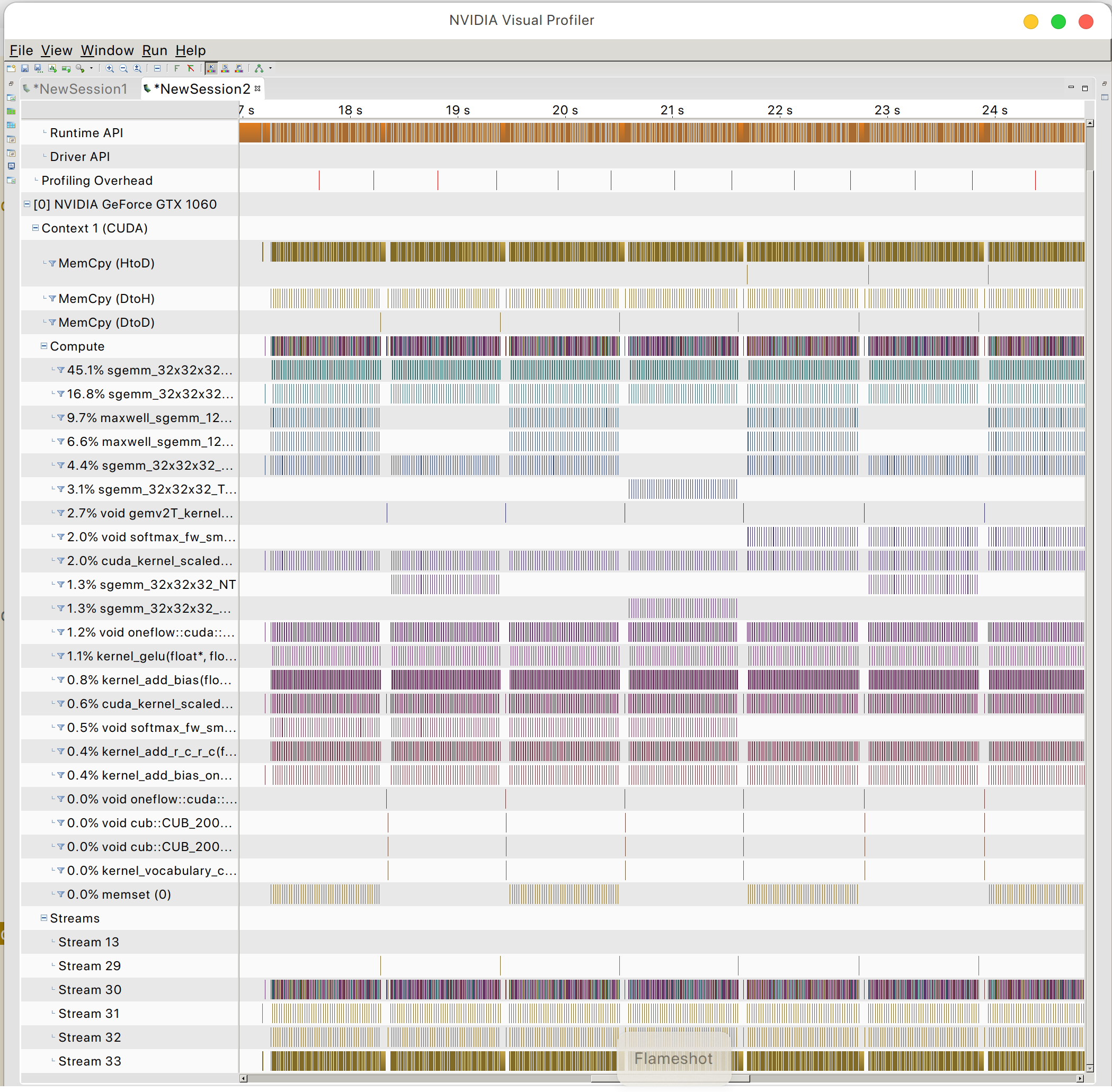
Dan Anda dapat menemukan pola akses memori GPU
PerdamaianOSL