DiSQ Score
1.0.0
Implementasi resmi untuk makalah kami: Pertanyaan Sokrates Diskursif: Mengevaluasi Kesetiaan Pemahaman Model Bahasa tentang Hubungan Wacana (2024) Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, Min-Yen Kan.ACL 2024.
Kertas PDF: https://yisong.me/publications/acl24-DiSQ-CR.pdf
Slide: https://yisong.me/publications/acl24-DiSQ-Slides.pdf
Poster: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
Apakah Anda ingin mengetahui DiSQ Score untuk model bahasa apa pun? Anda dipersilakan untuk menggunakan perintah satu baris ini!

Kami menyediakan perintah yang disederhanakan untuk mengevaluasi model bahasa (LM) apa pun yang telah dihosting di hub model HuggingFace. Anda disarankan untuk menggunakan ini untuk model baru apa pun (terutama yang tidak dipelajari dalam makalah kami).
bash scripts/one_model.sh <modelurl>
Variabel < modelurl > menentukan jalur yang dipersingkat di hub pelukan, misalnya,
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
Sebelum menjalankan file bash, harap edit file bash untuk menentukan jalur Anda ke Cache HuggingFace lokal Anda.
Misalnya, di scripts/one_model.sh:
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
Anda dapat mengubah YOUR_PATH ke lokasi direktori absolut Huggingface Cache Anda (misalnya /disk1/yisong/hf-cache ).
Kami merekomendasikan setidaknya 200GB ruang kosong.
File teks keluaran akan disimpan di data/results/verbalizations/Meta-Llama-3-8B.txt , yang berisi:
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
Kami menyimpan kumpulan data kami dalam file JSON yang terletak di data/datasets/dataset_pdtb.json dan data/datasets/dataset_ted.json . Sebagai contoh, mari kita ambil satu contoh dari dataset PDTB:
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
Berikut adalah bidang dalam entri kamus ini:
Didx : ID wacana.arg1 dan arg2 : Dua argumen.DR : Relasi wacana.Conn : Ikatan wacana.events : Daftar pasangan, menyimpan pasangan peristiwa yang diprediksi sebagai sinyal penting.context : Konteks wacana. cd DiSQ-Score
bash scripts/question_generation.sh
File bash ini akan memanggil question_generation.py untuk menghasilkan pertanyaan dalam konfigurasi berbeda.
Argumen untuk question_generation.py adalah sebagai berikut:
--dataset : Menentukan kumpulan data, baik pdtb atau ted .--modelname : Alias untuk model telah dibuat. 13b mengacu pada LLaMA2-13B, 13bchat ke LLaMA2-13B-Chat, dan vicuna-13b ke Vicuna-13B. URL spesifik untuk model ini dapat ditemukan di disq_config.py .--version : Menentukan versi templat perintah yang akan digunakan, dengan opsi v1 , v2 , v3 , dan v4 .--paraphrase : Mengganti pertanyaan standar dengan versi parafrasenya, dengan opsi p1 dan p2 . Berbeda dengan fungsi standar yang memanggil qa_utils.py , fungsi yang diparafrasekan masing-masing memanggil qa_utils_p1.py dan qa_utils_p2.py .--feature : Menentukan fitur linguistik mana yang akan digunakan untuk pertanyaan diskusi. Ciri-ciri kebahasaan meliputi conn (penghubung wacana), dan context (konteks wacana). Data QA historis memerlukan skrip terpisah. Outputnya akan disimpan di, misalnya, data/questions/dataset_pdtb_prompt_v1.json di bawah konfigurasi dataset==pdtb dan version==v1 .
Kami meminta pengguna kami untuk membuat pertanyaan sendiri karena pendekatan ini otomatis dan membantu menghemat ruang di repositori GitHub kami (yang bisa berjumlah hingga ~200 MB). Jika Anda tidak dapat menjalankan file bash, silakan hubungi kami untuk file pertanyaan.
cd DiSQ-Score
bash scripts/question_answering.sh
File bash ini akan memanggil question_answering.py untuk melakukan Pertanyaan Sokrates Diskursif (DiSQ) untuk model apa pun. question_answering.py mengambil semua argumen dari question_generation.py , ditambah argumen baru berikut:
--modelurl : Menentukan URL untuk model baru apa pun yang saat ini tidak ada dalam file konfigurasi. Misalnya, 'meta-llama/Meta-Llama-3-8B' menentukan model LLaMA3-8B dan akan menimpa argumen modelname .--hf-path : Menentukan jalur untuk menyimpan parameter model besar. Disarankan setidaknya 200 GB ruang disk kosong.--device_number : Menentukan ID GPU yang akan digunakan. Outputnya akan disimpan di, misalnya, data/results/13bchat_dataset_pdtb_prompt_v1/ . Prediksi untuk setiap pertanyaan adalah daftar token dan probabilitasnya, disimpan dalam file acar di dalam folder.
Peringatan: Model Wizard telah dihapus oleh pengembang. Kami menyarankan pengguna untuk tidak mencoba model ini. Cek thread diskusi di: https://huggingface.co/posts/WizardLM/329547800484476.
cd DiSQ-Score
bash scripts/eval.sh
File bash ini akan memanggil eval.py untuk mengevaluasi prediksi model yang diperoleh sebelumnya.
eval.py mengambil kumpulan parameter yang sama dengan question_answering.py .
Hasil evaluasi akan disimpan di disq_score_pdtb.csv jika dataset yang ditentukan adalah PDTB.
Terdapat 20 kolom pada file CSV yaitu:
taskcode : Menunjukkan konfigurasi yang sedang diuji, misalnya dataset_pdtb_prompt_v1_13bchat .modelname : Menentukan model bahasa mana yang sedang diuji.version : Menunjukkan versi prompt.paraphrase : Parameter untuk parafrase.feature : Menentukan fitur mana yang telah digunakan.Overall : DiSQ Score keseluruhan .Targeted : Skor yang ditargetkan, salah satu dari tiga komponen dalam DiSQ Score .Counterfactual : Skor kontrafaktual, salah satu dari tiga komponen dalam DiSQ Score .Consistency : Skor konsistensi, salah satu dari tiga komponen dalam DiSQ Score .Comparison.Concession : DiSQ Score untuk hubungan wacana spesifik ini.Perhatikan bahwa kami memilih hasil terbaik di antara versi v1 hingga v4 untuk meminggirkan dampak template prompt.
Untuk melakukannya, eval.py secara otomatis mengekstrak hasil terbaik:
| kode tugas | nama model | versi | parafrase | fitur | Keseluruhan | Ditargetkan | Kontrafaktual | Konsistensi | Perbandingan. Konsesi | Perbandingan. Kontras | Kontingensi. Alasan | Kontingensi. Hasil | Ekspansi.Konjungsi | Ekspansi. Kesetaraan | Ekspansi. Instansiasi | Ekspansi. Tingkat detail | Ekspansi. Substitusi | Temporal.Asynchronous | Temporal. Sinkron |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| kumpulan data_pdtb_prompt_v4_7b | 7b | v4 | 0,074 | 0,956 | 0,084 | 0,929 | 0,03 | 0,083 | 0,095 | 0,095 | 0,077 | 0,054 | 0,086 | 0,068 | 0,155 | 0,036 | 0,047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7bcchat | v1 | 0,174 | 0,794 | 0,271 | 0,811 | 0,231 | 0,435 | 0,132 | 0,173 | 0,214 | 0,105 | 0,121 | 0,15 | 0,199 | 0,107 | 0,04 | ||
| kumpulan data_pdtb_prompt_v2_13b | 13b | v2 | 0,097 | 0,945 | 0,112 | 0,912 | 0,037 | 0,099 | 0,081 | 0,094 | 0,126 | 0,101 | 0,113 | 0,107 | 0,077 | 0,083 | 0,093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13bcchat | v1 | 0,253 | 0,592 | 0,545 | 0,785 | 0,195 | 0,485 | 0,129 | 0,173 | 0,289 | 0,155 | 0,326 | 0,373 | 0,285 | 0,194 | 0,028 | ||
| kumpulan data_pdtb_prompt_v2_vicuna-13b | vicuna-13b | v2 | 0,325 | 0,512 | 0,766 | 0,829 | 0,087 | 0,515 | 0,201 | 0,352 | 0,369 | 0,0 | 0,334 | 0,46 | 0,199 | 0,511 | 0,074 |
Misalnya, tabel ini menunjukkan hasil terbaik untuk kumpulan data PDTB untuk model sumber terbuka yang tersedia, yang mereproduksi gambaran radar dalam makalah kami:
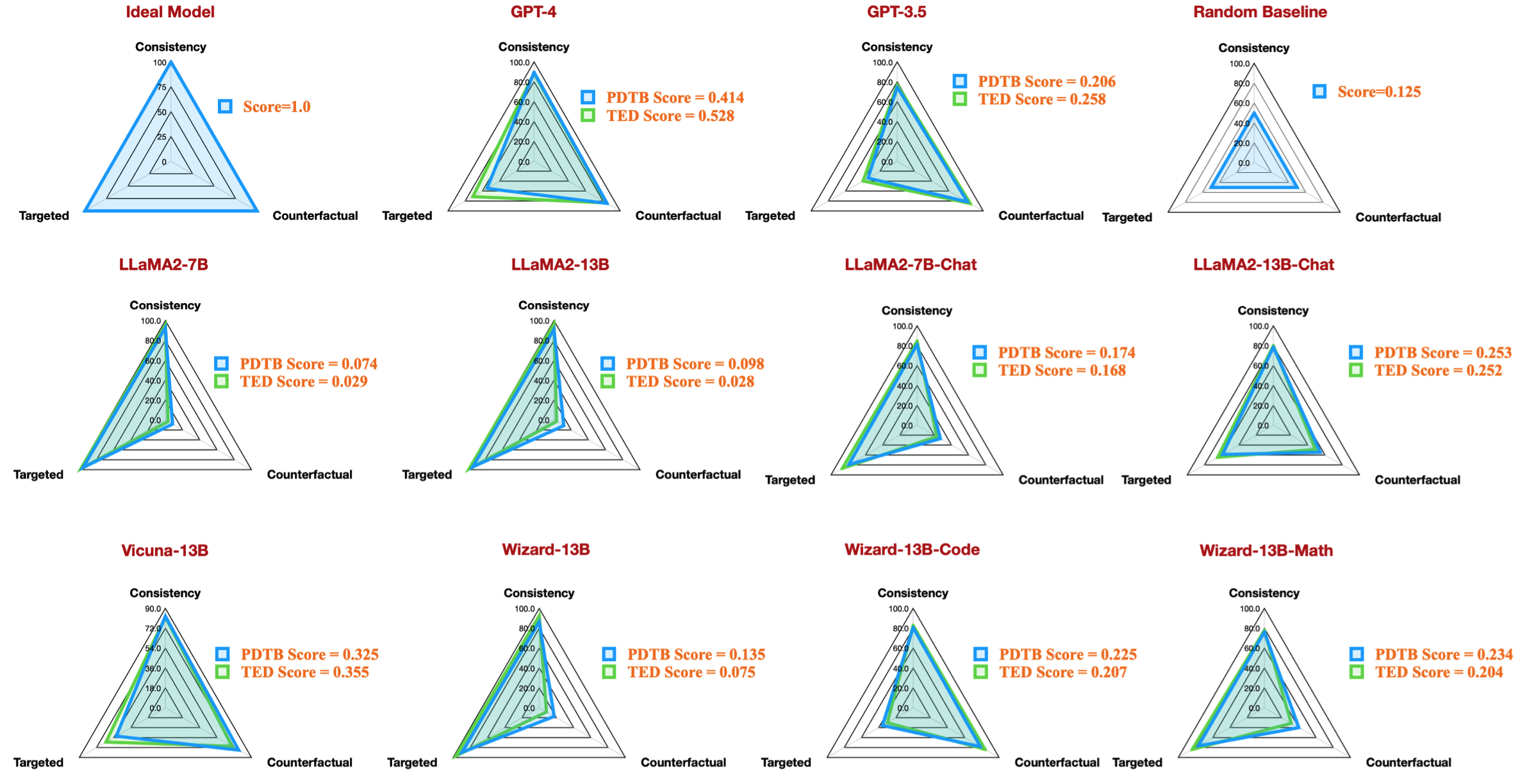
Kami juga memberikan instruksi untuk mengevaluasi pertanyaan diskusi tentang fitur linguistik:
--feature sebagai conn dan context di question_generation.py (Langkah 1) dan jalankan kembali semua eksperimen.question_generation_history.py . Skrip ini akan mengekstrak jawaban dari hasil QA yang disimpan dan menghasilkan pertanyaan baru.Bagi sebagian besar NLPers, mungkin Anda dapat menjalankan kode kami dengan lingkungan virtual (conda) yang ada.
Saat kami melakukan percobaan, versi paketnya adalah sebagai berikut:
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
Namun, kami mengamati bahwa model yang lebih baru memerlukan versi paket yang ditingkatkan:
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
Jika menurut Anda pekerjaan kami menarik, silakan mencoba kumpulan data/basis kode kami.
Silakan mengutip penelitian kami jika Anda telah menggunakan kumpulan data/basis kode kami:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
Jika Anda memiliki pertanyaan atau laporan bug, silakan ajukan masalah atau hubungi kami langsung melalui email:
Alamat email: ?@?
dimana ?️= yisong , ?= comp.nus.edu.sg
CC Oleh 4.0


