Proyek Retrieval-Augmented Generation (RAG).
If this project helps you, consider buying me a coffee ☕. Your support helps me keep contributing to the open-source community!
Platform resmi bRAGAI akan segera diluncurkan. Bergabunglah dalam daftar tunggu untuk menjadi salah satu pengguna awal!
Repositori ini berisi eksplorasi komprehensif Retrieval-Augmented Generation (RAG) untuk berbagai aplikasi. Setiap notebook memberikan panduan praktis dan mendetail untuk menyiapkan dan bereksperimen dengan RAG mulai dari tingkat pengantar hingga implementasi lanjutan, termasuk multi-kueri dan pembuatan RAG khusus.
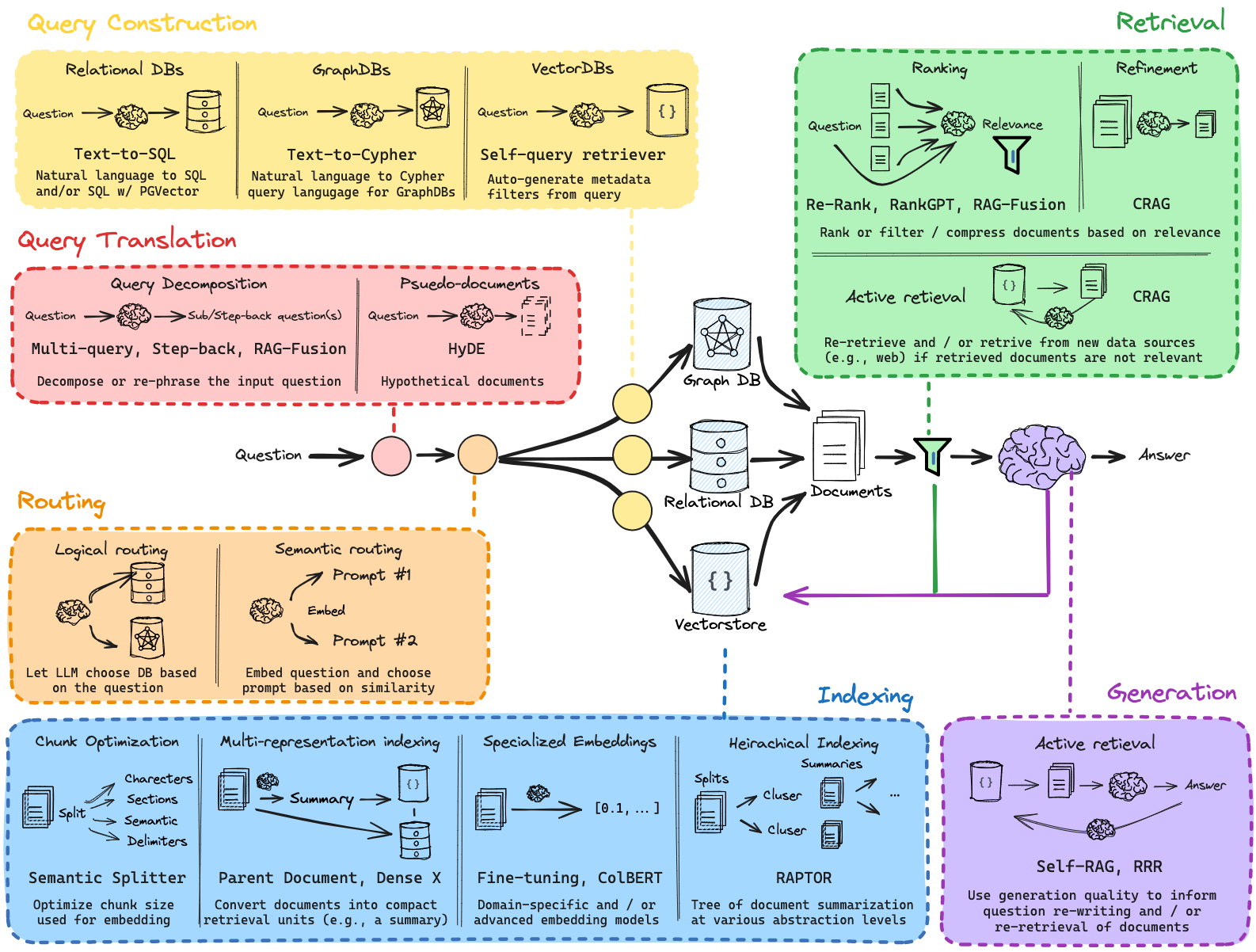
Struktur Proyek
Jika Anda ingin langsung membahasnya, periksa file full_basic_rag.ipynb -> file ini akan memberi Anda kode starter boilerplate dari chatbot RAG yang sepenuhnya dapat disesuaikan.
Pastikan untuk menjalankan file Anda di lingkungan virtual (bagian checkout Get Started )
Buku catatan berikut dapat ditemukan di direktori tutorial_notebooks/ .
[1]_rag_setup_ikhtisar.ipynb
Notebook pengantar ini memberikan gambaran umum tentang arsitektur RAG dan pengaturan dasarnya. Buku catatan itu menelusuri:
- Pengaturan Lingkungan : Mengonfigurasi lingkungan, menginstal perpustakaan yang diperlukan, dan pengaturan API.
- Pemuatan Data Awal : Pemuat dokumen dasar dan metode prapemrosesan data.
- Embedding Generation : Menghasilkan embeddings menggunakan berbagai model, termasuk embeddings OpenAI.
- Vector Store : Menyiapkan penyimpanan vektor (ChromaDB/Pinecone) untuk pencarian kesamaan yang efisien.
- Pipa RAG Dasar : Membuat pipa pengambilan dan pembuatan sederhana untuk dijadikan sebagai garis dasar.
[2]_rag_with_multi_query.ipynb
Berdasarkan dasar-dasarnya, notebook ini memperkenalkan teknik multi-kueri dalam pipeline RAG, mengeksplorasi:
- Pengaturan Multi-Kueri : Mengonfigurasi beberapa kueri untuk mendiversifikasi pengambilan.
- Teknik Penyematan Tingkat Lanjut : Memanfaatkan beberapa model penyematan untuk menyempurnakan pengambilan.
- Pipeline dengan Multi-Querying : Menerapkan penanganan multi-kueri untuk meningkatkan relevansi dalam menghasilkan respons.
- Perbandingan & Analisis : Membandingkan hasil dengan saluran kueri tunggal dan menganalisis peningkatan kinerja.
[3]_rag_routing_and_query_construction.ipynb
Notebook ini mempelajari lebih dalam tentang penyesuaian pipeline RAG. Ini mencakup:
- Perutean Logis: Menerapkan perutean berbasis fungsi untuk mengklasifikasikan kueri pengguna ke sumber data yang sesuai berdasarkan bahasa pemrograman.
- Perutean Semantik: Menggunakan penyematan dan kesamaan kosinus untuk mengarahkan pertanyaan ke perintah matematika atau fisika, sehingga mengoptimalkan akurasi respons.
- Penataan Kueri untuk Filter Metadata: Mendefinisikan skema pencarian terstruktur untuk metadata tutorial YouTube, memungkinkan pemfilteran lanjutan (misalnya, berdasarkan jumlah penayangan, tanggal publikasi).
- Permintaan Pencarian Terstruktur: Memanfaatkan permintaan LLM untuk menghasilkan kueri basis data untuk mengambil konten yang relevan berdasarkan masukan pengguna.
- Integrasi dengan Penyimpanan Vektor: Menghubungkan kueri terstruktur ke penyimpanan vektor untuk pengambilan data yang efisien.
[4]_rag_indexing_and_advanced_retrieval.ipynb
Melanjutkan penyesuaian sebelumnya, notebook ini mengeksplorasi:
- Kata Pengantar tentang Pemotongan Dokumen: Menunjukkan sumber daya eksternal untuk teknik pemotongan dokumen.
- Pengindeksan Multi-representasi: Menyiapkan struktur pengindeksan multi-vektor untuk menangani dokumen dengan penyematan dan representasi berbeda.
- Penyimpanan Dalam Memori untuk Ringkasan: Menggunakan InMemoryByteStore untuk menyimpan ringkasan dokumen bersama dokumen induk, memungkinkan pengambilan yang efisien.
- Pengaturan MultiVectorRetriever: Mengintegrasikan beberapa representasi vektor untuk mengambil dokumen yang relevan berdasarkan permintaan pengguna.
- Implementasi RAPTOR: Menjelajahi RAPTOR, model pengindeksan dan pengambilan tingkat lanjut, yang terhubung ke sumber daya yang mendalam.
- Integrasi ColBERT: Mendemonstrasikan pengindeksan dan pengambilan vektor tingkat token berbasis ColBERT, yang menangkap makna kontekstual pada tingkat yang sangat rinci.
- Contoh Wikipedia dengan ColBERT: Mengambil informasi tentang Hayao Miyazaki menggunakan model pengambilan ColBERT untuk demonstrasi.
[5]_rag_retrieval_and_reranking.ipynb
Notebook terakhir ini menyatukan komponen sistem RAG, dengan fokus pada skalabilitas dan optimalisasi:
- Pemuatan dan Pemisahan Dokumen: Memuat dan mengelompokkan dokumen untuk pengindeksan, mempersiapkannya untuk penyimpanan vektor.
- Pembuatan Multi-kueri dengan RAG-Fusion: Menggunakan pendekatan berbasis cepat untuk menghasilkan beberapa kueri penelusuran dari satu pertanyaan masukan.
- Reciprocal Rank Fusion (RRF): Menerapkan RRF untuk memeringkat ulang beberapa daftar pengambilan, menggabungkan hasil untuk meningkatkan relevansi.
- Penyiapan Rantai Retriever dan RAG: Membangun rantai pengambilan untuk menjawab pertanyaan, menggunakan peringkat gabungan dan rantai RAG untuk menarik informasi yang relevan secara kontekstual.
- Pemeringkatan Ulang Cohere: Mendemonstrasikan pemeringkatan ulang dengan model Cohere untuk kompresi dan penyempurnaan kontekstual tambahan.
- CRAG dan Self-RAG Retrieval: Menjelajahi pendekatan pengambilan tingkat lanjut seperti CRAG dan Self-RAG, dengan tautan ke contoh.
- Eksplorasi Dampak Konteks Panjang: Tautan ke sumber daya yang menjelaskan dampak pengambilan konteks panjang pada model RAG.
Memulai
Prasyarat: Python 3.11.7 (lebih disukai)
Kloning repositori :
git clone https://github.com/bRAGAI/bRAG-langchain.git
cd bRAG-langchain
Ciptakan lingkungan virtual
python -m venv venv
source venv/bin/activate
Instal dependensi : Pastikan untuk menginstal paket yang diperlukan yang tercantum di requirements.txt .
pip install -r requirements.txt
Jalankan Notebook : Mulailah dengan [1]_rag_setup_overview.ipynb untuk memahami proses pengaturan. Lanjutkan secara berurutan melalui buku catatan lain untuk membuat dan bereksperimen dengan konsep RAG yang lebih canggih.
Atur Variabel Lingkungan :
Urutan Notebook : Untuk mengikuti proyek secara terstruktur:
Mulailah dengan [1]_rag_setup_overview.ipynb
Lanjutkan dengan [2]_rag_with_multi_query.ipynb
Lalu buka [3]_rag_routing_and_query_construction.ipynb
Lanjutkan dengan [4]_rag_indexing_and_advanced_retrieval.ipynb
Selesaikan dengan [5]_rag_retrieval_and_reranking.ipynb
Penggunaan
Setelah menyiapkan lingkungan dan menjalankan buku catatan secara berurutan, Anda dapat:
Bereksperimenlah dengan Retrieval-Augmented Generation : Gunakan pengaturan dasar di [1]_rag_setup_overview.ipynb untuk memahami dasar-dasar RAG.
Menerapkan Multi-Kueri : Pelajari cara meningkatkan relevansi respons dengan memperkenalkan teknik multi-kueri di [2]_rag_with_multi_query.ipynb .
Buku Catatan Masuk (sedang dalam proses)
- Konteks Presisi dengan RAGAS + LangSmith
- Panduan penggunaan RAGAS dan LangSmith untuk mengevaluasi presisi konteks, relevansi, dan akurasi respons di RAG.
- Menerapkan aplikasi RAG
- Panduan tentang cara menyebarkan aplikasi RAG Anda
The notebooks and visual diagrams were inspired by Lance Martin's LangChain Tutorial.


