segment anything
1.0.0
Silakan lihat rilis baru kami di Segment Anything Model 2 (SAM 2) .
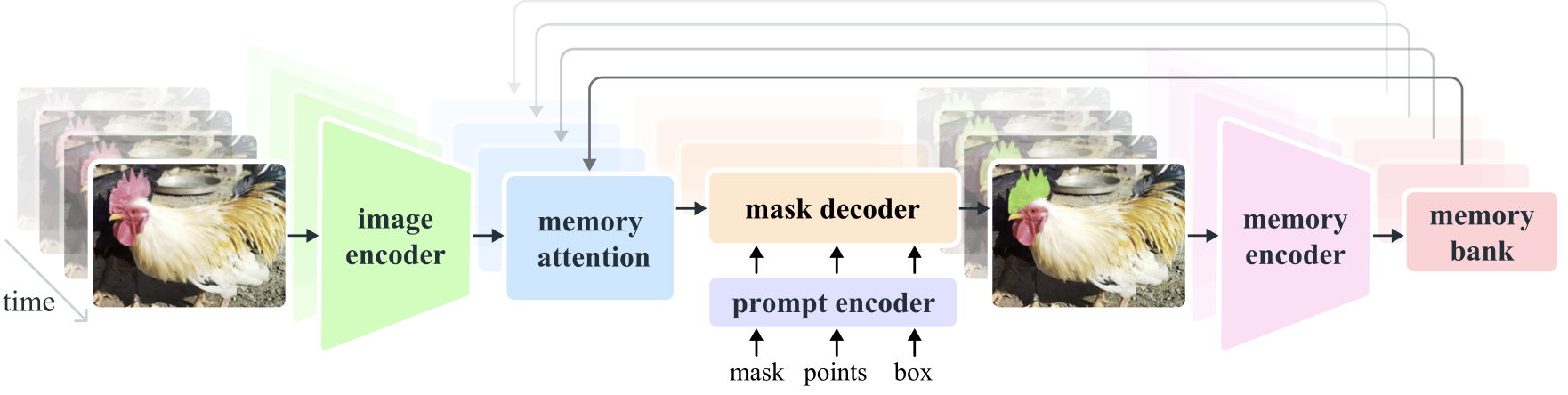
Segment Anything Model 2 (SAM 2) adalah model dasar untuk memecahkan segmentasi visual yang cepat dalam gambar dan video. Kami memperluas SAM ke video dengan menganggap gambar sebagai video dengan satu frame. Desain modelnya adalah arsitektur transformator sederhana dengan memori streaming untuk pemrosesan video waktu nyata. Kami membangun mesin data model-in-the-loop, yang meningkatkan model dan data melalui interaksi pengguna, untuk mengumpulkan kumpulan data SA-V kami , kumpulan data segmentasi video terbesar hingga saat ini. SAM 2 yang dilatih berdasarkan data kami memberikan kinerja yang kuat di berbagai tugas dan domain visual.
Penelitian Meta AI, ADIL
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
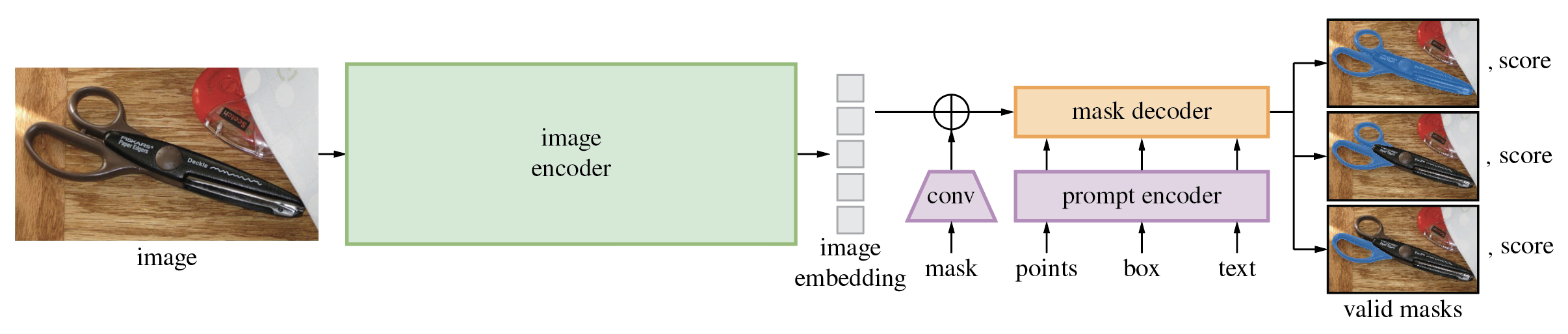
Segment Anything Model (SAM) menghasilkan masker objek berkualitas tinggi dari perintah masukan seperti titik atau kotak, dan dapat digunakan untuk menghasilkan masker untuk semua objek dalam gambar. Ini telah dilatih pada kumpulan data 11 juta gambar dan 1,1 miliar masker, dan memiliki kinerja zero-shot yang kuat pada berbagai tugas segmentasi.


Kode ini memerlukan python>=3.8 , serta pytorch>=1.7 dan torchvision>=0.8 . Silakan ikuti petunjuk di sini untuk menginstal dependensi PyTorch dan TorchVision. Menginstal PyTorch dan TorchVision dengan dukungan CUDA sangat disarankan.
Instal Segmen Apa Saja:
pip install git+https://github.com/facebookresearch/segment-anything.git
atau mengkloning repositori secara lokal dan menginstal dengan
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
Dependensi opsional berikut diperlukan untuk pasca-pemrosesan mask, menyimpan masker dalam format COCO, contoh notebook, dan mengekspor model dalam format ONNX. jupyter juga diperlukan untuk menjalankan contoh notebook.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
Pertama unduh model pos pemeriksaan. Kemudian model tersebut dapat digunakan hanya dalam beberapa baris untuk mendapatkan mask dari prompt tertentu:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
atau buat topeng untuk keseluruhan gambar:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
Selain itu, masker dapat dibuat untuk gambar dari baris perintah:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
Lihat contoh buku catatan tentang penggunaan SAM dengan petunjuk dan pembuatan masker secara otomatis untuk detail selengkapnya.


Decoder masker ringan SAM dapat diekspor ke format ONNX sehingga dapat dijalankan di lingkungan apa pun yang mendukung runtime ONNX, seperti dalam browser seperti yang dipamerkan dalam demo. Ekspor model dengan
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
Lihat contoh notebook untuk detail tentang cara menggabungkan prapemrosesan gambar melalui backbone SAM dengan prediksi mask menggunakan model ONNX. Disarankan untuk menggunakan PyTorch versi stabil terbaru untuk ekspor ONNX.
Folder demo/ memiliki aplikasi React satu halaman sederhana yang menunjukkan cara menjalankan prediksi mask dengan model ONNX yang diekspor di browser web dengan multithreading. Silakan lihat demo/README.md untuk lebih jelasnya.
Tiga versi model model tersedia dengan ukuran tulang punggung berbeda. Model-model ini dapat dipakai dengan menjalankan
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
Klik tautan di bawah untuk mengunduh pos pemeriksaan untuk jenis model yang sesuai.
default atau vit_h : model ViT-H SAM.vit_l : Model ViT-L SAM.vit_b : Model SAM ViT-B. Lihat di sini untuk ikhtisar dataset. Datasetnya dapat diunduh di sini. Dengan mengunduh kumpulan data, Anda setuju bahwa Anda telah membaca dan menerima ketentuan Lisensi Penelitian Kumpulan Data SA-1B.
Kami menyimpan masker per gambar sebagai file json. Itu dapat dimuat sebagai kamus dengan python dalam format di bawah ini.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}ID gambar dapat ditemukan di sa_images_ids.txt yang juga dapat diunduh menggunakan tautan di atas.
Untuk memecahkan kode topeng dalam format COCO RLE ke dalam biner:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
Lihat di sini untuk instruksi lebih lanjut untuk memanipulasi masker yang disimpan dalam format RLE.
Model ini dilisensikan di bawah lisensi Apache 2.0.
Lihat berkontribusi dan kode etik.
Proyek Segmen Apa Pun dimungkinkan dengan bantuan banyak kontributor (berdasarkan abjad):
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, Mallika Malhotra, William Ngan, Omkar Parkhi, Nikhil Raina, Dirk Rowe, Neil Sejoor, Vanessa Stark, Bala Varadarajan, Bram Wasti, Zachary Winstrom
Jika Anda menggunakan SAM atau SA-1B dalam penelitian Anda, silakan gunakan entri BibTeX berikut.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


