Patron
1.0.0
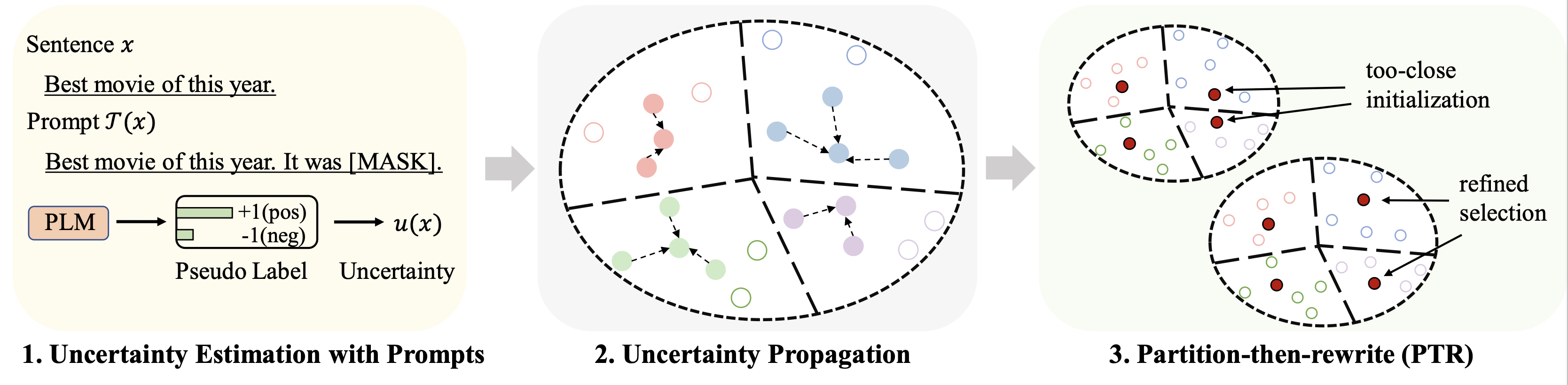
Repo ini berisi kode untuk makalah ACL 2023 kami Seleksi Data Cold-Start untuk Penyempurnaan Model Bahasa Sedikit: Pendekatan Propagasi Ketidakpastian Berbasis Prompt.
Hasil pada kumpulan data yang berbeda (menggunakan 128 label sebagai anggaran) untuk penyesuaian dirangkum sebagai berikut:
| Metode | IMDB | Penuh teriakan | Berita AG | Yahoo! | DBpedia | PERJALANAN | Berarti |
|---|---|---|---|---|---|---|---|
| Pengawasan Penuh (basis RoBERTa) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| Pengambilan Sampel Acak | 86.6 | 47.7 | 84.5 | 60.2 | 95.0 | 85.6 | 76.7 |
| Baseline Terbaik (Chang dkk. 2021) | 88.5 | 46.4 | 85.6 | 61.3 | 96,5 | 87.7 | 77.6 |
| Patron (Milik Kami) | 89.6 | 51.2 | 87.0 | 65.1 | 97.0 | 91.1 | 80.2 |
Untuk pembelajaran berbasis cepat, kami menggunakan alur yang sama dengan LM-BFF. Hasil dengan 128 label ditampilkan sebagai berikut.
| Metode | IMDB | Penuh teriakan | Berita AG | Yahoo! | DBpedia | PERJALANAN | Berarti |
|---|---|---|---|---|---|---|---|
| Pengawasan Penuh (basis RoBERTa) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| Pengambilan Sampel Acak | 87.7 | 51.3 | 84.9 | 64.7 | 96.0 | 85.0 | 78.2 |
| Baseline Terbaik (Yuan dkk., 2020) | 88.9 | 51.7 | 87.5 | 65.9 | 96.8 | 86.5 | 79.5 |
| Patron (Milik Kami) | 89.3 | 55.6 | 87.8 | 67.6 | 97.4 | 88.9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
Kami menggunakan empat kumpulan data berikut untuk eksperimen utama.
| Kumpulan data | Tugas | Jumlah Kelas | Jumlah Data Tak Berlabel/Data Uji |
|---|---|---|---|
| IMDB | Sentimen | 2 | 25k/25k |
| Penuh teriakan | Sentimen | 5 | 39k/10k |
| Berita AG | Topik Berita | 4 | 119k/7.6k |
| Yahoo! Jawaban | Topik QA | 5 | 180k/30.1k |
| DBpedia | Topik Ontologi | 14 | 280k/70k |
| PERJALANAN | Topik Pertanyaan | 6 | 5rb/0,5rb |
Data yang diolah dapat dilihat di tautan ini. Folder untuk meletakkan dataset tersebut akan dijelaskan pada bagian berikut.
Jalankan perintah berikut
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
Kami memberikan prediksi semu yang diperoleh melalui petunjuk di tautan di atas untuk kumpulan data. Silakan merujuk ke makalah asli untuk detailnya.
Jalankan perintah berikut (contoh pada dataset AG News)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
Beberapa hyperparameter penting:
rho : parameter yang digunakan untuk propagasi ketidakpastian dalam Persamaan. 6 kertasbeta : regularisasi jarak dalam Persamaan. 8 kertasgamma : bobot suku regularisasi dalam Persamaan. 10 kertas Lihat folder finetune untuk petunjuk rinci.
Lihat folder prompt_learning untuk petunjuk rinci.
Lihat tautan ini sebagai saluran untuk menghasilkan prediksi berbasis perintah. Perhatikan bahwa Anda perlu menyesuaikan verbalisasi dan templat cepat Anda.
Untuk menghasilkan penyematan dokumen, Anda dapat mengikuti perintah di atas dengan menggunakan SimCSE.
Setelah Anda membuat indeks untuk data yang dipilih, Anda dapat menggunakan alur dalam Running Fine-tuning Experiments dan Running Prompt-based Learning Experiments untuk beberapa kali percobaan penyesuaian dan pembelajaran berbasis cepat.
Silakan mengutip makalah berikut jika Anda merasa repo ini bermanfaat untuk penelitian Anda. Terima kasih sebelumnya!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
Kami ingin mengucapkan terima kasih kepada penulis repo SimCSE dan OpenPrompt atas kode yang terorganisir dengan baik.


