aug pe
1.0.0
? Makalah • Data (Yelp/OpenReview/PubMed) • Halaman Proyek
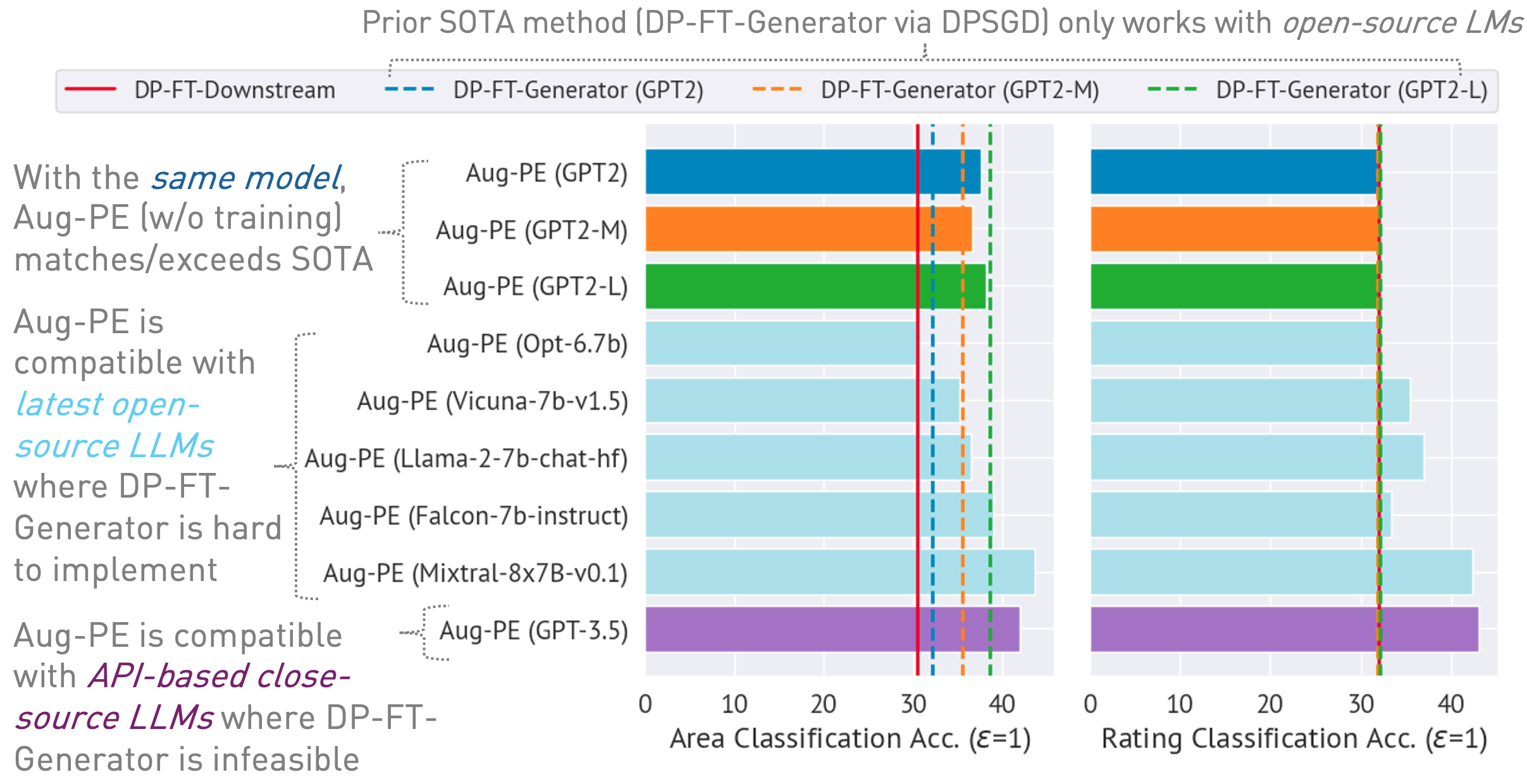
Repositori ini mengimplementasikan algoritme Augmented Private Evolution (Aug-PE), yang memanfaatkan akses API inferensi ke model bahasa besar (LLM) untuk menghasilkan teks sintetik pribadi diferensial (DP) tanpa memerlukan pelatihan model. Kami membandingkan finetuning DP-SGD dan Aug-PE:

Di bawah
03/13/2024 : Halaman proyek tersedia, yang menguraikan algoritma dan hasilnya.03/11/2024 : Kode dan kertas ArXiv tersedia. conda env create -f environment.yml
conda activate augpe
Kumpulan data terletak di data/{dataset} dengan dataset yelp , openreview dan pubmed .
Unduh Yelp train.csv (1.21G) dan PubMed train.csv (117MB) dari tautan ini atau jalankan:
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvDeskripsi kumpulan data:
Penyematan pra-komputasi untuk data pribadi (baris 1 dalam algoritma Aug-PE):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp Catatan: Menghitung penyematan untuk OpenReview dan PubMed relatif cepat. Namun, karena ukuran kumpulan data Yelp yang besar (1,9 juta sampel pelatihan), prosesnya mungkin memerlukan waktu sekitar 40 menit.
Hitung tingkat kebisingan DP untuk kumpulan data Anda di notebook/dp_budget.ipynb dengan mempertimbangkan anggaran privasi
Untuk visualisasi dengan Wandb, konfigurasikan --wandb_key dan --project dengan kunci dan nama proyek Anda di dpsda/arg_utils.py .
Manfaatkan LLM sumber terbuka dari Hugging Face untuk menghasilkan data sintetis:
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedBeberapa hyperparameter utama:
noise : kebisingan DP.epoch : kami menggunakan 10 epoch untuk pengaturan DP. Untuk pengaturan non-DP, kami menggunakan 20 epoch untuk Yelp dan 10 epoch untuk dataset lainnya.model_type : model pada wajah berpelukan, seperti ["gpt2", "gpt2-medium", "gpt2-large", "meta-llama/Llama-2-7b-chat-hf", "tiiuae/falcon-7b-instruct" , "facebook/opt-6.7b", "lmsys/vicuna-7b-v1.5", "mistralai/Mixtral-8x7B-Instruksi-v0.1"].num_seed_samples : jumlah sampel sintetis.lookahead_degree : jumlah variasi untuk estimasi penyematan sampel sintetik (baris 5 dalam algoritma Aug-PE). Standarnya adalah 0 (penyematan mandiri).L : terkait dengan jumlah variasi untuk menghasilkan calon sampel sintetik (baris 18 pada algoritma Aug-PE)feat_ext : menyematkan model pada pengubah kalimat wajah berpelukan.select_syn_mode : memilih sampel sintetis berdasarkan suara histogram atau probabilitas. Defaultnya adalah rank (baris 19 dalam algoritma Agustus-PE)temperature : suhu untuk pembangkitan LLM.Sempurnakan model hilir dengan teks sintetis DP dan evaluasi keakuratan model pada data pengujian nyata:
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance Ukur jarak distribusi penyematan:
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distanceUntuk proses yang disederhanakan yang menggabungkan semua langkah pembuatan dan evaluasi:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset Kami menggunakan model sumber tertutup melalui Azure OpenAI API. Harap atur kunci dan titik akhir Anda di apis/azure_api.py
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} Di sini engine bisa berupa gpt-35-turbo di Azure.
Jalankan skrip berikut untuk menghasilkan data sintetis, evaluasi pada tugas hilir, dan hitung jarak distribusi penyematan antara data nyata dan sintetis:
bash scripts/gpt-3.5-turbo/{dataset}.shKami menggunakan perintah terkait panjang teks untuk GPT-3.5 guna mengontrol panjang teks yang dihasilkan. Kami memperkenalkan beberapa hyperparameter tambahan di sini:
dynamic_len digunakan untuk mengaktifkan mekanisme panjang dinamis.word_var_scale : Varians noise Gaussian digunakan untuk menentukan target_word.max_token_word_scale : jumlah token maksimal per kata. Kami menetapkan max_token untuk pembuatan LLM berdasarkan target_word (ditentukan dalam prompt) dan max_token_word_scale. Gunakan notebook untuk menghitung perbedaan distribusi panjang teks antara data nyata dan sintetis: notebook/text_lens_distribution.ipynb
Jika Anda merasa pekerjaan kami bermanfaat, mohon pertimbangkan untuk mengutipnya sebagai berikut:
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}Jika Anda memiliki pertanyaan terkait kode atau makalah, silakan kirim email ke Chulin ([email protected]) atau buka terbitan.


