DialogStudio
1.0.0

Kertas, Wajah Pelukan, Model, Twitter
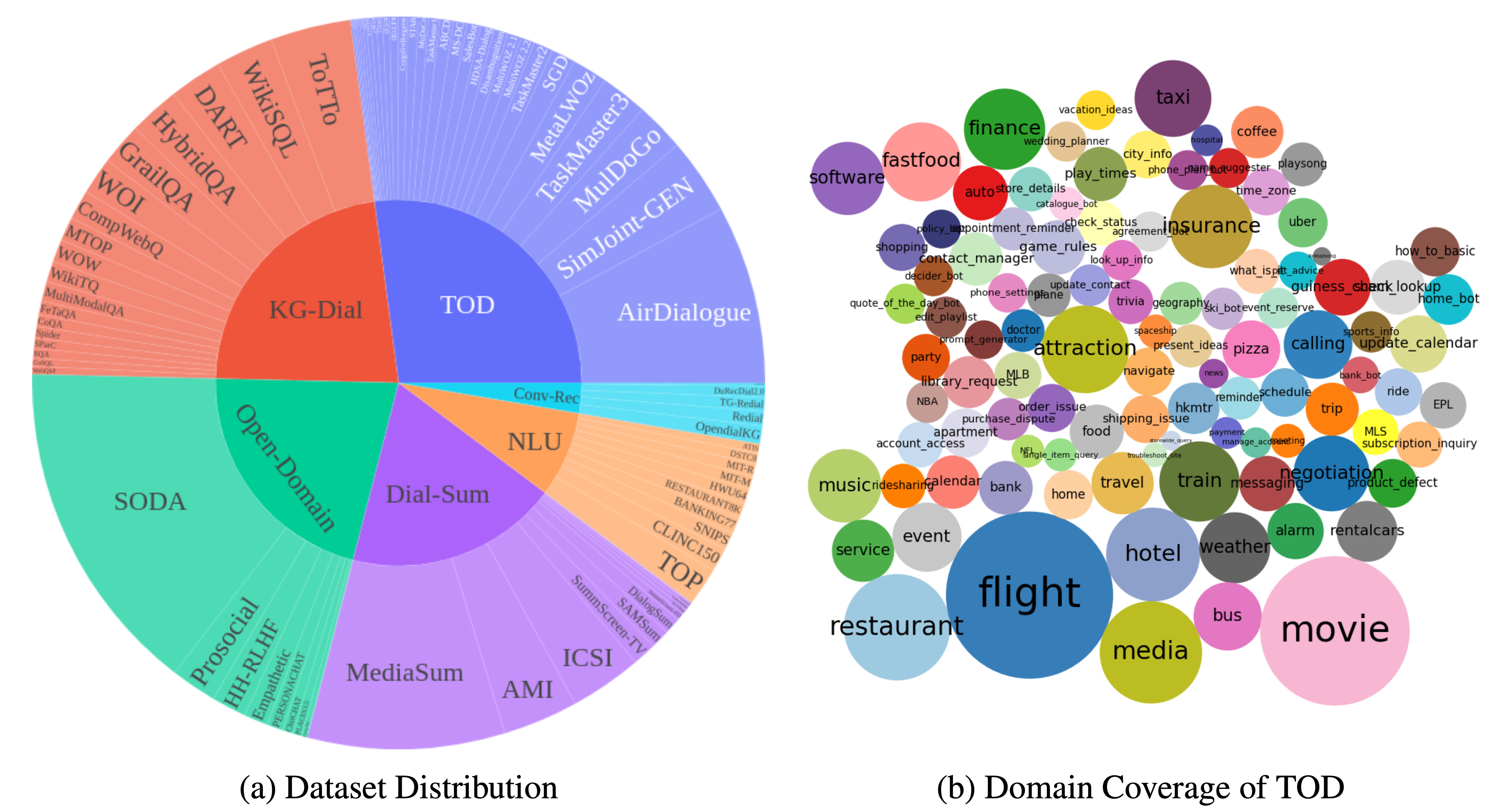
DialogStudio adalah kumpulan besar dan kumpulan data dialog terpadu. Gambar di bawah ini memberikan ringkasan statistik umum yang terkait dengan DialogStudio . DialogStudio menyatukan setiap kumpulan data sambil mempertahankan informasi aslinya, dan hal ini membantu mendukung penelitian pada kumpulan data individual dan pelatihan Model Bahasa Besar (LLM). Daftar lengkap semua kumpulan data yang tersedia ada di sini.
Data dapat diunduh melalui Huggingface seperti yang diperkenalkan di Memuat Data. Kami juga memberikan contoh untuk setiap dataset di repo ini. Untuk rincian yang lebih terperinci dan spesifik kategori, silakan merujuk ke folder individual yang sesuai dengan setiap kategori dalam koleksi DialogStudio , misalnya kumpulan data MULTIWOZ2_2 di bawah kategori dialog berorientasi tugas.
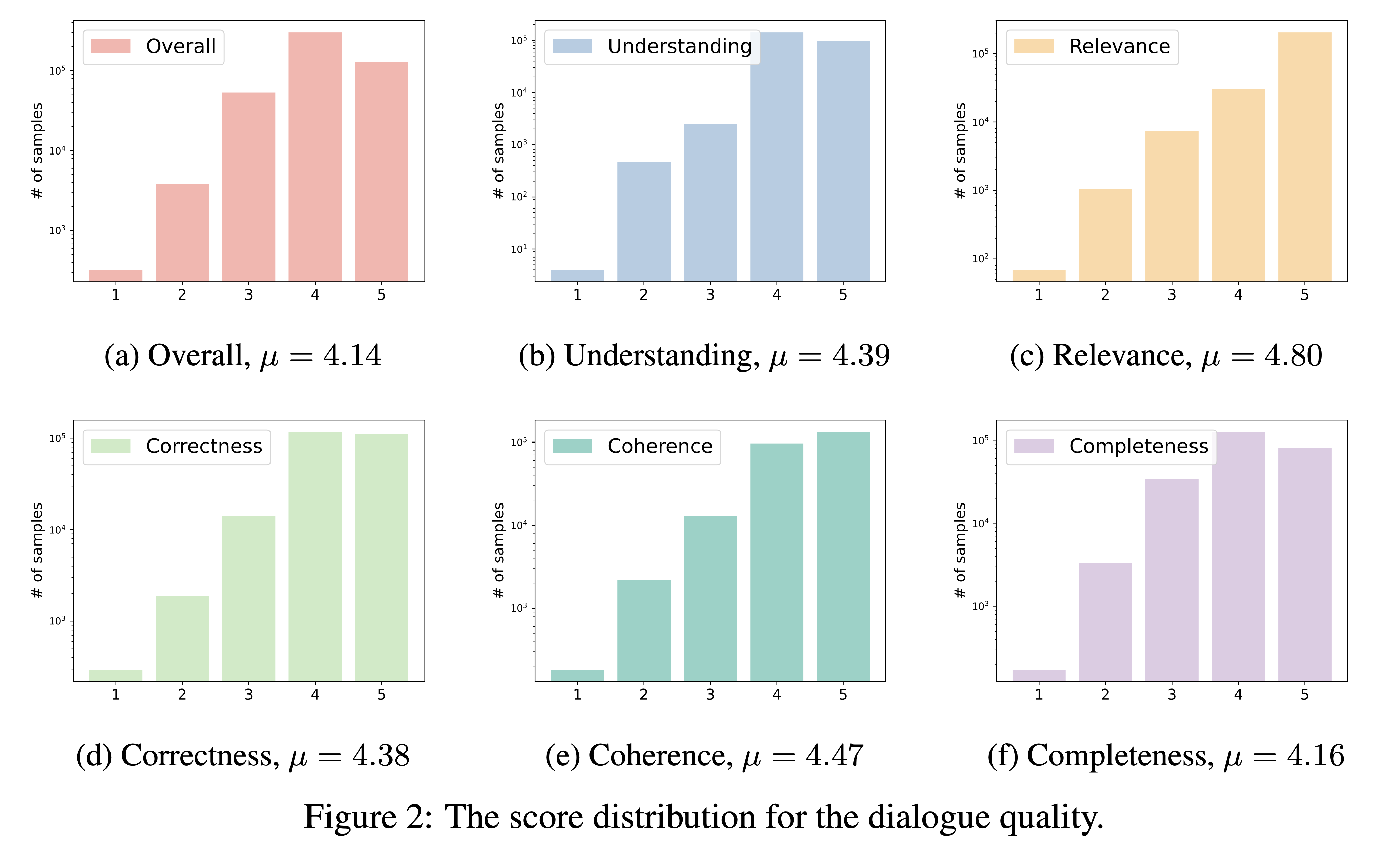
DialogStudio mengevaluasi kualitas dialog berdasarkan enam kriteria penting, yaitu Pemahaman, Relevansi, Kebenaran, Koherensi, Kelengkapan, dan Kualitas Keseluruhan. Setiap kriteria diberi skor pada skala 1 hingga 5, dengan skor tertinggi diperuntukkan bagi dialog yang luar biasa.
Mengingat banyaknya kumpulan data yang dimasukkan ke dalam DialogStudio , kami menggunakan 'gpt-3.5-turbo' untuk menilai 33 kumpulan data berbeda. Skrip terkait yang digunakan untuk evaluasi ini dapat diakses melalui tautan.
Hasil penilaian kualitas dialog kami disajikan di bawah ini. Kami bermaksud untuk merilis skor evaluasi untuk dialog yang dipilih secara individual pada periode mendatang.
Anda dapat memuat kumpulan data apa pun di DialogStudio dari hub HuggingFace dengan mengklaim {dataset_name} , yang merupakan nama folder kumpulan data. Semua kumpulan data yang tersedia dijelaskan dalam konten kumpulan data.
Di bawah ini adalah salah satu contoh untuk memuat kumpulan data MULTIWOZ2_2 dalam kategori dialog berorientasi tugas:
Muat kumpulan data
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )Berikut adalah struktur keluaran MultiWOZ 2.2
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})Kumpulan data dibagi menjadi beberapa kategori di repositori GitHub dan hub HuggingFace ini. Anda dapat memeriksa tabel kumpulan data untuk informasi lebih lanjut. Dan Anda dapat mengklik setiap folder untuk memeriksa beberapa contoh:
Kami telah meluncurkan model versi 1.0 ( DialogStudio -t5-base-v1.0, DialogStudio -t5-large-v1.0, DialogStudio -t5-3b-v1.0) yang dilatih pada beberapa kumpulan data DialogStudio yang dipilih. Periksa setiap Kartu Model untuk lebih jelasnya.
Di bawah ini adalah salah satu contoh untuk menjalankan model pada CPU:
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Proyek kami mengikuti struktur berikut sehubungan dengan perizinan:
Untuk informasi lisensi terperinci, lihat lisensi spesifik yang disertakan dengan kumpulan data asli. Penting untuk memahami ketentuan ini karena kami tidak bertanggung jawab atas masalah perizinan.
Kami dengan tulus berterima kasih kepada semua penulis kumpulan data yang telah berkontribusi pada bidang AI Percakapan. Meskipun telah dilakukan upaya yang hati-hati, ketidakakuratan dalam kutipan atau referensi kami mungkin saja terjadi. Jika Anda menemukan kesalahan atau kekurangan, silakan ajukan masalah atau kirimkan permintaan penarikan untuk membantu kami meningkatkannya. Terima kasih!
Data dan kode dalam repositori ini sebagian besar dikembangkan atau diturunkan dari makalah di bawah ini. Jika Anda menggunakan kumpulan data dari DialogStudio , kami dengan hormat meminta Anda mengutip karya asli dan karya kami sendiri (Diterima oleh Temuan EACL 2024 sebagai makalah panjang).
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
Kami dengan antusias mengundang kontribusi dari komunitas! Bergabunglah bersama kami dalam misi bersama untuk memajukan bidang AI percakapan!


