JustJoking.ai
1.0.0
Dalam proyek ini saya telah melatih model transformator untuk menghasilkan lelucon pendek. Kemudian dengan sedikit modifikasi pada metode inferensi saya dapat menggunakan model yang sama sehingga dengan memberikan string awal sebagai masukan, model mencoba menyelesaikannya dengan cara yang lucu.
Ada dua buku catatan yang keduanya melakukan tugas yang sama.
Hasil generasi lelucon 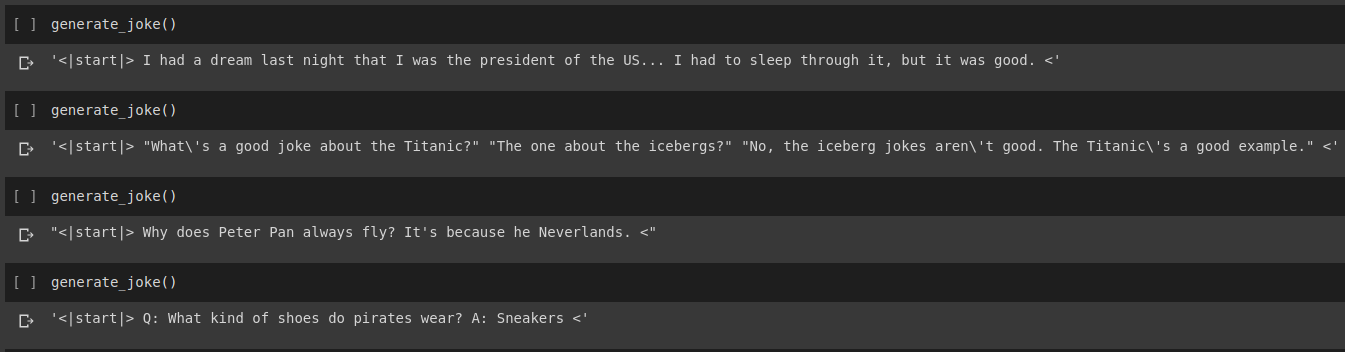
Hasil penyelesaian kalimat 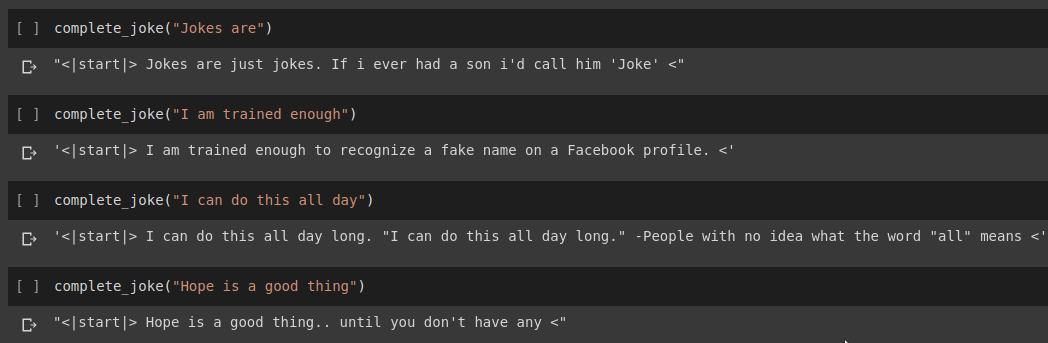
Hasil 
Untuk tugas kita, kita akan menggunakan dataset yang disediakan di Kaggle. Ini adalah csv yang berisi lebih dari 200.000 Lelucon Singkat yang diambil dari Reddit.
Catatan : Karena kumpulan data tersebut dihapus begitu saja dari berbagai subreddit, sejumlah besar lelucon dalam kumpulan data tersebut cukup rasis dan seksis. Karena AI mana pun mengasumsikan data pelatihannya sebagai sumber pengetahuan tunggal, terkadang model kami akan menghasilkan lelucon serupa.
Setelah kami memberi token pada string lelucon kami, kami menambahkan start_token dan end_token di akhir daftar yang diberi token. Selain itu, karena string lelucon kami bisa memiliki panjang yang berbeda, kami juga menerapkan padding di semua string ke max_length yang ditentukan sehingga semua tensor memiliki bentuk yang sama di kumpulan kami.
Kode untuk ini dapat ditemukan di notebook Joke Generation.ipynb . Dalam hal ini kita akan mengimpor Model GPT2Tokenizer dan TFGPT2LMHead dari perpustakaan HuggingFace. Kode ini ditulis dalam Tensorflow2. Buku catatan tersebut memiliki komentar yang memberikan penjelasan tentang kode tersebut di tempat yang sesuai. Selain itu, Dokumen HuggingFace menyediakan dokumentasi yang baik tentang parameter masukan dan nilai kembalian model. Untuk implementasi berbasis PyTorch, lihat repo Humour.ai Tanul Singh
Kode untuk ini dapat ditemukan di notebook Joke_Completion_Pure_TF2_Implementation.ipynb . Mengambil proyek ini selangkah lebih jauh untuk memahami lebih dalam tentang cara kerjanya, saya mencoba membangun transformator tanpa perpustakaan eksternal. Saya telah mengacu pada tutorial Transformers yang disediakan oleh Tensorflow dan telah meletakkan beberapa penjelasan yang disebutkan dalam tutorialnya di buku catatan saya dengan penjelasan lebih lanjut sehingga mudah untuk memahami apa yang sedang terjadi.
Saya pertama kali membuat tokenizer untuk kumpulan data kami dan memberi token pada string yang menggunakannya. Kemudian, buat lapisan untuk Positional Encodings dan MultiHeadAttention . Selain itu, saya menggunakan Lambda layer untuk membuat masker yang sesuai untuk data kita.
Kemudian saya membuat decoder layer tunggal untuk dekoder kami. Berikut ini adalah arsitektur lapisan dekoder tunggal.
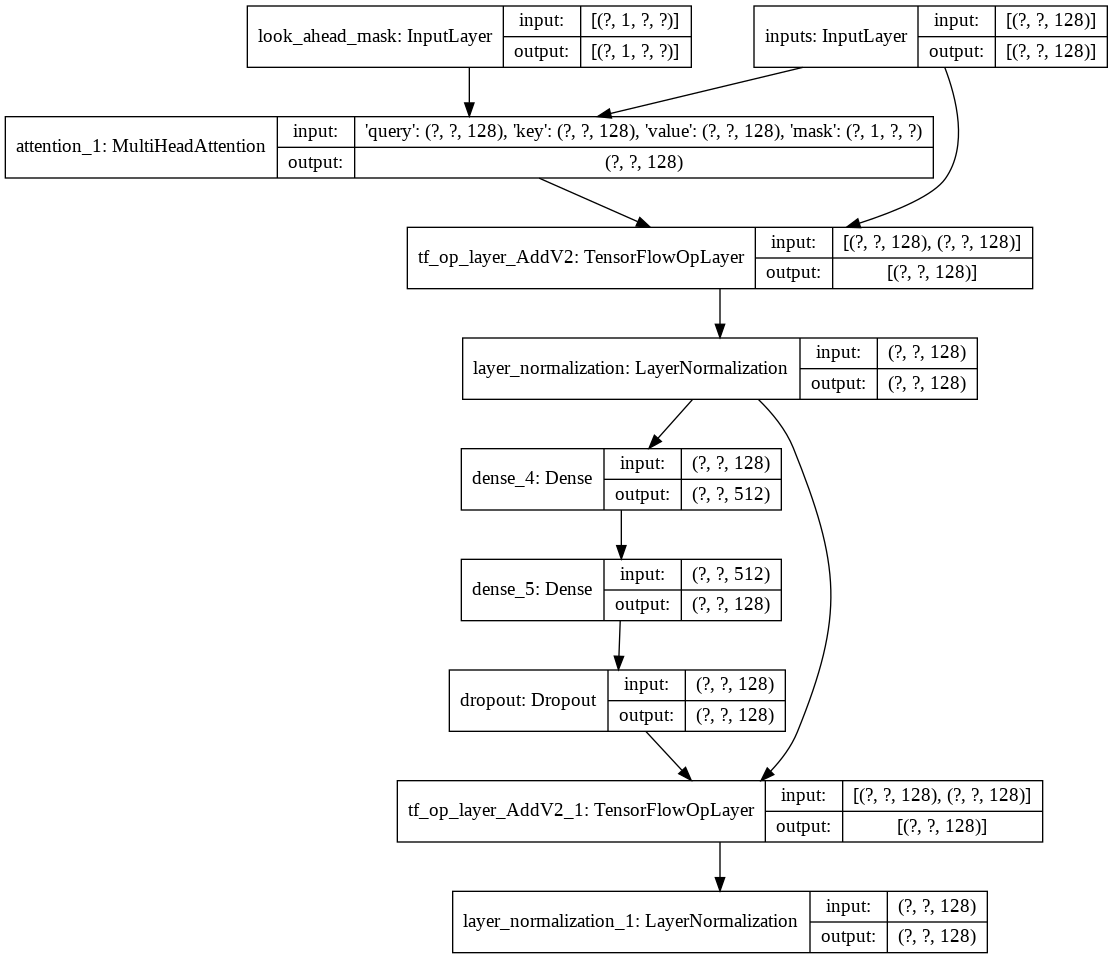
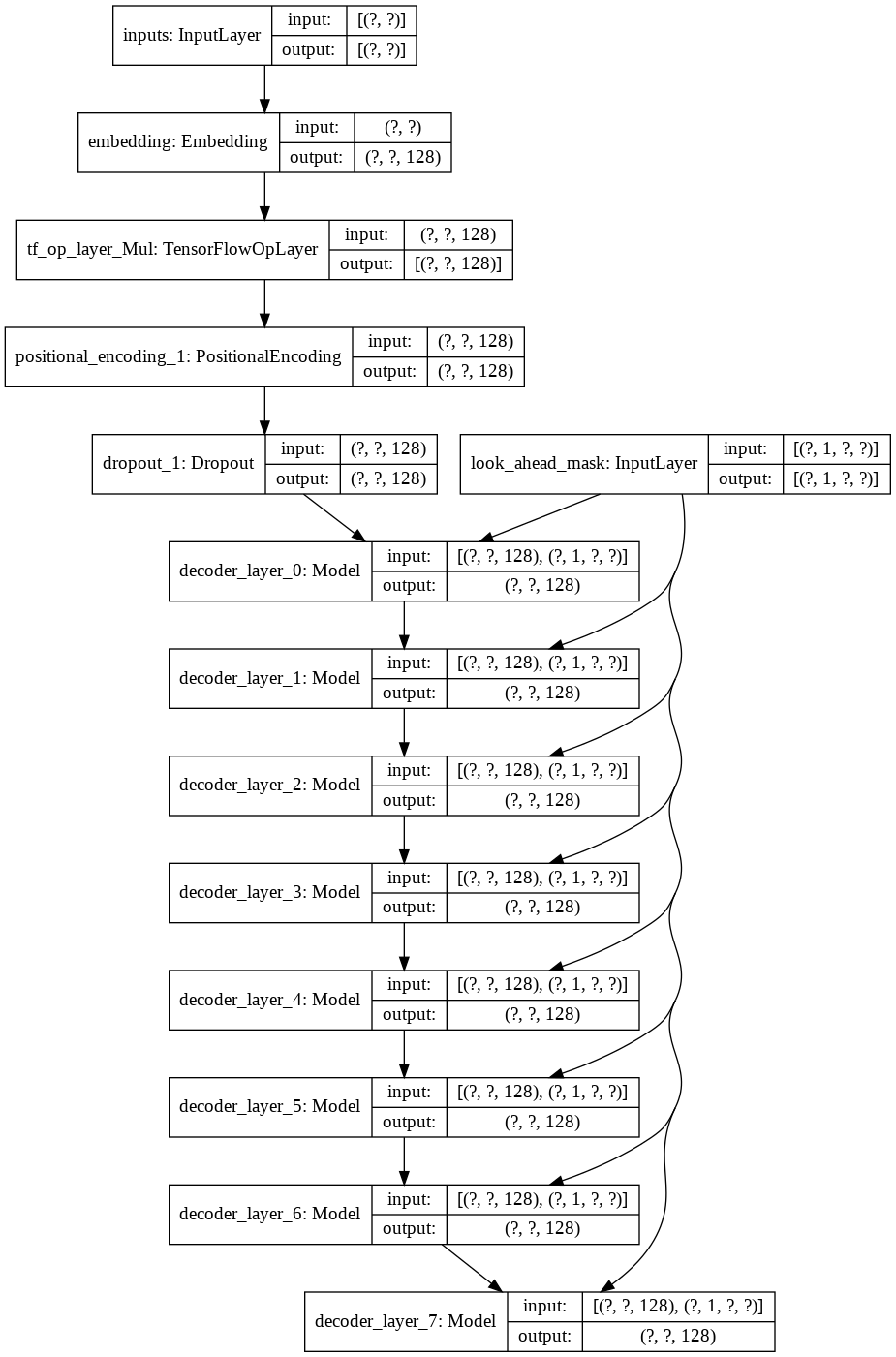
Untuk model transformer akhir, dibutuhkan token masukan, meneruskannya melalui lapisan lamda untuk mendapatkan masker dan meneruskan masker dan token ke Dekoder Bahasa yang keluarannya kemudian diteruskan melalui Lapisan Padat. Berikut adalah arsitektur model akhir kami.