Megatron LM
NVIDIA Megatron Core 0.9.0
Repositori ini terdiri dari dua komponen penting: Megatron-LM dan Megatron-Core . Megatron-LM berfungsi sebagai kerangka kerja berorientasi penelitian yang memanfaatkan Megatron-Core untuk pelatihan model bahasa besar (LLM). Megatron-Core, di sisi lain, adalah perpustakaan teknik pelatihan yang dioptimalkan GPU yang dilengkapi dengan dukungan produk formal termasuk API berversi dan rilis reguler. Anda dapat menggunakan Megatron-Core bersama Megatron-LM atau Nvidia NeMo Framework untuk solusi end-to-end dan cloud-native. Alternatifnya, Anda dapat mengintegrasikan elemen penyusun Megatron-Core ke dalam kerangka pelatihan pilihan Anda.
Pertama kali diperkenalkan pada tahun 2019, Megatron (1, 2, dan 3) memicu gelombang inovasi dalam komunitas AI, memungkinkan peneliti dan pengembang memanfaatkan dasar-dasar perpustakaan ini untuk memajukan kemajuan LLM. Saat ini, banyak kerangka kerja pengembang LLM yang paling populer telah terinspirasi dan dibangun secara langsung dengan memanfaatkan perpustakaan sumber terbuka Megatron-LM, sehingga memacu gelombang model dasar dan startup AI. Beberapa kerangka kerja LLM paling populer yang dibangun di atas Megatron-LM termasuk Colossal-AI, HuggingFace Accelerate, dan NVIDIA NeMo Framework. Daftar proyek yang pernah menggunakan Megatron secara langsung dapat ditemukan di sini.
Megatron-Core adalah pustaka sumber terbuka berbasis PyTorch yang berisi teknik yang dioptimalkan GPU dan pengoptimalan tingkat sistem yang mutakhir. Ini mengabstraksikannya menjadi API yang dapat disusun dan modular, memungkinkan fleksibilitas penuh bagi pengembang dan peneliti model untuk melatih transformator khusus dalam skala besar pada infrastruktur komputasi akselerasi NVIDIA. Pustaka ini kompatibel dengan semua GPU NVIDIA Tensor Core, termasuk dukungan akselerasi FP8 untuk arsitektur NVIDIA Hopper.
Megatron-Core menawarkan blok penyusun inti seperti mekanisme perhatian, blok dan lapisan transformator, lapisan normalisasi, dan teknik penyematan. Fungsionalitas tambahan seperti penghitungan ulang aktivasi, pos pemeriksaan terdistribusi juga sudah ada di dalam perpustakaan. Komponen dan fungsionalitas semuanya dioptimalkan untuk GPU, dan dapat dibangun dengan strategi paralelisasi tingkat lanjut untuk kecepatan dan stabilitas pelatihan optimal pada NVIDIA Accelerated Computing Infrastructure. Komponen penting lainnya dari perpustakaan Megatron-Core mencakup teknik paralelisme model tingkat lanjut (tensor, urutan, saluran pipa, konteks, dan paralelisme ahli MoE).
Megatron-Core dapat digunakan dengan NVIDIA NeMo, platform AI tingkat perusahaan. Alternatifnya, Anda dapat menjelajahi Megatron-Core dengan loop pelatihan PyTorch asli di sini. Kunjungi dokumentasi Megatron-Core untuk mempelajari lebih lanjut.
Basis kode kami mampu melatih model bahasa besar secara efisien (yaitu model dengan ratusan miliar parameter) dengan paralelisme model dan data. Untuk mendemonstrasikan bagaimana perangkat lunak kami dapat diskalakan dengan berbagai GPU dan ukuran model, kami mempertimbangkan model GPT yang berkisar dari 2 miliar parameter hingga 462 miliar parameter. Semua model menggunakan ukuran kosakata 131.072 dan panjang urutan 4096. Kami memvariasikan ukuran tersembunyi, jumlah kepala perhatian, dan jumlah lapisan untuk sampai pada ukuran model tertentu. Seiring bertambahnya ukuran model, kami juga sedikit meningkatkan ukuran batch. Eksperimen kami menggunakan hingga 6144 GPU H100. Kami melakukan tumpang tindih data-paralel ( --overlap-grad-reduce --overlap-param-gather ), tensor-parallel ( --tp-comm-overlap ) dan komunikasi paralel pipa (diaktifkan secara default) dengan komputasi untuk meningkatkan skalabilitas. Throughput yang dilaporkan diukur untuk pelatihan end-to-end dan mencakup semua operasi termasuk pemuatan data, langkah-langkah pengoptimal, komunikasi, dan bahkan logging. Perhatikan bahwa kami tidak melatih model ini hingga konvergensi.
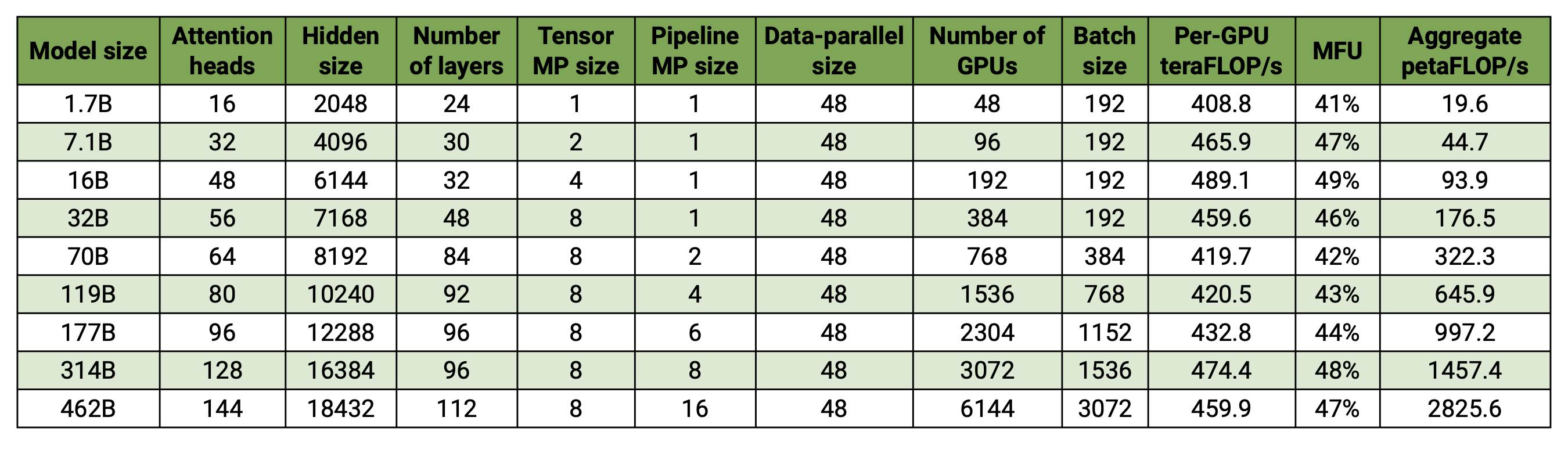
Hasil skala lemah kami menunjukkan penskalaan superlinear (MFU meningkat dari 41% untuk model terkecil menjadi 47-48% untuk model terbesar); hal ini karena GEMM yang lebih besar memiliki intensitas aritmatika yang lebih tinggi sehingga lebih efisien untuk dieksekusi.
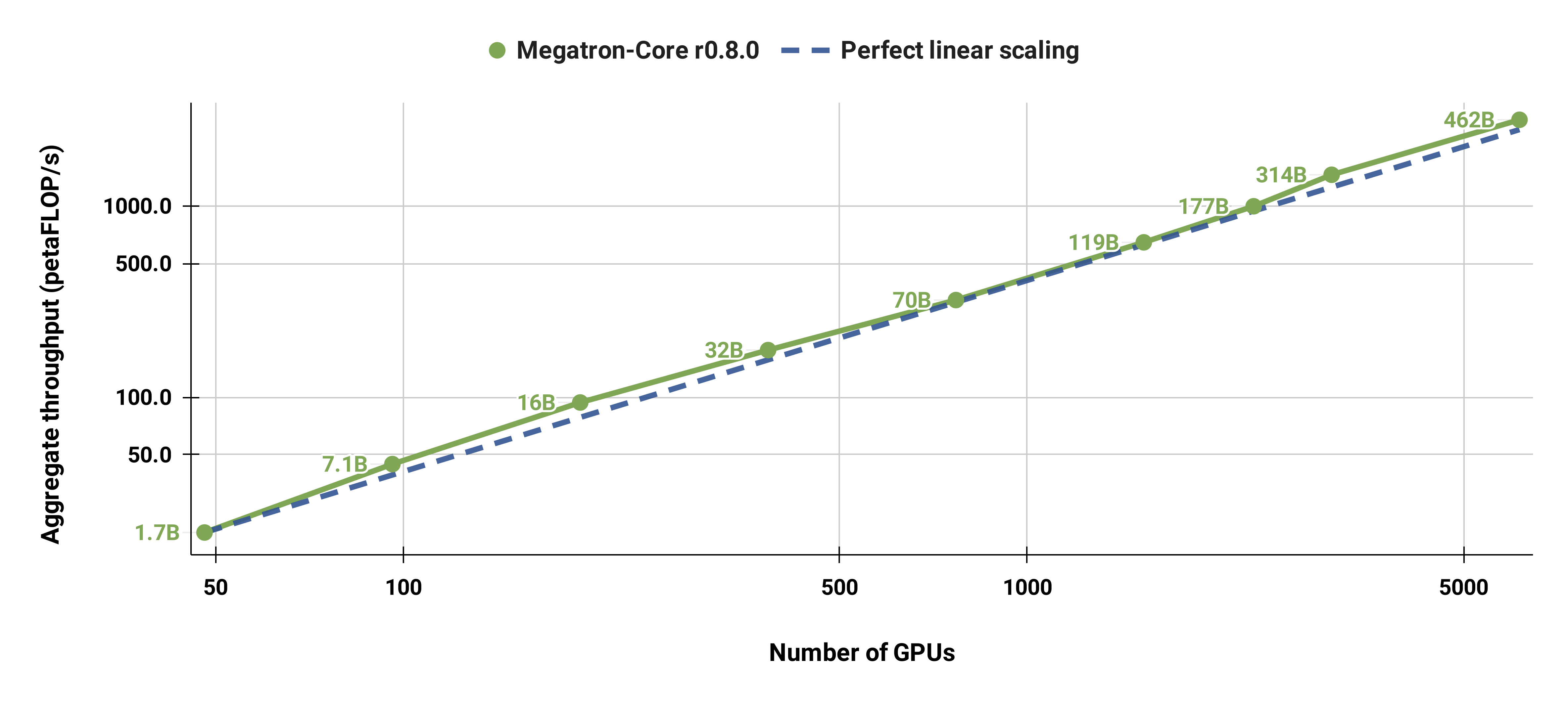
Kami juga dengan kuat menskalakan model GPT-3 standar (versi kami memiliki lebih dari 175 miliar parameter karena ukuran kosakata yang lebih besar) dari 96 GPU H100 menjadi 4608 GPU, menggunakan ukuran batch yang sama yaitu 1152 urutan secara keseluruhan. Komunikasi menjadi lebih terekspos pada skala yang lebih besar, sehingga menyebabkan penurunan MFU dari 47% menjadi 42%.
Kami sangat menyarankan penggunaan rilis terbaru kontainer PyTorch NGC dengan node DGX. Jika Anda tidak dapat menggunakan ini karena alasan tertentu, gunakan rilis pytorch, cuda, nccl, dan NVIDIA APEX terbaru. Pemrosesan awal data memerlukan NLTK, meskipun hal ini tidak diperlukan untuk pelatihan, evaluasi, atau tugas hilir.
Anda dapat meluncurkan instance container PyTorch dan memasang Megatron, kumpulan data, dan pos pemeriksaan Anda dengan perintah Docker berikut:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
Kami telah menyediakan pos pemeriksaan BERT-345M dan GPT-345M yang telah dilatih sebelumnya untuk mengevaluasi atau menyempurnakan tugas-tugas hilir. Untuk mengakses pos pemeriksaan ini, pertama-tama daftar dan siapkan CLI Registri NVIDIA GPU Cloud (NGC). Dokumentasi lebih lanjut untuk mengunduh model dapat ditemukan di dokumentasi NGC.
Alternatifnya, Anda dapat langsung mengunduh pos pemeriksaan menggunakan:
BERT-345M-tanpa casing: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
Model memerlukan file kosakata untuk dijalankan. File vocab BERT WordPiece dapat diekstraksi dari model BERT Google yang telah dilatih sebelumnya: tanpa casing, dengan casing. File vocab GPT dan tabel gabungan dapat diunduh langsung.
Setelah instalasi, ada beberapa kemungkinan alur kerja. Yang paling komprehensif adalah:
Namun, langkah 1 dan 2 dapat diganti dengan menggunakan salah satu model terlatih yang disebutkan di atas.
Kami telah menyediakan beberapa skrip untuk pra-pelatihan BERT dan GPT di direktori examples , serta skrip untuk tugas downstream zero-shot dan fine-tuned termasuk evaluasi MNLI, RACE, WikiText103, dan LAMBADA. Ada juga skrip untuk pembuatan teks interaktif GPT.
Data pelatihan memerlukan prapemrosesan. Pertama, tempatkan data pelatihan Anda dalam format json yang longgar, dengan satu json berisi contoh teks per baris. Misalnya:
{"src": "www.nvidia.com", "text": "Rubah coklat cepat", "type": "Eng", "id": "0", "title": "Bagian Pertama"}
{"src": "Internet", "text": "melompati anjing pemalas", "type": "Eng", "id": "42", "title": "Bagian Kedua"}
Nama bidang text json dapat diubah dengan menggunakan tanda --json-key di preprocess_data.py Metadata lainnya bersifat opsional dan tidak digunakan dalam pelatihan.
Json yang longgar kemudian diproses menjadi format biner untuk pelatihan. Untuk mengonversi json ke format mmap gunakan preprocess_data.py . Contoh skrip untuk menyiapkan data untuk pelatihan BERT adalah:
alat python/preprocess_data.py
--masukan my-corpus.json
--output-awalan my-bert
--vocab-file bert-vocab.txt
--tipe tokenizer BertWordPieceLowerCase
--kalimat terpisah
Outputnya akan berupa dua file bernama, dalam hal ini, my-bert_text_sentence.bin dan my-bert_text_sentence.idx . --data-path yang ditentukan dalam pelatihan BERT selanjutnya adalah jalur lengkap dan nama file baru, tetapi tanpa ekstensi file.
Untuk T5 gunakan preprocessing yang sama seperti BERT, mungkin mengganti namanya menjadi:
--keluaran-awalan my-t5
Beberapa modifikasi kecil diperlukan untuk prapemrosesan data GPT, yaitu penambahan tabel gabungan, token akhir dokumen, penghapusan pemisahan kalimat, dan perubahan pada jenis tokenizer:
alat python/preprocess_data.py
--masukan my-corpus.json
--output-awalan my-gpt2
--file-vocab gpt2-vocab.json
--tipe tokenizer GPT2BPETokenizer
--merge-file gpt2-merges.txt
--tambahkan-eod
Di sini file keluaran diberi nama my-gpt2_text_document.bin dan my-gpt2_text_document.idx . Seperti sebelumnya, dalam pelatihan GPT, gunakan nama yang lebih panjang tanpa ekstensi sebagai --data-path .
Argumen baris perintah lebih lanjut dijelaskan dalam file sumber preprocess_data.py .
Skrip examples/bert/train_bert_340m_distributed.sh menjalankan prapelatihan BERT parameter GPU 345M tunggal. Debugging adalah penggunaan utama untuk pelatihan GPU tunggal, karena basis kode dan argumen baris perintah dioptimalkan untuk pelatihan yang sangat terdistribusi. Sebagian besar argumennya cukup jelas. Secara default, kecepatan pembelajaran meluruh secara linier selama iterasi pelatihan yang dimulai dari --lr hingga minimum yang ditetapkan oleh --min-lr melalui iterasi --lr-decay-iters . Fraksi iterasi pelatihan yang digunakan untuk pemanasan diatur oleh --lr-warmup-fraction . Meskipun ini adalah pelatihan GPU tunggal, ukuran batch yang ditentukan oleh --micro-batch-size adalah ukuran batch jalur maju-mundur tunggal dan kode akan melakukan langkah-langkah akumulasi gradien hingga mencapai global-batch-size yang merupakan ukuran batch per iterasi. Data dipartisi menjadi rasio 949:50:1 untuk set pelatihan/validasi/pengujian (defaultnya adalah 969:30:1). Partisi ini terjadi dengan cepat, tetapi konsisten di seluruh proses dengan seed acak yang sama (1234 secara default, atau ditentukan secara manual dengan --seed ). Kami menggunakan train-iters sebagai iterasi pelatihan yang diminta. Alternatifnya, seseorang dapat menyediakan --train-samples yang merupakan jumlah total sampel untuk dilatih. Jika opsi ini ada, alih-alih menyediakan --lr-decay-iters , Anda perlu menyediakan --lr-decay-samples .
Opsi pencatatan log, penyimpanan pos pemeriksaan, dan interval evaluasi ditentukan. Perhatikan bahwa --data-path sekarang menyertakan akhiran _text_sentence tambahan yang ditambahkan dalam prapemrosesan, namun tidak menyertakan ekstensi file.
Argumen baris perintah lebih lanjut dijelaskan dalam file sumber arguments.py .
Untuk menjalankan train_bert_340m_distributed.sh , lakukan modifikasi apa pun yang diinginkan termasuk menyetel variabel lingkungan untuk CHECKPOINT_PATH , VOCAB_FILE , dan DATA_PATH . Pastikan untuk mengatur variabel-variabel ini ke jalurnya di dalam wadah. Kemudian luncurkan wadah dengan Megatron dan jalur yang diperlukan terpasang (seperti yang dijelaskan dalam Pengaturan) dan jalankan skrip contoh.
Skrip examples/gpt3/train_gpt3_175b_distributed.sh menjalankan prapelatihan GPT parameter GPU 345M tunggal. Seperti disebutkan di atas, pelatihan GPU tunggal terutama ditujukan untuk tujuan debugging, karena kodenya dioptimalkan untuk pelatihan terdistribusi.
Ini sebagian besar mengikuti format yang sama dengan skrip BERT sebelumnya dengan beberapa perbedaan penting: skema tokenisasi yang digunakan adalah BPE (yang memerlukan tabel gabungan dan file kosakata json ) alih-alih WordPiece, arsitektur model memungkinkan urutan yang lebih panjang (perhatikan bahwa penyematan posisi maks harus lebih besar dari atau sama dengan panjang urutan maksimum), dan --lr-decay-style telah disetel ke peluruhan kosinus. Perhatikan bahwa --data-path sekarang menyertakan akhiran _text_document tambahan yang ditambahkan dalam prapemrosesan, namun tidak menyertakan ekstensi file.
Argumen baris perintah lebih lanjut dijelaskan dalam file sumber arguments.py .
train_gpt3_175b_distributed.sh dapat diluncurkan dengan cara yang sama seperti yang dijelaskan untuk BERT. Atur env vars dan buat modifikasi lainnya, luncurkan container dengan mount yang sesuai, dan jalankan skrip. Detail lebih lanjut di examples/gpt3/README.md
Sangat mirip dengan BERT dan GPT, skrip examples/t5/train_t5_220m_distributed.sh menjalankan pra-pelatihan T5 "dasar" GPU tunggal (parameter ~220M). Perbedaan utama dari BERT dan GPT adalah penambahan argumen berikut untuk mengakomodasi arsitektur T5:
--kv-channels menetapkan dimensi dalam matriks "kunci" dan "nilai" dari semua mekanisme perhatian dalam model. Untuk BERT dan GPT, defaultnya adalah ukuran tersembunyi dibagi dengan jumlah kepala perhatian, tetapi dapat dikonfigurasi untuk T5.
--ffn-hidden-size menyetel ukuran tersembunyi di jaringan feed-forward dalam lapisan transformator. Untuk BERT dan GPT, defaultnya adalah 4 kali ukuran tersembunyi transformator, tetapi dapat dikonfigurasi untuk T5.
--encoder-seq-length dan --decoder-seq-length mengatur panjang urutan untuk encoder dan decoder secara terpisah.
Semua argumen lainnya tetap sama untuk prapelatihan BERT dan GPT. Jalankan contoh ini dengan langkah yang sama seperti dijelaskan di atas untuk skrip lainnya.
Detail selengkapnya di examples/t5/README.md
Skrip pretrain_{bert,gpt,t5}_distributed.sh menggunakan peluncur terdistribusi PyTorch untuk pelatihan terdistribusi. Dengan demikian, pelatihan multi-node dapat dicapai dengan mengatur variabel lingkungan dengan benar. Lihat dokumentasi resmi PyTorch untuk penjelasan lebih lanjut tentang variabel lingkungan ini. Secara default, pelatihan multi-node menggunakan backend terdistribusi nccl. Serangkaian argumen tambahan sederhana dan penggunaan modul terdistribusi PyTorch dengan peluncur elastis torchrun (setara dengan python -m torch.distributed.run ) adalah satu-satunya persyaratan tambahan untuk mengadopsi pelatihan terdistribusi. Lihat salah satu dari pretrain_{bert,gpt,t5}_distributed.sh untuk detail lebih lanjut.
Kami menggunakan dua jenis paralelisme: paralelisme data dan model. Implementasi paralelisme data kami ada di megatron/core/distributed , dan mendukung tumpang tindih pengurangan gradien dengan backward pass ketika opsi baris perintah --overlap-grad-reduce digunakan.
Kedua, kami mengembangkan pendekatan paralel model dua dimensi yang sederhana dan efisien. Untuk menggunakan dimensi pertama, paralelisme model tensor (memisahkan eksekusi modul transformator tunggal pada beberapa GPU, lihat Bagian 3 makalah kami), tambahkan tanda --tensor-model-parallel-size untuk menentukan jumlah GPU yang akan digunakan. pisahkan modelnya, beserta argumen yang diteruskan ke peluncur terdistribusi seperti yang disebutkan di atas. Untuk menggunakan dimensi kedua, paralelisme urutan, tentukan --sequence-parallel , yang juga memerlukan pengaktifan paralelisme model tensor karena terbagi di GPU yang sama (detail selengkapnya ada di Bagian 4.2.2 makalah kami).
Untuk menggunakan paralelisme model pipeline (membagi modul transformator menjadi beberapa tahap dengan jumlah modul transformator yang sama di setiap tahap, dan kemudian melakukan eksekusi pipeline dengan memecah batch menjadi microbatch yang lebih kecil, lihat Bagian 2.2 makalah kami), gunakan --pipeline-model-parallel-size -tanda --pipeline-model-parallel-size untuk menentukan jumlah tahapan untuk membagi model (misalnya, membagi model dengan 24 lapisan transformator menjadi 4 tahap berarti setiap tahap mendapat 6 lapisan transformator masing-masing).
Kami memiliki contoh bagaimana menggunakan dua bentuk paralelisme model yang berbeda ini, contoh skrip yang diakhiri dengan distributed_with_mp.sh .
Selain perubahan kecil ini, pelatihan terdistribusi identik dengan pelatihan pada satu GPU.
Jadwal pipelining yang disisipkan (detail lebih lanjut di Bagian 2.2.2 makalah kami) dapat diaktifkan menggunakan argumen --num-layers-per-virtual-pipeline-stage , yang mengontrol jumlah lapisan transformator dalam tahap virtual (secara default dengan jadwal non-interleaved, setiap GPU akan menjalankan satu tahap virtual dengan NUM_LAYERS / PIPELINE_MP_SIZE lapisan transformator). Jumlah total lapisan dalam model transformator harus habis dibagi nilai argumen ini. Selain itu, jumlah microbatch dalam pipa (dihitung sebagai GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) harus habis dibagi PIPELINE_MP_SIZE saat menggunakan jadwal ini (kondisi ini diperiksa dalam pernyataan dalam kode). Jadwal yang disisipkan tidak didukung untuk saluran pipa dengan 2 tahap ( PIPELINE_MP_SIZE=2 ).
Untuk mengurangi penggunaan memori GPU saat melatih model besar, kami mendukung berbagai bentuk pemeriksaan aktivasi dan penghitungan ulang. Alih-alih semua aktivasi disimpan dalam memori untuk digunakan selama backprop, seperti yang biasanya terjadi dalam model pembelajaran mendalam, hanya aktivasi pada "titik pemeriksaan" tertentu dalam model yang dipertahankan (atau disimpan) dalam memori, dan aktivasi lainnya dihitung ulang pada -the-fly bila diperlukan untuk backprop. Perhatikan bahwa pos pemeriksaan semacam ini, pos pemeriksaan aktivasi , sangat berbeda dari pos pemeriksaan parameter model dan status pengoptimal, yang disebutkan di tempat lain.
Kami mendukung dua tingkat perincian perhitungan ulang: selective dan full . Penghitungan ulang selektif adalah default dan direkomendasikan di hampir semua kasus. Mode ini menyimpan dalam memori aktivasi yang memerlukan lebih sedikit ruang penyimpanan memori dan lebih mahal untuk dihitung ulang dan menghitung ulang aktivasi yang memerlukan lebih banyak ruang penyimpanan memori namun relatif murah untuk dihitung ulang. Lihat makalah kami untuk detailnya. Anda akan menemukan bahwa mode ini memaksimalkan kinerja sekaligus meminimalkan memori yang diperlukan untuk menyimpan aktivasi. Untuk mengaktifkan penghitungan ulang aktivasi selektif cukup gunakan --recompute-activations .
Untuk kasus dimana memori sangat terbatas, komputasi ulang full hanya menyimpan input ke lapisan transformator, atau grup, atau blok, lapisan transformator, dan menghitung ulang yang lainnya. Untuk mengaktifkan aktivasi penuh, gunakan perhitungan ulang --recompute-granularity full . Saat menggunakan penghitungan ulang aktivasi full , ada dua metode: uniform dan block , dipilih menggunakan argumen --recompute-method .
Metode uniform membagi lapisan transformator secara seragam menjadi beberapa kelompok lapisan (setiap kelompok berukuran --recompute-num-layers ) dan menyimpan aktivasi masukan dari setiap kelompok dalam memori. Ukuran grup dasar adalah 1 dan, dalam hal ini, aktivasi masukan dari setiap lapisan transformator disimpan. Jika memori GPU tidak mencukupi, menambah jumlah lapisan per grup akan mengurangi penggunaan memori, sehingga memungkinkan model yang lebih besar untuk dilatih. Misalnya, ketika --recompute-num-layers diatur ke 4, hanya aktivasi input dari setiap grup yang terdiri dari 4 lapisan transformator yang disimpan.
Metode block menghitung ulang aktivasi masukan dari nomor tertentu (diberikan oleh --recompute-num-layers ) dari masing-masing lapisan transformator per tahap saluran pipa dan menyimpan aktivasi masukan dari lapisan yang tersisa dalam tahap saluran pipa. Mengurangi --recompute-num-layers menghasilkan penyimpanan aktivasi input ke lebih banyak lapisan transformator, yang mengurangi perhitungan ulang aktivasi yang diperlukan di backprop, sehingga meningkatkan kinerja pelatihan sekaligus meningkatkan penggunaan memori. Misalnya, ketika kita menentukan 5 lapisan untuk menghitung ulang 8 lapisan per tahapan pipa, aktivasi masukan hanya dari 5 lapisan transformator pertama dihitung ulang pada langkah backprop sementara aktivasi masukan untuk 3 lapisan terakhir disimpan. --recompute-num-layers dapat ditingkatkan secara bertahap hingga jumlah ruang penyimpanan memori yang diperlukan cukup kecil untuk muat dalam memori yang tersedia, sehingga memanfaatkan memori secara maksimal dan memaksimalkan kinerja.
Penggunaan: --use-distributed-optimizer . Kompatibel dengan semua model dan tipe data.
Pengoptimal terdistribusi adalah teknik penghematan memori, dimana status pengoptimal didistribusikan secara merata di seluruh peringkat paralel data (dibandingkan dengan metode tradisional yang mereplikasi status pengoptimal di seluruh peringkat paralel data). Seperti yang dijelaskan dalam ZeRO: Optimasi Memori Menuju Pelatihan Model Triliun Parameter, implementasi kami mendistribusikan semua status pengoptimal yang tidak tumpang tindih dengan status model. Misalnya, saat menggunakan parameter model fp16, pengoptimal terdistribusi menyimpan salinan parameter & lulusan utama fp32 yang terpisah, yang didistribusikan ke seluruh peringkat DP. Namun, ketika menggunakan param model bf16, nilai utama fp32 pengoptimal terdistribusi sama dengan nilai fp32 model, sehingga nilai dalam kasus ini tidak didistribusikan (walaupun parameter utama fp32 masih terdistribusi, karena terpisah dari bf16 parameter model).
Penghematan memori teoritis bervariasi tergantung pada kombinasi param dtype dan grad dtype model. Dalam implementasi kami, jumlah teoritis byte per parameter adalah (di mana 'd' adalah ukuran paralel data):
| Optimal yang tidak terdistribusi | Optimal terdistribusi | |
|---|---|---|
| param fp16, lulusan fp16 | 20 | 4 + 16/hari |
| param bf16, lulusan fp32 | 18 | 6 + 12/hari |
| param fp32, lulusan fp32 | 16 | 8 + 8/hari |
Seperti halnya paralelisme data biasa, tumpang tindih pengurangan gradien (dalam hal ini, pengurangan-penyebaran) dengan penerusan mundur dapat difasilitasi menggunakan tanda --overlap-grad-reduce . Selain itu, tumpang tindih parameter all-gather dapat ditumpangkan dengan forward pass menggunakan --overlap-param-gather .
Penggunaan: --use-flash-attn . Mendukung perhatian dimensi kepala paling banyak 128.
FlashAttention adalah algoritma yang cepat dan hemat memori untuk menghitung perhatian yang tepat. Ini mempercepat pelatihan model dan mengurangi kebutuhan memori.
Untuk menginstal FlashAttention:
pip install flash-attn Dalam examples/gpt3/train_gpt3_175b_distributed.sh kami telah memberikan contoh cara mengkonfigurasi Megatron untuk melatih GPT-3 dengan 175 miliar parameter pada 1024 GPU. Skrip ini dirancang untuk slurm dengan plugin pyxis tetapi dapat dengan mudah diadopsi ke penjadwal lainnya. Ia menggunakan paralelisme tensor 8 arah dan paralelisme pipa 16 arah. Dengan opsi global-batch-size 1536 dan rampup-batch-size 16 16 5859375 , pelatihan akan dimulai dengan ukuran batch global 16 dan secara linier meningkatkan ukuran batch global menjadi 1536 pada 5.859.375 sampel dengan langkah bertahap 16. Kumpulan data pelatihan dapat berupa satu set atau beberapa set data yang digabungkan dengan satu set bobot.
Dengan ukuran batch global penuh sebesar 1536 pada 1024 GPU A100, setiap iterasi memerlukan waktu sekitar 32 detik sehingga menghasilkan 138 teraFLOP per GPU yang merupakan 44% dari puncak FLOP teoritis.
Retro (Borgeaud et al., 2022) adalah model bahasa khusus dekoder autoregresif (LM) yang dilatih sebelumnya dengan augmentasi pengambilan. Retro menghadirkan skalabilitas praktis untuk mendukung pra-pelatihan skala besar dari awal dengan mengambil triliunan token. Pelatihan awal dengan pengambilan memberikan mekanisme penyimpanan pengetahuan faktual yang lebih efisien, jika dibandingkan dengan menyimpan pengetahuan faktual secara implisit dalam parameter jaringan, sehingga mengurangi sebagian besar parameter model sekaligus mencapai kebingungan yang lebih rendah dibandingkan GPT standar. Retro juga memberikan fleksibilitas untuk memperbarui pengetahuan yang disimpan di LM (Wang et al., 2023a) dengan memperbarui database pengambilan tanpa melatih LM lagi.
InstructRetro (Wang et al., 2023b) selanjutnya meningkatkan ukuran Retro menjadi 48B, menampilkan LLM terbesar yang telah dilatih sebelumnya dengan pengambilan (per Desember 2023). Model fondasi yang diperoleh, Retro 48B, sebagian besar mengungguli model GPT dalam hal kebingungan. Dengan penyetelan instruksi di Retro, InstructRetro menunjukkan peningkatan yang signifikan dibandingkan instruksi yang disetel GPT pada tugas hilir dalam pengaturan zero-shot. Secara khusus, peningkatan rata-rata InstructRetro adalah 7% dibandingkan GPT pada 8 tugas QA bentuk pendek, dan 10% dibandingkan GPT pada 4 tugas QA bentuk panjang yang menantang. Kami juga menemukan bahwa seseorang dapat menghapus encoder dari arsitektur InstructRetro dan langsung menggunakan tulang punggung decoder InstructRetro sebagai GPT, sekaligus mencapai hasil yang sebanding.
Dalam repo ini, kami menyediakan panduan reproduksi end-to-end untuk mengimplementasikan penutup Retro dan InstructRetro
Lihat tools/retro/README.md untuk gambaran rinci.
Lihat contoh/mamba untuk detailnya.
Kami menyediakan beberapa argumen baris perintah, yang dirinci dalam skrip yang tercantum di bawah ini, untuk menangani berbagai tugas downstream yang zero-shot dan disempurnakan. Namun, Anda juga dapat menyempurnakan model Anda dari pos pemeriksaan terlatih di korpora lain sesuai keinginan. Untuk melakukannya, cukup tambahkan tanda --finetune dan sesuaikan file input dan parameter pelatihan dalam skrip pelatihan asli. Jumlah iterasi akan diatur ulang ke nol, dan pengoptimal serta status internal akan diinisialisasi ulang. Jika penyetelan halus terganggu karena alasan apa pun, pastikan untuk menghapus tanda --finetune sebelum melanjutkan, jika tidak, pelatihan akan dimulai lagi dari awal.
Karena evaluasi memerlukan memori yang jauh lebih sedikit dibandingkan pelatihan, mungkin akan lebih menguntungkan jika menggabungkan model yang dilatih secara paralel untuk digunakan pada GPU yang lebih sedikit dalam tugas hilir. Skrip berikut menyelesaikan hal ini. Contoh ini membaca model GPT dengan tensor 4 arah dan paralelisme model pipa 4 arah dan menulis model dengan tensor 2 arah dan paralelisme model pipa 2 arah.
alat python/pos pemeriksaan/convert.py
--tipe model GPT
--load-dir pos pemeriksaan/gpt3_tp4_pp4
--simpan-dir pos pemeriksaan/gpt3_tp2_pp2
--target-tensor-ukuran paralel 2
--target-pipa-paralel-ukuran 2
Beberapa tugas hilir dijelaskan untuk model GPT dan BERT di bawah ini. Mereka dapat dijalankan dalam mode terdistribusi dan model paralel dengan perubahan yang sama seperti yang digunakan dalam skrip pelatihan.
Kami telah menyertakan server REST sederhana untuk digunakan dalam pembuatan teks di tools/run_text_generation_server.py . Anda menjalankannya seperti Anda memulai pekerjaan pra-pelatihan, menentukan pos pemeriksaan pra-pelatihan yang sesuai. Ada juga beberapa parameter opsional: temperature , top-k dan top-p . Lihat --help atau file sumber untuk informasi lebih lanjut. Lihat contoh/inferensi/run_text_generasi_server_345M.sh untuk contoh cara menjalankan server.
Setelah server berjalan, Anda dapat menggunakan tools/text_generation_cli.py untuk menanyakannya, dibutuhkan satu argumen yang merupakan host tempat server berjalan.
alat/text_generasi_cli.py localhost:5000
Anda juga dapat menggunakan CURL atau alat lainnya untuk menanyakan server secara langsung:
curl 'http://localhost:5000/api' -X 'PUT' -H 'Tipe Konten: application/json; charset=UTF-8' -d '{"prompts":["Halo dunia"], "tokens_to_generate":1}'
Lihat megatron/inference/text_generasi_server.py untuk opsi API lainnya.
Kami menyertakan contoh dalam examples/academic_paper_scripts/detxoify_lm/ untuk mendetoksifikasi model bahasa dengan memanfaatkan kekuatan generatif model bahasa.
Lihat example/academic_paper_scripts/detxoify_lm/README.md untuk tutorial langkah demi langkah tentang cara melakukan pelatihan adaptif domain dan mendetoksifikasi LM menggunakan korpus yang dihasilkan sendiri.
Kami menyertakan contoh skrip untuk evaluasi GPT pada evaluasi kebingungan WikiTeks dan akurasi LAMBADA Cloze.
Bahkan untuk perbandingan dengan karya sebelumnya, kami mengevaluasi kebingungan pada kumpulan data pengujian WikiText-103 tingkat kata, dan menghitung kebingungan dengan tepat mengingat perubahan token saat menggunakan tokenizer subkata kami.
Kami menggunakan perintah berikut untuk menjalankan evaluasi WikiText-103 pada model parameter 345M.
TUGAS="WIKITEXT103"
VALID_DATA=<jalur teks wiki>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=pos pemeriksaan/gpt2_345m
COMMON_TASK_ARGS="--angka-lapisan 24
--ukuran tersembunyi 1024
--jumlah-perhatian-kepala 16
--seq-panjang 1024
--max-posisi-penyematan 1024
--fp16
--file vocab $VOCAB_FILE"
tugas python/main.py
--tugas $TUGAS
$COMMON_TASK_ARGS
--data-valid $VALID_DATA
--tipe tokenizer GPT2BPETokenizer
--gabungan-file $MERGE_FILE
--muat $CHECKPOINT_PATH
--ukuran mikro-batch 8
--log-interval 10
--tanpa beban-optim
--tanpa beban-rng
Untuk menghitung akurasi cloze LAMBADA (keakuratan prediksi token terakhir berdasarkan token sebelumnya) kami menggunakan versi set data LAMBADA yang telah didetokenisasi dan diproses.
Kami menggunakan perintah berikut untuk menjalankan evaluasi LAMBADA pada model parameter 345M. Perhatikan bahwa tanda --strict-lambada harus digunakan untuk mewajibkan pencocokan seluruh kata. Pastikan lambada adalah bagian dari jalur file.
TUGAS="LAMBADA"
VALID_DATA=<jalur lambada>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=pos pemeriksaan/gpt2_345m
COMMON_TASK_ARGS=<sama seperti yang ada di Evaluasi Kebingungan WikiTeks di atas>
tugas python/main.py
--tugas $TUGAS
$COMMON_TASK_ARGS
--data-valid $VALID_DATA
--tipe tokenizer GPT2BPETokenizer
--ketat-lambada
--gabungan-file $MERGE_FILE
--muat $CHECKPOINT_PATH
--ukuran mikro-batch 8
--log-interval 10
--tanpa beban-optim
--tanpa beban-rng
Argumen baris perintah lebih lanjut dijelaskan dalam file sumber main.py
Skrip berikut menyempurnakan model BERT untuk evaluasi pada kumpulan data RACE. Direktori TRAIN_DATA dan VALID_DATA berisi kumpulan data RACE sebagai file .txt terpisah. Perhatikan bahwa untuk RACE, ukuran batch adalah jumlah kueri RACE yang akan dievaluasi. Karena setiap kueri RACE memiliki empat sampel, ukuran batch efektif yang melewati model akan menjadi empat kali ukuran batch yang ditentukan pada baris perintah.
TRAIN_DATA="data/RACE/kereta/tengah"
VALID_DATA="data/RACE/dev/tengah
data/RACE/dev/tinggi"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=pos pemeriksaan/bert_345m
CHECKPOINT_PATH=pos pemeriksaan/bert_345m_race
COMMON_TASK_ARGS="--angka-lapisan 24
--ukuran tersembunyi 1024
--jumlah-perhatian-kepala 16
--seq-panjang 512
--max-posisi-penyematan 512
--fp16
--file vocab $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--kereta-data $TRAIN_DATA
--data-valid $VALID_DATA
--pos pemeriksaan yang telah dilatih sebelumnya $PRETRAINED_CHECKPOINT
--interval simpanan 10.000
--simpan $CHECKPOINT_PATH
--log-interval 100
--eval-interval 1000
--eval-iters 10
--peluruhan berat 1,0e-1"
tugas python/main.py
--tugas BALAP
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tipe tokenizer BertWordPieceLowerCase
--zaman 3
--ukuran batch mikro 4
--lr 1.0e-5
--lr-pemanasan-fraksi 0,06
Skrip berikut menyempurnakan model BERT untuk evaluasi dengan korpus pasangan kalimat MultiNLI. Karena tugas pencocokannya sangat mirip, skrip dapat dengan cepat diubah agar berfungsi dengan kumpulan data Quora Question Pairs (QQP).
TRAIN_DATA="data/glue_data/MNLI/train.tsv"
Valid_data = "data/glue_data/mnli/dev_matched.tsv
data/glue_data/mnli/dev_mishatched.tsv "
Pretrained_checkpoint = pos pemeriksaan/bert_345m
Vocab_file = bert-vocab.txt
Checkpoint_path = CHECKPOINTS/BERT_345M_MNLI
Common_task_args = <sama dengan yang ada dalam evaluasi balapan di atas>
Common_task_args_ext = <sama dengan yang ada dalam evaluasi ras di atas>
Tugas Python/main.py
--task mnli
$ Common_task_args
$ Common_task_args_ext
-Tokenizer BertwordPieceLowerCase
--epochs 5
--micro-batch-ukuran 8
--LR 5.0E-5
---lr-warmup-fraction 0,065
Keluarga model LLAMA-2 adalah serangkaian model open-source dari model pretrained & finetuned (untuk obrolan) yang telah mencapai hasil yang kuat di berbagai tolok ukur. Pada saat rilis, model LLAMA-2 mencapai di antara hasil terbaik untuk model open-source, dan kompetitif dengan model GPT-Sumber tertutup (lihat https://arxiv.org/pdf/2307.09288.pdf).
Pos pemeriksaan LLAMA-2 dapat dimuat ke megatron untuk inferensi dan finetuning. Lihat dokumentasi di sini.
Keluarga GPTModel Megatron-Core (Mcore) mendukung algoritma kuantisasi canggih dan inferensi kinerja tinggi melalui Tensorrt-llm.
Lihat optimasi dan penyebaran model Megatron untuk contoh llama2 dan nemotron3 .
Kami tidak meng -host dataset apa pun untuk pelatihan GPT atau BerT, namun, kami merinci koleksi mereka sehingga hasil kami dapat direproduksi.
Kami sarankan mengikuti proses ekstraksi data Wikipedia yang ditentukan oleh Google Research: "Pra-pemrosesan yang disarankan adalah mengunduh dump terbaru, mengekstrak teks dengan wikiextractor.py, dan kemudian menerapkan pembersihan yang diperlukan untuk mengubahnya menjadi teks biasa."
Kami merekomendasikan menggunakan argumen --json saat menggunakan wikiextractor, yang akan membuang data Wikipedia ke dalam format JSON longgar (satu objek JSON per baris), membuatnya lebih mudah dikelola pada sistem file dan juga mudah dikonsumsi oleh basis kode kami. Kami merekomendasikan preprocessing lebih lanjut dataset JSON ini dengan standardisasi tanda baca NLTK. Untuk pelatihan Bert, gunakan flag --split-sentences ke preprocess_data.py seperti dijelaskan di atas untuk memasukkan istirahat kalimat dalam indeks yang diproduksi. Jika Anda ingin menggunakan data Wikipedia untuk pelatihan GPT, Anda masih harus membersihkannya dengan NLTK/Spacy/FTFY, tetapi jangan gunakan bendera- --split-sentences .
Kami menggunakan Perpustakaan OpenWebtext yang tersedia untuk umum dari karya JCPeterson dan Eukaryote31 untuk mengunduh URL. Kami kemudian memfilter, membersihkan, dan mendeduplikasi semua konten yang diunduh sesuai dengan prosedur yang dijelaskan dalam direktori OpenWebText kami. Untuk URL Reddit yang sesuai dengan konten hingga Oktober 2018 kami tiba di sekitar 37GB konten.
Pelatihan Megatron dapat direproduksi bitwise; Untuk mengaktifkan penggunaan mode ini --deterministic-mode . Ini berarti bahwa konfigurasi pelatihan yang sama berjalan dua kali dalam lingkungan HW dan SW yang sama harus menghasilkan pos pemeriksaan model yang identik, kerugian dan nilai metrik akurasi (metrik waktu iterasi dapat bervariasi).
Saat ini ada tiga optimisasi megatron yang diketahui yang merusak reproduktifitas sementara masih menghasilkan pelatihan yang hampir identik:
NCCL_ALGO ) adalah penting. Kami telah menguji yang berikut: ^NVLS , Tree , Ring , CollnetDirect , CollnetChain . Kode mengakui penggunaan ^NVLS , yang memungkinkan NCCL pilihan algoritma non-NVLS; Pilihannya tampaknya stabil.--use-flash-attn .NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 .Selain itu, determINISIM hanya diverifikasi dalam wadah pytorch NGC hingga dan lebih baru dari 23,12. Jika Anda mengamati nondeterminisme dalam pelatihan Megatron dalam keadaan lain, buka masalah.
Di bawah ini adalah beberapa proyek di mana kami secara langsung menggunakan megatron:


