Study Bot
1.0.0
Study-Bot adalah proyek sumber terbuka yang dikembangkan oleh Edumakers dari Tecnológico de Monterrey . Hal ini dirancang untuk membantu siswa tunanetra meninjau materi pelajaran akademik mereka. Ini adalah pendamping belajar bertenaga AI yang menggabungkan berbagai teknologi, termasuk Whisper, GPT-3.5-turbo-16k, Elevenlabs text-to-speech, dan OpenCV. Untuk tujuan pengujian, contoh materi kursus dihasilkan menggunakan ChatGPT.
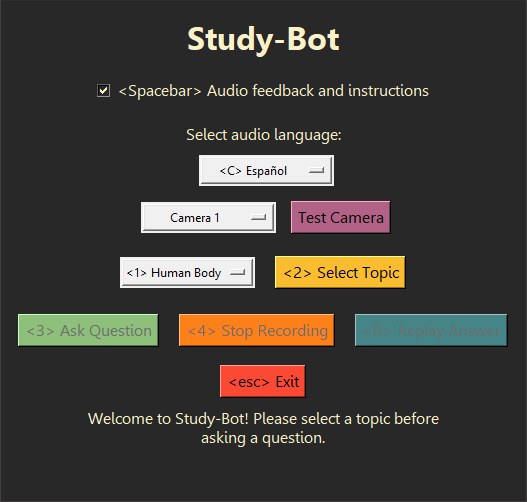
Study-Bot dapat: mendengarkan pertanyaan pengguna, menganalisis materi sumber dari topik yang ingin mereka pelajari, mendeteksi materi pendidikan jasmani yang mereka pegang berdasarkan warna atau penanda ArUco, menghasilkan jawaban, dan membacakannya dengan lantang kepada pengguna. pengguna sebagai aplikasi yang dapat dieksekusi yang dapat diakses. Untuk tujuan pengembangan dan pengujian, dapat dijalankan melalui interpreter Python sebagai program CLI atau dengan GUI .
Beberapa langkah baik selanjutnya adalah menanamkan sistem ini ke dalam antarmuka pengguna yang lebih canggih untuk didistribusikan sebagai aplikasi desktop, membuat model visi komputer yang dapat mendeteksi materi pendidikan jasmani tanpa bergantung pada warna atau penanda ArUco, serta beberapa peningkatan kinerja dan fitur interaktif baru.
Disarankan untuk menggunakan Python 3.9.9 agar pustaka whisper dapat digunakan tanpa masalah. Untuk menghindari keharusan menghapus instalasi Python Anda saat ini, Anda mungkin ingin menggunakan lingkungan virtual untuk menggunakan versi khusus Python ini. Untuk menginstal dependensi yang diperlukan, jalankan perintah berikut:
pip install -r requirements.txt Ada beberapa langkah tambahan yang perlu diambil sebelum dapat menjalankan proyek, seperti perolehan kunci API Anda sendiri untuk layanan AI yang digunakan di sini. Untuk informasi lebih lanjut, silakan merujuk ke folder Documentation untuk panduan komprehensif tentang cara menggunakan proyek ini.
Study-Bot mengandalkan layanan dan teknologi yang ada berikut ini:
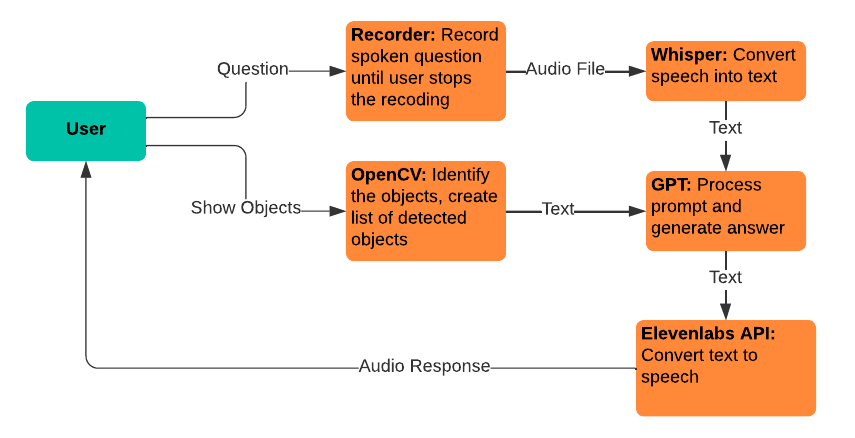
Whisper: Digunakan untuk konversi ucapan ke teks, memungkinkan pengguna menyampaikan pertanyaan mereka untuk dimasukkan ke dalam model GPT.
gpt-3.5-turbo-16k: Digunakan untuk pemrosesan pertanyaan dan pembuatan jawaban. Model versi 16k dipilih karena ukuran jendela konteksnya yang berjumlah 16.385 token, yang diperlukan untuk memproses materi sumber dalam jumlah besar.
Elevenlabs text-to-speech: Digunakan untuk konversi text-to-speech, memungkinkan pengguna mendengar jawaban yang dihasilkan oleh model GPT.
OpenCV: Digunakan untuk identifikasi objek fisik, untuk membantu model GPT-3.5-16k dalam menjawab pertanyaan dengan konteks tambahan tentang apa yang dipegang pengguna.
Gunakan proyek ini sebagai referensi untuk proyek Anda sendiri, atau gunakan proyek ini untuk memberikan kontribusi Anda sendiri. Masalah GitHub mengenai permintaan fitur dan laporan bug diterima dan dihargai secara khusus jika mencakup masukan dari pengguna tunanetra.


