UniIR
1.0.0
Beranda | ? Kumpulan Data (Tolok Ukur M-BEIR) | ? Pos pemeriksaan (model UniIR ) | arXiv | GitHub
Repo ini berisi basis kode untuk makalah ECCV-2024 " UniIR : Pelatihan dan Pembandingan Pengambil Informasi Multimodal Universal"
Kami mengusulkan kerangka kerja UniIR (Universal multimodal Information Retrieval) untuk mempelajari satu retriever guna menyelesaikan (mungkin) tugas pengambilan apa pun. Tidak seperti sistem IR tradisional, UniIR perlu mengikuti instruksi untuk mengambil kueri heterogen guna mengambil dari kumpulan kandidat heterogen dengan jutaan kandidat dalam modalitas yang beragam.
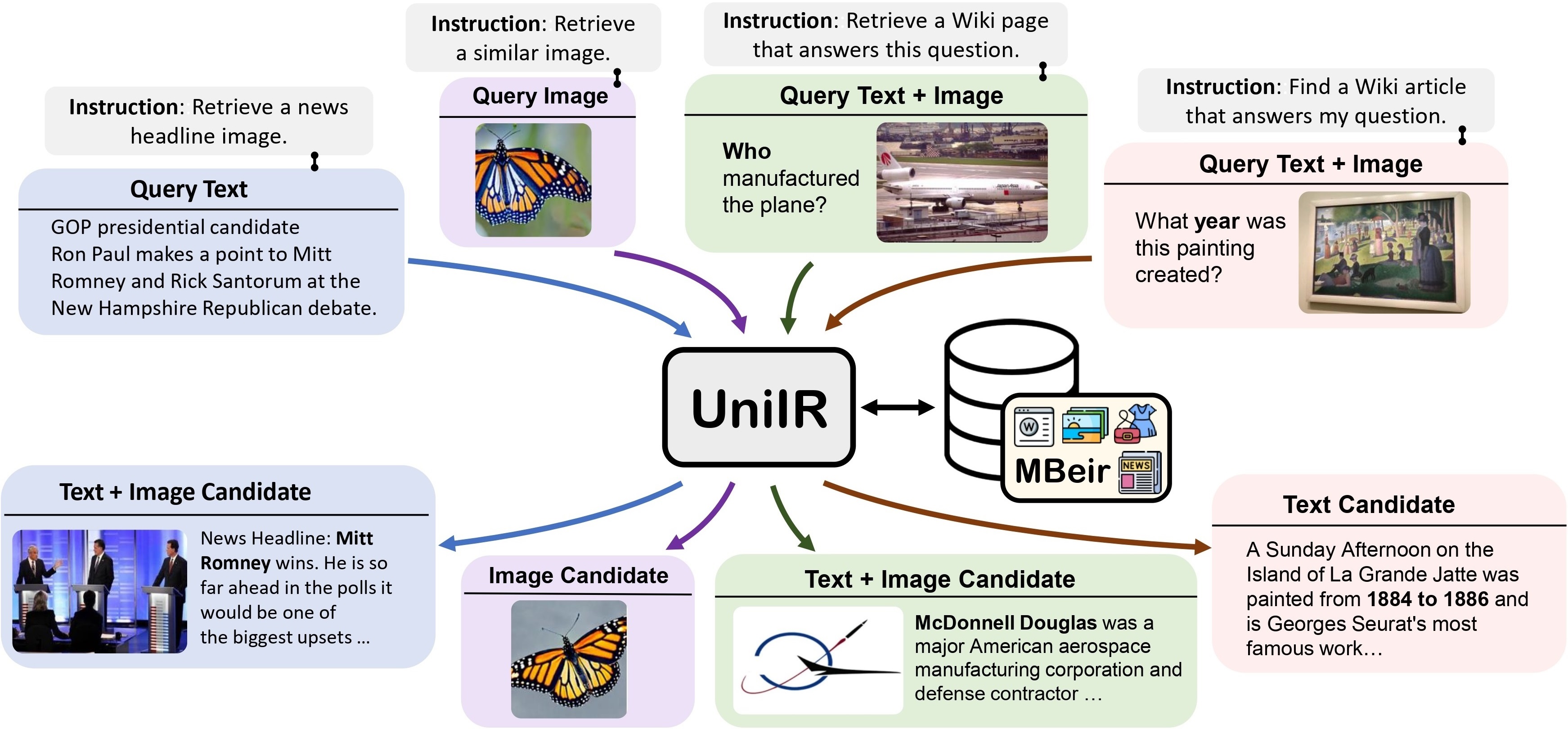 Penggoda UniIR" style="lebar: 80%; lebar maksimal: 100%;">
Penggoda UniIR" style="lebar: 80%; lebar maksimal: 100%;">
Untuk melatih dan mengevaluasi model pengambilan multimodal universal, kami membangun tolok ukur pengambilan skala besar yang diberi nama M-BEIR (Multimodal BEnchmark for Instructed Retrieval).
Kami menyediakan dataset M-BEIR di ? Kumpulan data . Silakan ikuti instruksi yang diberikan di halaman HF untuk mengunduh kumpulan data dan menyiapkan data untuk pelatihan dan evaluasi. Anda perlu menyiapkan GiT LFS dan langsung mengkloning repo:
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
Kami menyediakan basis kode untuk melatih dan mengevaluasi model UniIR CLIP-ScoreFusion, CLIP-FeatureFusion, BLIP-ScoreFusion, dan BLIP-FeatureFusion.
Siapkan basis kode proyek UniIR dan lingkungan Conda menggunakan perintah berikut:
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.ymlUntuk melatih model UniIR dari pos pemeriksaan CLIP dan BLIP yang telah dilatih sebelumnya, ikuti petunjuk di bawah. Skrip akan secara otomatis mengunduh pos pemeriksaan CLIP dan BLIP yang telah dilatih sebelumnya.
Silakan unduh benchmark M-BEIR dengan mengikuti petunjuk di bagian M-BEIR .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/ Ubah inbatch.yaml untuk penyetelan hyperparameter dan run_inbatch.sh untuk lingkungan dan jalur Anda sendiri.
UniIR _DIR di run_inbatch.sh ke direktori tempat Anda ingin menyimpan pos pemeriksaan.MBEIR_DATA_DIR di run_inbatch.sh ke direktori tempat Anda menyimpan benchmark M-BEIR.SRC_DIR di run_inbatch.sh ke direktori tempat Anda menyimpan basis kode proyek UniIR (Repo ini)..env dengan WANDB_API_KEY , WANDB_PROJECT , dan WANDB_ENTITY telah disetel.Kemudian Anda dapat menjalankan perintah berikut untuk melatih model Besar UniIR CLIP_SF.
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/ Ubah inbatch.yaml untuk penyetelan hyperparameter dan run_inbatch.sh untuk lingkungan dan jalur Anda sendiri.
bash run_inbatch.shKami menyediakan jalur evaluasi untuk model UniIR pada benchmark M-BEIR.
Silakan buat lingkungan untuk perpustakaan FAISS:
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.ymlSilakan unduh benchmark M-BEIR dengan mengikuti petunjuk di bagian M-BEIR .
Anda dapat melatih model UniIR dari awal atau mengunduh pos pemeriksaan UniIR yang telah dilatih sebelumnya dengan mengikuti petunjuk di bagian Model Zoo .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/ Ubah embed.yaml , index.yaml , retrieval.yaml dan run_eval_pipeline_inbatch.sh untuk lingkungan, jalur, dan pengaturan evaluasi Anda sendiri.
UniIR _DIR di run_eval_pipeline_inbatch.sh ke direktori tempat Anda ingin menyimpan file besar termasuk pos pemeriksaan, penyematan, indeks, dan hasil pengambilan. Kemudian Anda dapat menempatkan file clip_sf_large.pth di jalur berikut: $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthmodel.ckpt_config di file embed.yaml .MBEIR_DATA_DIR di run_eval_pipeline_inbatch.sh ke direktori tempat Anda menyimpan benchmark M-BEIR.SRC_DIR di run_eval_pipeline_inbatch.sh ke direktori tempat Anda menyimpan basis kode proyek UniIR (repo ini). Konfigurasi default akan mengevaluasi model Besar UniIR CLIP_SF pada tolok ukur M-BEIR (kumpulan kandidat heterogen 5,6 juta) dan M-BEIR_local (kumpulan kandidat homogen). UNION dalam file yaml mengacu pada M-BEIR (kumpulan kandidat heterogen 5,6 juta). Anda dapat mengikuti komentar di file yaml dan mengubah konfigurasi untuk mengevaluasi model pada benchmark M-BEIR_local saja.
bash run_eval_pipeline_inbatch.sh embed , index , logger dan retrieval_results akan disimpan di direktori $ UniIR _DIR .
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/ Demikian pula, jika Anda mengunduh model UniIR kami yang telah dilatih sebelumnya, Anda dapat menempatkan file blip_ff_large.pth di jalur berikut:
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pthKonfigurasi default akan mengevaluasi model Besar UniIR BLIP_FF pada benchmark M-BEIR dan M-BEIR_local.
bash run_eval_pipeline_inbatch.shEvaluasi UniRAG sangat mirip dengan evaluasi default dengan perbedaan sebagai berikut:
retrieval_results . Ini berguna ketika hasil yang diambil akan digunakan dalam aplikasi hilir seperti RAG.retrieve_image_text_pairs di retrieval.yaml diatur ke True , kandidat pelengkap akan diambil untuk setiap kandidat dengan modalitas text atau image saja. Dengan pengaturan ini, kandidat dan pelengkapnya akan selalu memiliki modalitas image, text . Kandidat pelengkap diambil dengan menggunakan kandidat asli sebagai kueri (misalnya, teks kueri -> gambar kandidat -> teks kandidat pelengkap ).InBatch dan inbatch dengan UniRAG dan unirag . Kami menyediakan pos pemeriksaan model UniIR di ? Pos pemeriksaan . Anda dapat langsung menggunakan pos pemeriksaan untuk tugas pengambilan atau menyempurnakan model untuk tugas pengambilan Anda sendiri.
| Nama Model | Versi | Ukuran Model | Tautan Model |
|---|---|---|---|
| UniIR (KLIP-SF) | Besar | 5,13 GB | Tautan Unduh |
| UniIR (BLIP-FF) | Besar | 7,49 GB | Tautan Unduh |
Anda dapat mengunduhnya dengan
git clone https://huggingface.co/TIGER-Lab/UniIR
BibTeX:
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

