Oleh Buqian Zheng(buqianz) dan Yongkang Huang(yongkan1)
Poster
Kami menerapkan Corgy, kerangka pembelajaran mendalam di Swift dan Metal. Corgy dapat disematkan ke dalam aplikasi macOS dan iOS dan digunakan untuk membangun jaringan saraf terlatih dan mengevaluasinya dengan mudah. Kami mencapai kecepatan lebih dari 60x pada perangkat berbeda dengan GPU berbeda.

Kerangka kerja Metal 2 adalah antarmuka yang disediakan oleh Apple yang menyediakan akses hampir langsung ke unit pemrosesan grafis (GPU) di iPhone/iPad dan Mac. Selain grafik, Metal 2 menggabungkan banyak perpustakaan yang memberikan dukungan paralelisasi yang sangat baik untuk operasi aljabar linier yang diperlukan dan fungsi pemrosesan sinyal yang mampu berjalan di berbagai jenis perangkat Apple. Pustaka ini memungkinkan kami membangun model pembelajaran mendalam dengan akselerasi GPU yang diimplementasikan dengan baik pada perangkat iOS berdasarkan model terlatih yang diberikan oleh kerangka kerja lain. 1
Secara umum, tahap inferensi jaringan saraf terlatih memerlukan komputasi yang sangat intensif, terutama untuk model yang memiliki jumlah lapisan yang sangat banyak atau diterapkan dalam skenario yang diperlukan untuk memproses gambar beresolusi tinggi. Perlu diperhatikan bahwa ada banyak sekali komputasi matriks (misalnya lapisan konvolusional) yang sesuai untuk menerapkan operasi paralel guna mengoptimalkan kinerja.
Tantangan pertama yang kami hadapi adalah merancang abstraksi antarmuka pemrograman aplikasi yang ekspresif, mudah digunakan dengan kurva pembelajaran rendah yang mudah digunakan oleh pengguna kami.
Selama seluruh proses pengembangan, kami mencoba upaya terbaik untuk menjaga API publik sesederhana mungkin, sambil menggunakan semua properti yang diperlukan untuk membuat setiap komponen yang diminta dengan memanfaatkan mekanisme pemrograman fungsional yang disediakan oleh Swift. Kami juga sengaja menyembunyikan abstraksi perangkat keras yang tidak perlu yang disediakan oleh Metal untuk memperlancar kurva pembelajaran.
Meskipun model terlatih dari berbagai jaringan mudah diperoleh di Internet, heterogenitas di antara model tersebut yang disebabkan oleh implementasi berbeda yang menerapkan berbagai jenis alat memerlukan upaya untuk menciptakan importir model universal.
Beberapa komputasi mudah dipahami dari konsepnya tetapi memerlukan pemikiran yang cermat ketika Anda ingin membuat implementasi yang efektif dengan mengabstraksikannya. Konvolusi adalah contoh yang representatif.
Properti intrinsik dari operasi konvolusi tidak memiliki lokalitas yang baik, implementasi vanilla sulit dipahami dan tidak efektif dengan perulangan for yang rumit. Selain itu, kita perlu mempertimbangkan abstraksi yang disediakan oleh Metal 2 dan menciptakan cara mudah untuk berbagi informasi dan struktur data yang diperlukan antara host dan perangkat dengan mempertimbangkan representasi data dan tata letak memori secara cermat.
Selama fase pengembangan, kami berhati-hati saat menangani kemampuan kode kami yang berjalan normal di macOS dan iOS tanpa kompromi dalam performa di kedua platform. Kami mencoba upaya terbaik untuk mempertahankan pustaka kode yang mampu dikompilasi dan dieksekusi di kedua platform. Kami berhati-hati untuk memaksimalkan kode yang dibagikan antara target yang berbeda dan menggunakan kembali kode tersebut sebanyak mungkin.
Karena komponen lapisan jaringan saraf yang diimplementasikan sepenuhnya harus memberikan dukungan dengan jumlah parameter yang wajar sehingga membuat komponen tersebut cukup dapat digunakan, kompleksitas komponen sebenarnya cukup mengesankan. Misalnya, lapisan konvolusional harus mendukung parameter yang menggabungkan padding, langkah dilatasi, dll dan semuanya harus dipertimbangkan dengan hati-hati saat melakukan paralelisasi untuk mencapai kinerja yang wajar. Kami membangun beberapa jaringan sederhana untuk melakukan uji regresi. Kasus uji dibuat di kerangka lain (terutama PyTorch dan Keras) untuk memastikan bahwa semua implementasi berfungsi dengan benar.
Swift pertama kali dikembangkan pada bulan Juli 2010 dan diterbitkan serta dijadikan sumber terbuka pada tahun 2014. Meskipun sudah hampir 4 tahun sejak diterbitkan, kurangnya perpustakaan yang berdampak masih menjadi masalah yang tidak dapat diabaikan. Beberapa alasan menyebabkan situasi ini, peran dominan Apple dan sifat cepat Swift yang berulang mungkin menjadi alasan fenomena ini. Beberapa perpustakaan yang penting bagi kami tidak cukup kuat atau berfungsi untuk kebutuhan kami, atau tidak dikelola dengan baik oleh masing-masing pengembang yang menciptakannya. Kami menghabiskan cukup banyak waktu untuk mengimplementasikan Variable kelas tensor yang berfungsi dengan baik untuk permintaan kami.
Selain itu, ini adalah alasan lain yang menghambat pengembangan parser model universal karena fungsi penanganan file dan string memiliki kemampuan yang sangat terbatas.
Selain itu, alat pengembangan dan debugging pada dasarnya terbatas pada Xcode, meskipun ada pilihan lain yang lebih umum bagi kami, Xcode masih merupakan alat standar de facto untuk pengembangan kami.
Untuk penyempurnaan kinerja perangkat seluler, Apple tidak memberikan spesifikasi perangkat keras terperinci untuk SoC mereka, nama pemasaran banyak digunakan oleh media dan sulit untuk menyimpulkan apa dampak sebenarnya dari fitur perangkat keras tertentu dan menyempurnakan kinerja penerapannya. .
Kami menggunakan bahasa pemrograman Swift, khususnya Swift 4.2 yang terbaru sejauh ini; Kerangka kerja Metal 2 dan beberapa fungsi perpustakaan disediakan oleh Metal Performance Shader (Pada dasarnya Fungsi Aljabar Linier). Meskipun Apple meluncurkan CoreML SDK pada musim semi 2017 yang menggabungkan beberapa dukungan untuk jaringan saraf konvolusional, kami tidak menggunakannya di Corgy untuk mendapatkan pengalaman berharga dalam mengembangkan implementasi lapisan jaringan yang diparalelkan dan menyediakan API yang ringkas dan intuitif dengan kegunaan yang baik dan kurva pembelajaran yang lancar bagi pengguna untuk memigrasikan model dari kerangka kerja lain dengan mudah.
Mesin target kami adalah semua perangkat yang menjalankan macOS dan iOS, seperti iMac, MacBook, iPhone, dan iPad. Secara khusus, perangkat dengan platform yang mendukung perpustakaan aljabar linier MPS (yaitu setelah iOS 10.0 dan macOS 10.13), yang berarti iPhone diluncurkan setelah iPhone 5, iPad diluncurkan setelah iPad (generasi ke-4), dan iPod Touch (generasi ke-6) didukung sebagai platform iOS. Lini produk Mac mendapatkan cakupan yang lebih luas, termasuk iMac yang diproduksi setelah akhir tahun 2009 atau lebih baru, semua Seri MacBook yang diluncurkan setelah pertengahan tahun 2010, dan iMac Pro.
Abstraksi paralel Metal 2 sangat mirip dengan CUDA: ketika mengirimkan pass komputer ke GPU, pemrogram pertama-tama akan menulis fungsi kernel yang akan dieksekusi oleh setiap thread, kemudian menentukan jumlah grup thread (alias blok di CUDA) di grid dan jumlah thread di setiap grup thread, Metal akan mengeksekusi kernel di atas grid ini, kernel diimplementasikan dalam dialek C++14 bernama bahasa shading Metal. Di dalam setiap grup thread, terdapat unit yang lebih kecil yang disebut grup SIMD, artinya sekumpulan thread yang berbagi instruksi SIMD yang sama. Namun dalam penerapan kami, hal ini tidak perlu dipertimbangkan.
Metal menyediakan API bernama MTLCommandBuffer yang menyimpan perintah yang disandikan yang dikomit dan dijalankan oleh GPU. Setiap kali kita ingin meluncurkan tugas yang akan dilakukan oleh GPU, fungsi kernel yang telah dikompilasi akan dikodekan ke dalam instruksi GPU, ditanamkan ke dalam pipeline Metal shading dan dikirim ke MTLCommandBuffer. Buffer logam yang digunakan untuk menyimpan parameter komputasi yang perlu diteruskan ke perangkat juga diatur pada tahap ini. Kemudian dengan jumlah grup thread dan thread per grup yang ditentukan, perintah yang ditangani oleh buffer perintah akan sepenuhnya dikodekan dan siap untuk dikomit ke perangkat. GPU akan menjadwalkan tugas dan memberi tahu thread CPU yang mengirimkan pekerjaan setelah eksekusi selesai.
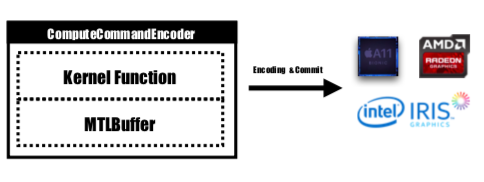
Fungsi kernel akan dikodekan oleh MTLComputeCommandEncoder dan tugas akan dibuat untuk semua platform yang didukung.
Dalam implementasi kami, kami banyak menggunakan cara intuitif untuk memetakan elemen ke dalam thread GPU: memetakan setiap elemen dalam tensor output lapisan saat ini ke satu thread GPU: setiap thread menghitung dan memperbarui tepat satu elemen output, dan inputnya akan menjadi read-only, jadi kita tidak perlu khawatir tentang sinkronisasi antar thread. Di bawah pemetaan ini, thread dengan id berkelanjutan mungkin membaca data masukan dari lokasi memori berbeda tetapi akan selalu menulis ke lokasi memori berkelanjutan. Jadi tidak akan ada operasi pencar ketika grup SIMD sedang menulis ke memori.
Kami merancang Variable kelas tensor sebagai dasar dari semua implementasi, kami memanfaatkan dan merangkum operasi aljabar linier ke dalam kelas Variable alih-alih menulis kernel tambahan untuk mendalami operasi yang bukan fokus utama kami untuk mengurangi kompleksitas implementasi dan menghemat waktu kita untuk fokus mempercepat lapisan jaringan.
1. Ubah konvolusi menjadi perkalian matriks raksasa
Kami mengumpulkan data dari masukan secara paralel untuk membentuk matriks raksasa dari variabel masukan dan bobot. Kami menyimpan bobot setiap lapisan konvolusional dalam cache untuk menghindari penghitungan ulang. Padding lapisan konvolusional akan dihasilkan selama transformasi paralelisasi selama penghitungan, kemudian kita memanggil MPSMatrixMultiply ke matriks raksasa dan mengubah data dari matriks raksasa kembali ke kelas tensor normal yang kita buat. Metode ini dijelaskan dalam slide kelas.
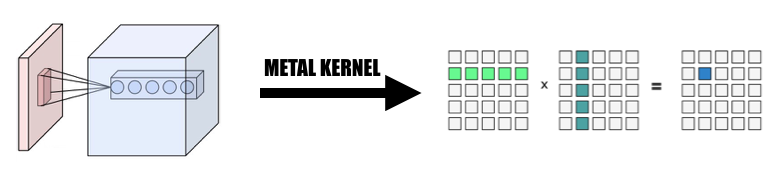
2. Desain dan implementasi kelas Variabel
Kelas variabel adalah dasar implementasi kami sebagai representasi tensor. Kami merangkum MPSMatrixMultiplication untuk variabel (mendefinisikan tanda perkalian Unicode (×) sebagai operator infiks untuk merepresentasikannya dengan elegan :-)).
Struktur data yang mendasari variabel adalah UnsafemutableBufferPointer yang menunjuk ke tipe data, kami memilih Float 32-bit untuk kesederhanaan. Kelas Variable mempertahankan dua ukuran data, count berisi nomor elemen yang sebenarnya disimpan, actualCount adalah ukuran semua elemen yang dibulatkan ke atas ke ukuran halaman platform yang diperoleh dengan menggunakan getpagesize() .
Kami mempertahankan kedua nilai ini untuk memastikan makeBuffer(bytesNoCopy:) membuat buffer langsung di wilayah VM yang ditentukan dan menghindari realokasi berlebihan yang mengurangi overhead. Jika memori yang akan diteruskan ke Metal tidak selaras halamannya, maka Metal tidak akan dapat menggunakan memori ini sebagai buffer input atau output. Kita harus menggunakan metode makeBuffer(bytes:) , yang akan membuat buffer baru dan menyalin data dari lokasi memori input. Jadi kita selalu perlu mengalokasikan lebih banyak memori daripada yang diperlukan untuk memastikan semua memori di Variable selaras halamannya. Jadi kita memerlukan dua nilai untuk melacak seberapa besar sebenarnya potongan memori ini dan seberapa besar yang harus kita gunakan.
3. Jumlah elemen yang diproses oleh satu thread
Kami mencoba memetakan satu thread ke beberapa elemen, dari 2 hingga 16 elemen per thread, kinerjanya hampir sama tetapi banyak kompleksitas yang ditambahkan ke proyek kami, jadi kami membuang pendekatan ini.
Semua versi CPU yang disebutkan di bawah ini adalah kode CPU single-threaded yang naif tanpa optimasi SIMD. Optimasi kompiler pada level -Ofast diterapkan.
Kinerja implementasi kami sudah bagus, belum cukup baik.
Kami menggunakan iPhone 6s dan MacBook Pro 15 inci sebagai platform benchmark. Perangkat keras ditentukan di bawah ini:
MacBook Pro (Retina 15 inci, Pertengahan 2015)
iPhone 6S
Dibandingkan dengan implementasi versi CPU yang naif tanpa paralelisme, versi GPU kami 60x lebih cepat .
Karena model MNIST terlalu kecil, hasilnya mungkin tidak mencerminkan percepatan yang akurat. Dan kami tidak memiliki versi single-thread yang diimplementasikan dengan baik, kami tidak dapat memberikan angka percepatan yang akurat. Karena versi CPU terlalu lambat, kecepatan pada Tiny YOLO terlalu besar untuk dipercaya.
Atribut jaringan eksperimen:
MNIST:
YOLO:
Hasil pengukuran:
| iPhone 6s | MNIST | YOLO kecil |
|---|---|---|
| CPU | 1500 ms | 753-an |
| GPU | 0,025 detik | 0,5 detik |
| mempercepat | ~60x | ~1500x |
| Macbook pro | MNIST | YOLO kecil |
|---|---|---|
| CPU | 650 md | 729-an |
| GPU | 10 md | 0,028 detik |
| mempercepat | ~65x | ~26000x |
Berdasarkan tolok ukur di atas kita dapat melihat bahwa seiring dengan bertambahnya ukuran masalah,
Mengapa kami mengatakan kecepatan kami kurang baik? Karena jika dibandingkan dengan implementasi MPSCNNConvolution resmi Apple, kecepatan kami hanya sepertiga, yang berarti masih banyak ruang pengoptimalan. Perbandingan ini didasarkan pada implementasi open source YOLO di iPhone menggunakan MPSCNNConvolution resmi yang dapat mengenali ~5 gambar per detik sedangkan implementasi kami hanya dapat mencapai ~2 gambar per detik.
Dan karena waktu yang terbatas, kami tidak dapat membuat versi dasar dan versi paralel CPU yang lebih baik untuk melakukan benchmark, sehingga angka kecepatannya menjadi terlalu besar.
Juga layak untuk melaporkan peningkatan kinerja pada ukuran masalah yang berbeda. Seperti yang bisa kita lihat, MNIST hanya memiliki 0,1 juta bobot sedangkan Tiny YOLO memiliki 17 juta. Tiny YOLO jauh lebih kompleks daripada MNIST tetapi waktu berjalan versi GPU tidak terlalu besar. Hal ini sekali lagi disebabkan oleh hukum Amdahl. Setiap tugas GPU diluncurkan, perintah GPU yang sesuai perlu dikodekan ke dalam buffer perintah. Proses ini pada dasarnya bersifat serial. Ketika ukuran masalahnya kecil, proses ini berkontribusi banyak terhadap total waktu berjalan, sehingga dengan memparalelkan tahap inferensi jaringan saraf di MINST mungkin tidak mendapatkan kecepatan yang sama seperti di Tiny YOLO, di mana overhead waktu berjalan dapat diabaikan.
Apa yang membatasi kecepatan Anda?
if s dan for s yang mungkin menyebabkan perbedaan, sehingga menyebabkan pemanfaatan SIMD yang buruk.Analisis Lebih Dalam: perincian waktu eksekusi dari fase yang berbeda.
Ambil Tiny YOLO sebagai contoh, dalam sampel yang dijalankan dengan total waktu berjalan 227 mdtk di Macbook, lapisan konvolusional menggunakan 207 md, 92% dari total waktu berjalan. Lapisan Pooling menggunakan 14ms(6%), dan ReLU menggunakan 6ms(2%). Menurut hukum Amdahl, jika kita ingin lebih meningkatkan kinerja, kita harus terus mengerjakan lapisan konvolusional.
Secara keseluruhan, Kami yakin bahwa pilihan kerangka Logam kami untuk melakukan akselerasi Jaringan Neural pada perangkat iOS dan macOS adalah pilihan yang tepat, terutama untuk perangkat iOS. Karena core-nya lebih sedikit, bahkan dengan instruksi SIMD, versi CPU yang disetel dengan baik cenderung tidak mendapatkan performa serupa dengan versi GPU.
Pekerjaan yang sama dilakukan oleh kedua anggota tim.
1 https://developer.apple.com/metal/ ↩
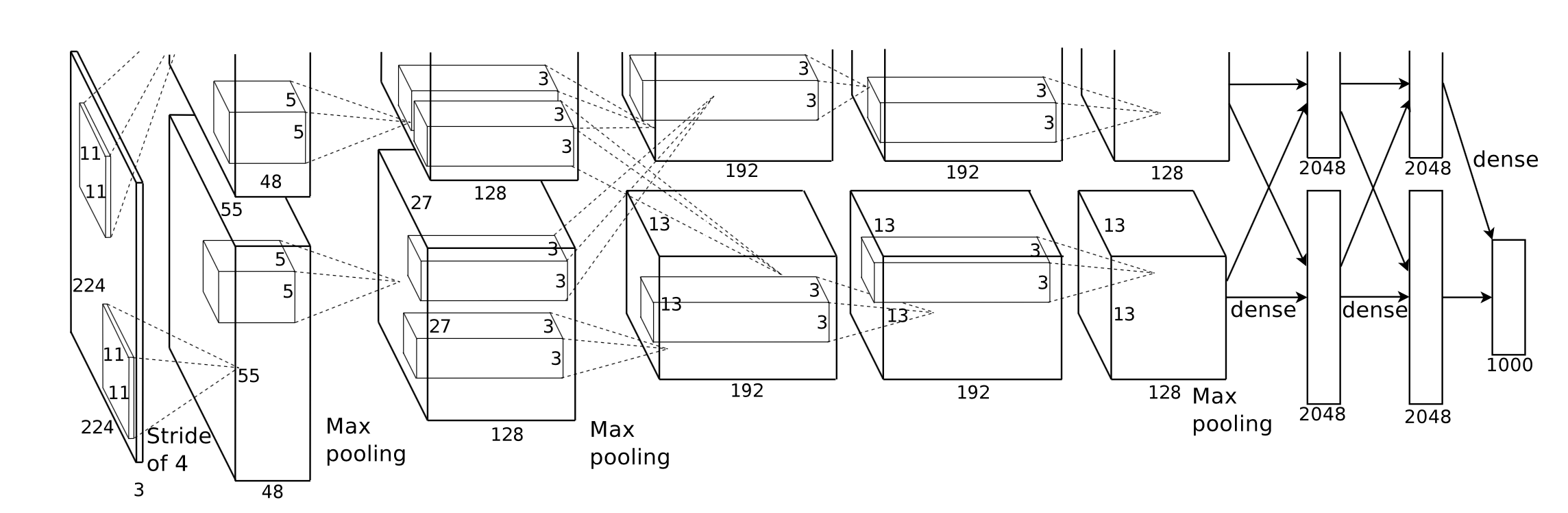
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


