reflexion
1.0.0
Repo ini menyimpan kode, demo, dan file log untuk reflexion : Agen Bahasa dengan Pembelajaran Penguatan Verbal oleh Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao.
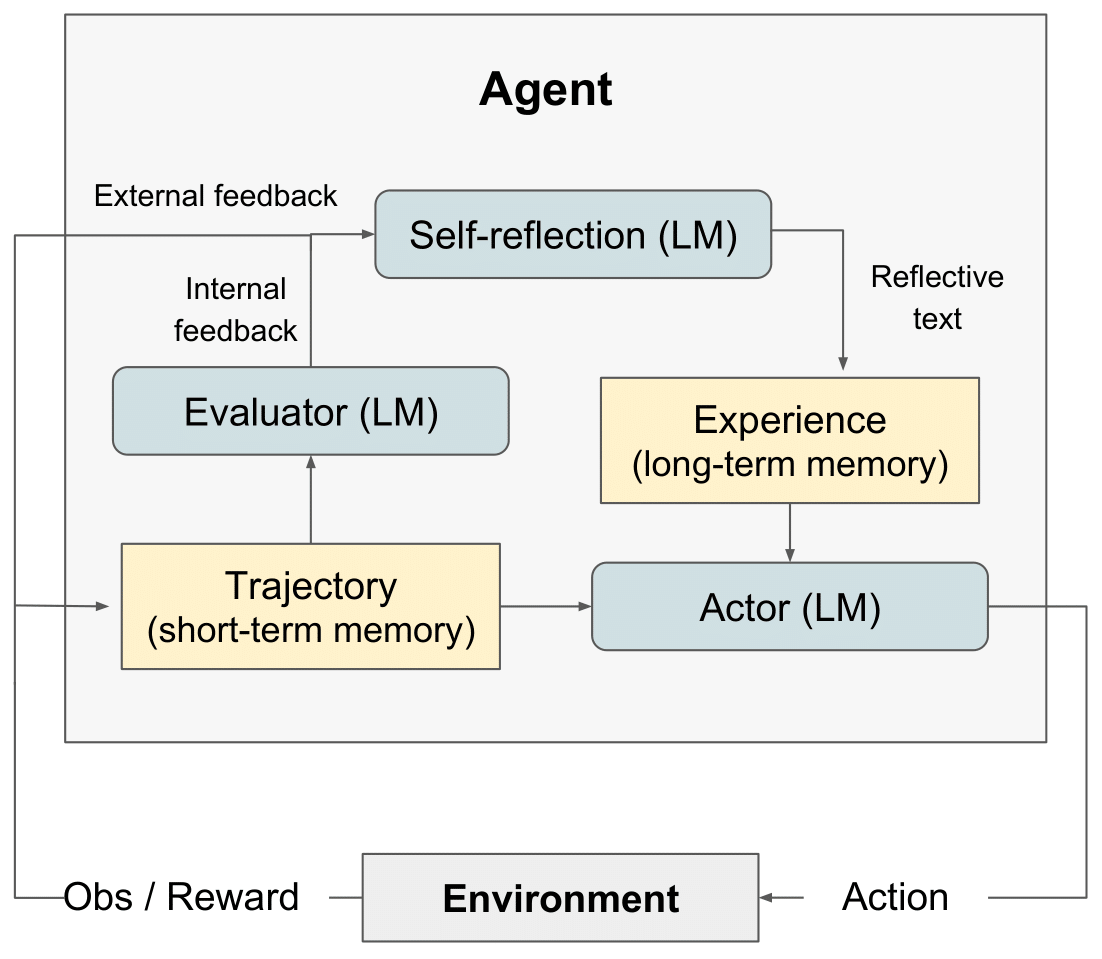 diagram refleksi RL" style="max-width: 100%;">
diagram refleksi RL" style="max-width: 100%;">
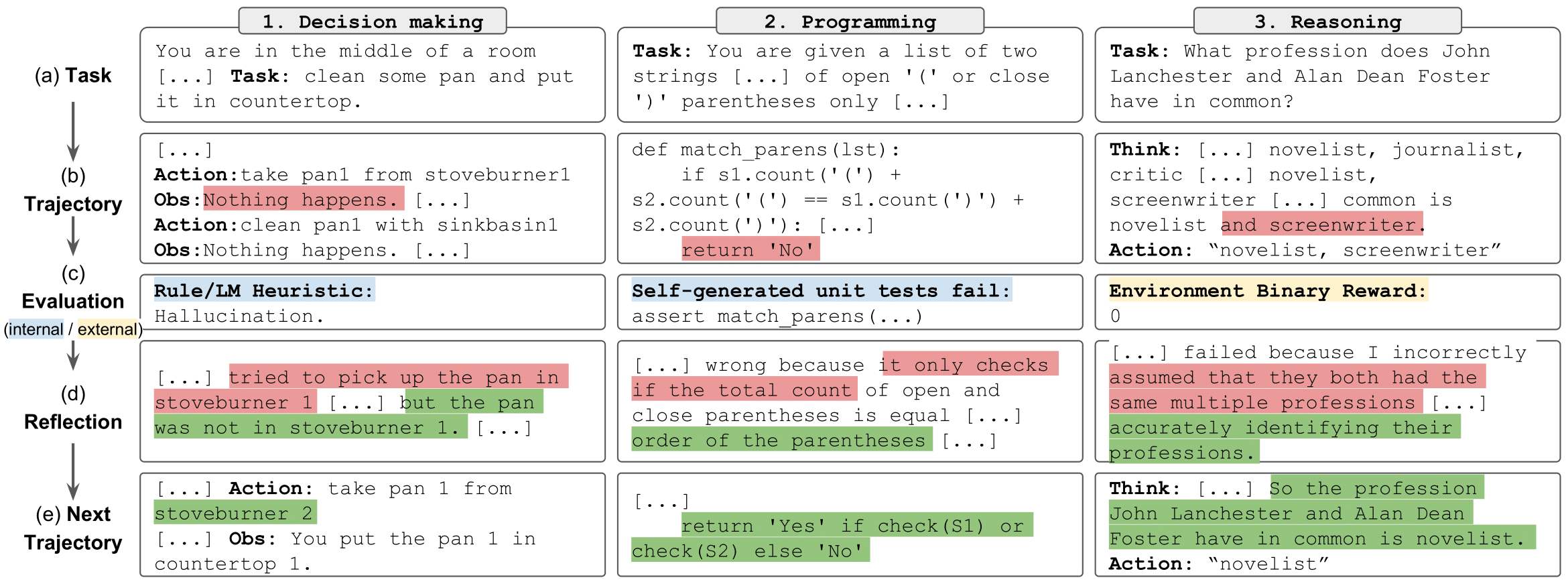 tugas refleksi" style="max-width: 100%;">
tugas refleksi" style="max-width: 100%;">
Kami telah merilis LeetcodeHardGym di sini
Kami telah menyediakan satu set buku catatan untuk dengan mudah menjalankan, mengeksplorasi, dan berinteraksi dengan hasil eksperimen penalaran. Setiap percobaan terdiri dari sampel acak yang terdiri dari 100 pertanyaan dari kumpulan data pengecoh HotPotQA. Setiap pertanyaan dalam sampel dicoba oleh agen dengan tipe dan strategi reflexion tertentu.
Untuk memulai:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY ke kunci API OpenAI Anda: export OPENAI_API_KEY= < your key > Jenis agen ditentukan oleh buku catatan yang Anda pilih untuk dijalankan. Jenis agen yang tersedia antara lain:
ReAct - Agen Bereaksi
CoT_context - Agen CoT diberikan konteks pendukung tentang pertanyaan tersebut
CoT_no_context - Agen CoT tidak diberikan konteks pendukung tentang pertanyaan tersebut
Notebook untuk setiap jenis agen terletak di direktori ./hotpot_runs/notebooks .
Setiap buku catatan memungkinkan Anda menentukan strategi reflexion yang akan digunakan oleh agen. Strategi reflexion yang tersedia, yang didefinisikan dalam Enum , meliputi:
reflexion Strategy.NONE - Agen tidak diberikan informasi apa pun tentang upaya terakhirnya.
reflexion Strategy.LAST_ATTEMPT - Agen diberikan jejak alasannya dari upaya terakhirnya pada pertanyaan sebagai konteks.
reflexion Strategy. reflexion - Agen diberikan refleksi dirinya pada upaya terakhir sebagai konteks.
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - Agen diberikan jejak penalaran dan refleksi diri pada upaya terakhir sebagai konteks.
Kloning repo ini dan pindah ke direktori AlfWorld
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs Tentukan parameter proses di ./run_ reflexion .sh . num_trials : jumlah langkah pembelajaran berulang num_envs : jumlah pasangan tugas-lingkungan per uji coba run_name : nama untuk proses ini use_memory : menggunakan memori yang ada untuk menyimpan refleksi diri (matikan untuk menjalankan proses dasar) is_resume : menggunakan direktori logging untuk melanjutkan proses sebelumnya resume_dir : direktori logging untuk melanjutkan proses sebelumnya start_trial_num : jika resume dijalankan, maka nomor percobaan yang akan dimulai
Jalankan uji coba
./run_ reflexion .sh Log akan dikirim ke ./root/<run_name> .
Karena sifat eksperimen ini, masing-masing developer mungkin tidak dapat menjalankan kembali hasilnya karena GPT-4 memiliki akses terbatas dan biaya API yang signifikan. Semua proses dari makalah dan hasil tambahan dicatat di ./alfworld_runs/root untuk pengambilan keputusan, ./hotpotqa_runs/root untuk alasan, dan ./programming_runs/root untuk pemrograman
Lihat kode untuk kode aslinya di sini
Baca posting blog di sini
Lihat implementasi prediksi tipe yang menarik di sini: OpenTau
Untuk semua pertanyaan, hubungi [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

