obfuscated gradients
v1.0.0
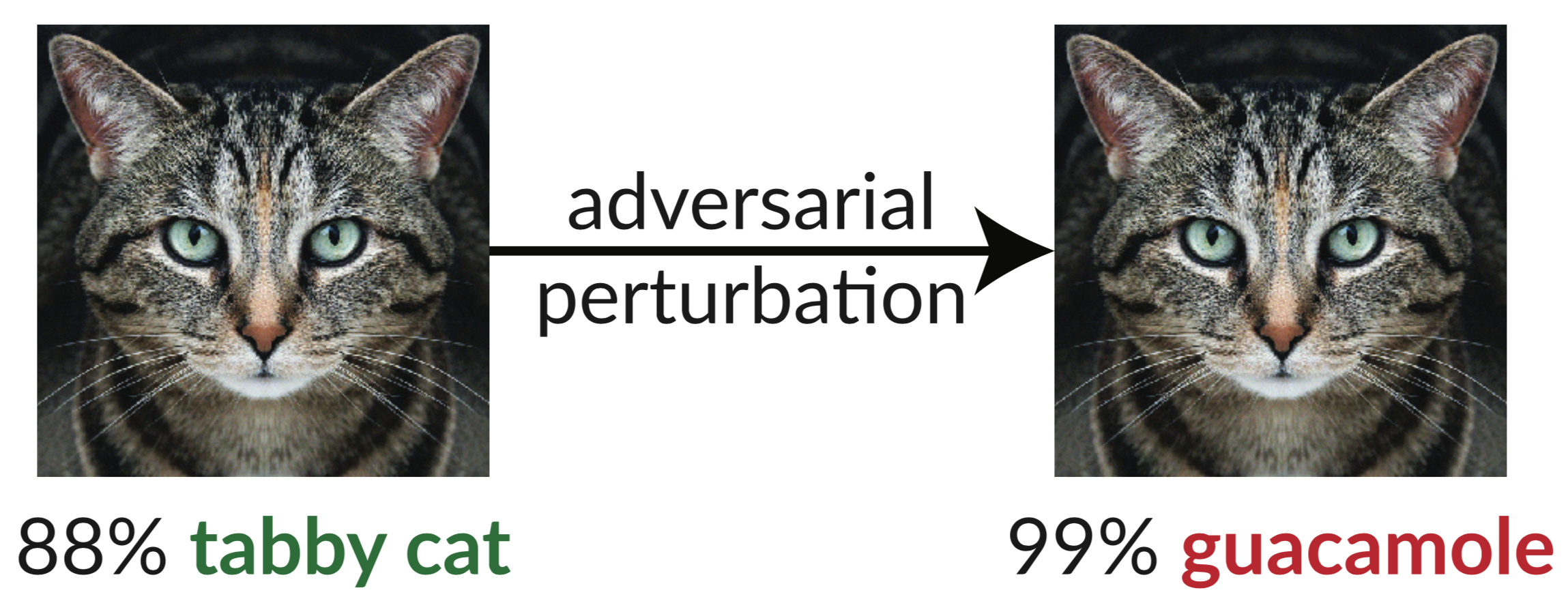
Di atas adalah contoh yang berlawanan: gambar kucing yang sedikit terganggu membodohi pengklasifikasi InceptionV3 dengan mengklasifikasikannya sebagai "guacamole". "Gambar bodoh" seperti itu mudah disintesis menggunakan penurunan gradien (Szegedy dkk. 2013).
Dalam makalah terbaru kami, kami mengevaluasi ketangguhan sembilan makalah yang diterima di ICLR 2018 sebagai pertahanan white-box-secure yang tidak tersertifikasi terhadap contoh-contoh yang bersifat permusuhan. Kami menemukan bahwa tujuh dari sembilan pertahanan memberikan peningkatan ketahanan yang terbatas dan dapat dipatahkan dengan peningkatan teknik serangan yang kami kembangkan.
Di bawah ini adalah Tabel 1 dari makalah kami, di mana kami menunjukkan kekokohan setiap pembelaan yang diterima terhadap contoh-contoh permusuhan yang dapat kami bangun:
| Pertahanan | Kumpulan data | Jarak | Ketepatan |
|---|---|---|---|
| Buckman dkk. (2018) | CIFAR | 0,031 (linf) | 0%* |
| Ma dkk. (2018) | CIFAR | 0,031 (linf) | 5% |
| Guo dkk. (2018) | GambarNet | 0,05 (l2) | 0%* |
| Dhillon dkk. (2018) | CIFAR | 0,031 (linf) | 0% |
| Xie dkk. (2018) | GambarNet | 0,031 (linf) | 0%* |
| Lagu dkk. (2018) | CIFAR | 0,031 (linf) | 9%* |
| Samangouei dkk. (2018) | MNIST | 0,005 (l2) | 55%** |
| Madry dkk. (2018) | CIFAR | 0,031 (linf) | 47% |
| Na dkk. (2018) | CIFAR | 0,015 (linf) | 15% |
(Pertahanan yang dilambangkan dengan * juga mengusulkan penggabungan pelatihan permusuhan; kami melaporkan di sini pertahanannya saja. Lihat makalah kami, Bagian 5 untuk mengetahui angka selengkapnya. Prinsip dasar di balik pertahanan yang dilambangkan dengan ** memiliki akurasi 0%; dalam praktiknya, ketidaksempurnaan pertahanan menyebabkan secara teoritis serangan optimal untuk gagal, lihat Bagian 5.4.2 untuk rinciannya.)
Satu-satunya pertahanan yang kami amati yang secara signifikan meningkatkan ketahanan terhadap contoh-contoh permusuhan dalam model ancaman yang diusulkan adalah "Menuju Model Pembelajaran Mendalam yang Tahan terhadap Serangan Adversarial" (Madry dkk. 2018), dan kami tidak dapat mengalahkan pertahanan ini tanpa keluar dari model ancaman . Meski begitu, teknik ini terbukti sulit untuk disesuaikan dengan skala ImageNet (Kurakin et al. 2016). Makalah-makalah lainnya (selain makalah oleh Na dkk., yang memberikan ketahanan terbatas) secara tidak sengaja atau sengaja mengandalkan apa yang kita sebut gradien yang dikaburkan . Serangan standar menerapkan penurunan gradien untuk memaksimalkan hilangnya jaringan pada gambar tertentu guna menghasilkan contoh permusuhan pada jaringan saraf. Metode optimasi seperti itu memerlukan sinyal gradien yang berguna agar berhasil. Ketika pertahanan mengaburkan gradien, ia merusak sinyal gradien ini dan menyebabkan metode berbasis pengoptimalan gagal.
Kami mengidentifikasi tiga cara pertahanan menyebabkan gradien yang kabur, dan menyusun serangan untuk melewati setiap kasus ini. Serangan kami secara umum berlaku untuk pertahanan apa pun yang mencakup, baik disengaja atau tidak disengaja, operasi yang tidak dapat dibedakan atau mencegah sinyal gradien mengalir melalui jaringan. Kami berharap pekerjaan di masa depan akan dapat menggunakan pendekatan kami untuk melakukan evaluasi keamanan yang lebih menyeluruh.
Abstrak:
Kami mengidentifikasi gradien yang dikaburkan, semacam penyamaran gradien, sebagai fenomena yang mengarah pada rasa aman yang salah dalam pertahanan terhadap contoh-contoh yang merugikan. Meskipun pertahanan yang menyebabkan gradien yang dikaburkan tampaknya dapat mengalahkan serangan berbasis pengoptimalan berulang, kami menemukan bahwa pertahanan yang mengandalkan efek ini dapat dielakkan. Kami mendeskripsikan perilaku karakteristik pertahanan yang menunjukkan efek tersebut, dan untuk masing-masing dari tiga jenis gradien kabur yang kami temukan, kami mengembangkan teknik serangan untuk mengatasinya. Dalam sebuah studi kasus, yang memeriksa pertahanan white-box-secure yang tidak bersertifikat di ICLR 2018, kami menemukan bahwa gradien yang dikaburkan adalah kejadian umum, dengan 7 dari 9 pertahanan mengandalkan gradien yang dikaburkan. Serangan baru kami berhasil menghindari 6 serangan sepenuhnya, dan 1 sebagian, dalam model ancaman awal yang dipertimbangkan setiap makalah.
Untuk detailnya, baca makalah kami.
Repositori ini berisi contoh teknik serangan umum yang dijelaskan dalam makalah kami, yang memecahkan 7 pertahanan ICLR 2018. Beberapa pertahanan tidak merilis kode sumber (pada saat kami melakukan pekerjaan ini), jadi kami harus menerapkannya kembali.
@inproceedings{obfuscated-gradients, author = {Anish Athalye dan Nicholas Carlini dan David Wagner}, title = {Gradien yang Dikaburkan Memberikan Rasa Aman yang Palsu: Menghindari Pertahanan terhadap Contoh Adversarial}, booktitle = {Prosiding Konferensi Internasional ke-35 tentang Mesin Pembelajaran, {ICML} 2018}, tahun = {2018}, bulan = Juli, url = {https://arxiv.org/abs/1802.00420},
} 

