CTCWordBeamSearch
1.0.0
Dekoder Connectionist Temporal Classification (CTC) dengan kamus dan Model Bahasa (LM).
pip install .tests/ dan jalankan pytest untuk memeriksa apakah instalasi berhasil Contoh mainan berikut menunjukkan cara menggunakan pencarian berkas kata. Model hipotetis (misalnya model pengenalan teks) mampu mengenali 3 karakter berbeda: "a", "b" dan " " (spasi). Kata-kata pada contoh mainan tersebut boleh mengandung karakter "a" dan "b" (tetapi bukan " " yang merupakan pemisah kata). Model bahasa dilatih dari korpus teks yang hanya berisi dua kata: “a” dan “ba”.
Dalam cuplikan kode ini, sebuah instance pencarian berkas kata dibuat, dan array numpy berbentuk TxBx(C+1) didekodekan:
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )Decoder mengembalikan daftar dengan string label yang didekodekan untuk setiap elemen batch. Untuk akhirnya mendapatkan string karakter, petakan setiap label ke karakter yang sesuai:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )Contoh:
tests/test_word_beam_search.py Parameter konstruktor kelas WordBeamSearch :
0<len(wordChars)<len(chars) . Jika hanya satu kata yang harus dideteksi, tidak diperlukan karakter pemisah, oleh karena itu kedua parameter mungkin juga sama: 0<len(wordChars)<=len(chars) Masukan ke metode WordBeamSearch.compute :
Pencarian berkas kata adalah algoritma decoding CTC. Ini digunakan untuk tugas pengenalan urutan seperti pengenalan teks tulisan tangan atau pengenalan ucapan otomatis.
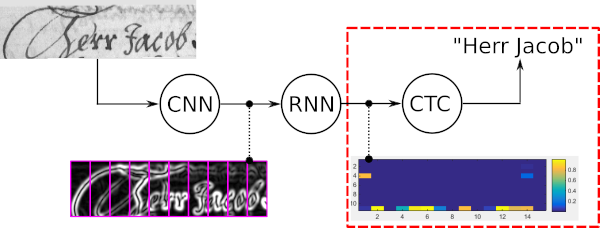
Empat properti utama pencarian berkas kata adalah:
Contoh berikut menunjukkan kasus penggunaan pencarian berkas kata bersama dengan hasil yang diberikan oleh lima dekoder berbeda. Penguraian kode jalur terbaik dan pencarian berkas vanila menghasilkan kata-kata yang salah karena dekoder ini hanya menggunakan keluaran berisik dari model optik. Memperluas pencarian pancaran vanilla dengan LM tingkat karakter akan meningkatkan hasil dengan hanya mengizinkan kemungkinan urutan karakter. Pengoperan token menggunakan kamus dan LM tingkat kata sehingga membuat semua kata menjadi benar. Namun, ia tidak dapat mengenali string karakter sembarangan seperti angka. Pencarian berkas kata mampu mengenali kata-kata dengan menggunakan kamus, namun juga mampu mengidentifikasi karakter non-kata dengan benar.

Informasi lebih lanjut:
extras/prototype/extras/tf/ Silakan kutip makalah berikut jika Anda menggunakan pencarian berkas kata dalam pekerjaan penelitian Anda.
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


