Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript ?Browser Tanpa KepalaMengikis sebagian besar situs web mungkin relatif mudah. Topik ini sudah dibahas panjang lebar dalam tutorial ini. Namun, ada banyak situs yang tidak dapat dikikis menggunakan metode yang sama. Alasannya adalah situs-situs tersebut memuat konten secara dinamis menggunakan JavaScript.
Teknik ini juga dikenal dengan nama AJAX (Asynchronous JavaScript and XML). Secara historis, standar ini disertakan dalam pembuatan objek XMLHttpRequest untuk mengambil XML dari server web tanpa memuat ulang seluruh halaman. Saat ini, benda tersebut jarang digunakan secara langsung. Biasanya, wrapper seperti jQuery digunakan untuk mengambil konten seperti JSON, sebagian HTML, atau bahkan gambar.
Untuk mengikis halaman web biasa, setidaknya diperlukan dua perpustakaan. Perpustakaan requests mengunduh halaman tersebut. Setelah halaman ini tersedia sebagai string HTML, langkah selanjutnya adalah menguraikannya sebagai objek BeautifulSoup. Objek BeautifulSoup ini kemudian dapat digunakan untuk mencari data tertentu.
Berikut adalah contoh skrip sederhana yang mencetak teks di dalam elemen h1 dengan id disetel ke firstHeading .
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert EinsteinPerhatikan bahwa kami sedang bekerja dengan versi 4 dari perpustakaan Beautiful Soup. Versi sebelumnya dihentikan. Anda mungkin melihat sup cantik 4 ditulis hanya sebagai Sup Cantik, Sup Cantik, atau bahkan bs4. Semuanya mengacu pada perpustakaan sup 4 indah yang sama.
Kode yang sama tidak akan berfungsi jika situsnya dinamis. Misalnya, situs yang sama memiliki versi dinamis di https://quotes.toscrape.com/js/ (catatan js di akhir URL ini).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output Alasannya adalah situs kedua bersifat dinamis dimana data dihasilkan menggunakan JavaScript .
Ada dua cara untuk menangani situs seperti ini.
Kedua pendekatan ini dibahas panjang lebar dalam tutorial ini.
Namun, pertama-tama, kita perlu memahami cara menentukan apakah suatu situs bersifat dinamis.
Berikut cara termudah untuk menentukan apakah suatu situs web dinamis menggunakan Chrome atau Edge. (Kedua browser ini menggunakan Chromium).
Buka Alat Pengembang dengan menekan tombol F12 . Pastikan fokusnya ada pada alat Pengembang dan tekan kombinasi tombol CTRL+SHIFT+P untuk membuka Menu Perintah.
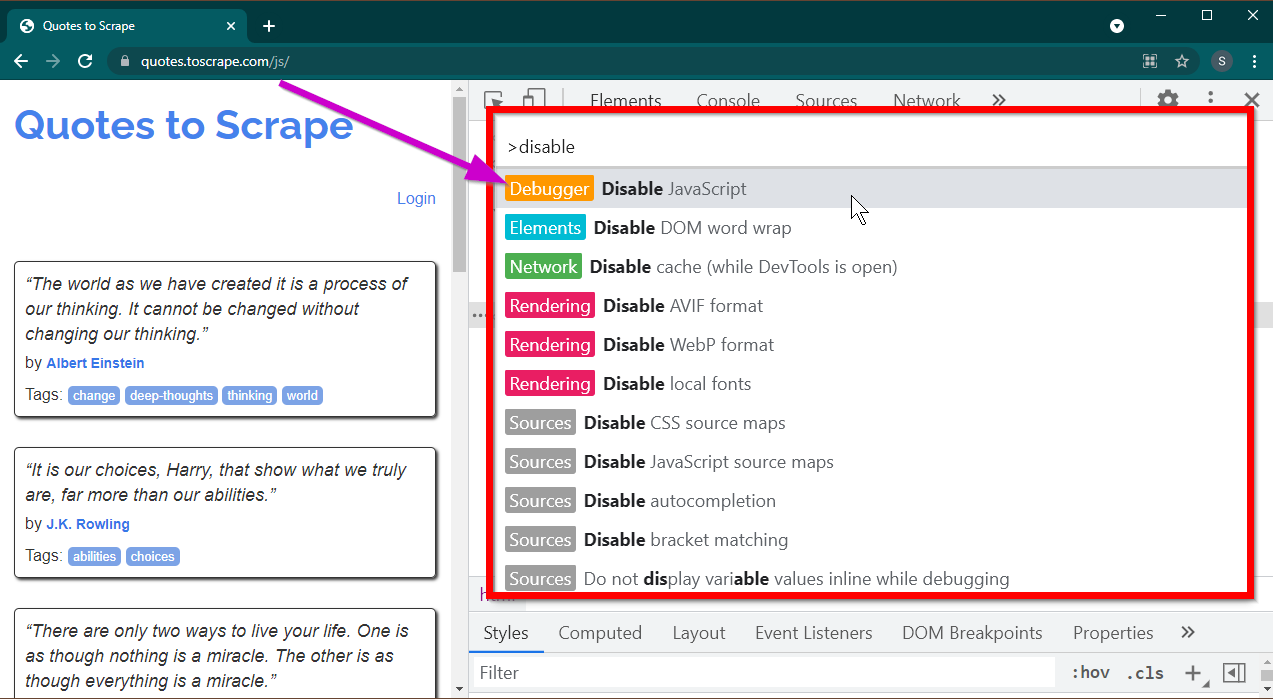
Ini akan menampilkan banyak perintah. Mulailah mengetik disable dan perintah akan difilter untuk menampilkan Disable JavaScript . Pilih opsi ini untuk menonaktifkan JavaScript .
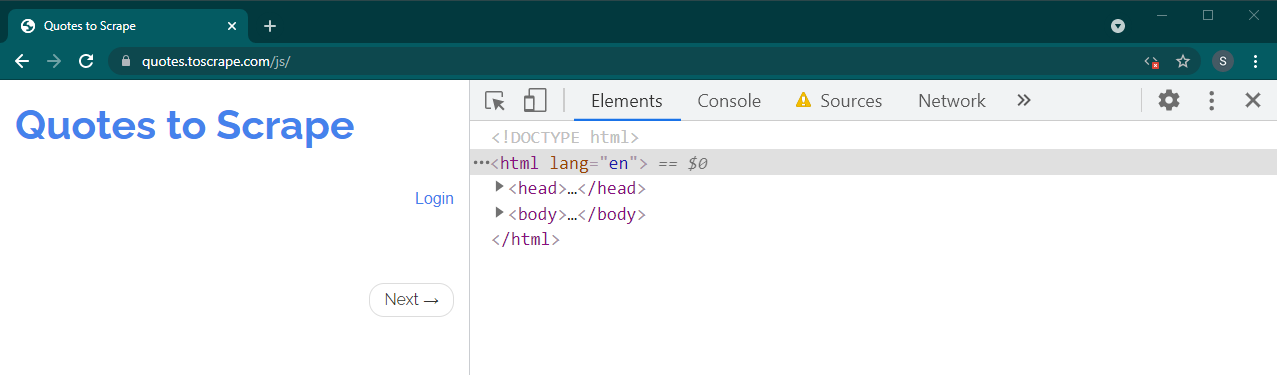
Sekarang muat ulang halaman ini dengan menekan Ctrl+R atau F5 . Halaman akan dimuat ulang.
Jika ini adalah situs dinamis, banyak konten yang akan hilang:
Dalam beberapa kasus, situs akan tetap menampilkan data tetapi akan kembali ke fungsi dasar. Misalnya, situs ini memiliki gulir yang tidak terbatas. Jika JavaScript dinonaktifkan, ini akan menampilkan penomoran halaman reguler.
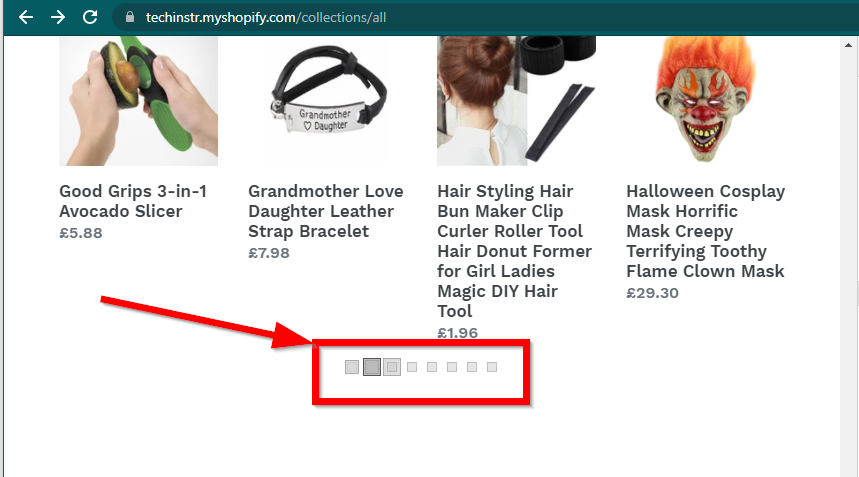 | 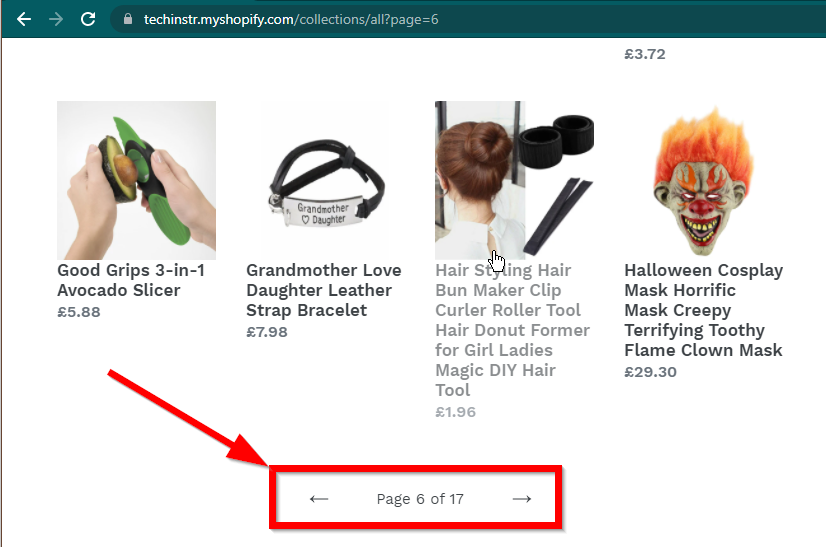 |
|---|---|
| JavaScript Diaktifkan | JavaScript Dinonaktifkan |
Pertanyaan selanjutnya yang perlu dijawab adalah kemampuan BeautifulSoup.
JavaScript ?Jawaban singkatnya adalah tidak.
Penting untuk memahami kata-kata seperti parsing dan rendering. Parsing hanyalah mengubah representasi string dari objek Python menjadi objek sebenarnya.
Jadi apa itu Rendering? Render pada dasarnya menafsirkan HTML, JavaScript, CSS, dan gambar menjadi sesuatu yang kita lihat di browser.
Beautiful Soup adalah perpustakaan Python untuk menarik data dari file HTML. Ini melibatkan penguraian string HTML ke dalam objek BeautifulSoup. Untuk parsing, pertama-tama kita memerlukan HTML sebagai string. Situs web dinamis tidak memiliki data dalam HTML secara langsung. Artinya BeautifulSoup tidak dapat bekerja dengan situs web dinamis.
Pustaka Selenium dapat mengotomatiskan pemuatan dan rendering situs web di browser seperti Chrome atau Firefox. Meskipun Selenium mendukung penarikan data dari HTML, dimungkinkan untuk mengekstrak HTML lengkap dan menggunakan Beautiful Soup untuk mengekstrak data.
Mari kita mulai web scraping dinamis dengan Python menggunakan Selenium terlebih dahulu.
Menginstal Selenium melibatkan menginstal tiga hal:
Browser pilihan Anda (yang sudah Anda miliki):
Driver untuk browser Anda:
Paket Python Selenium:
pip install seleniumconda-forge . conda install -c conda-forge selenium Kerangka dasar skrip Python untuk meluncurkan browser, memuat halaman, dan kemudian menutup browser sangatlah sederhana:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()Sekarang kita dapat memuat halaman di browser, mari kita lihat cara mengekstraksi elemen tertentu. Ada dua cara untuk mengekstrak unsur—Selenium dan Sup Cantik.
Tujuan kami dalam contoh ini adalah menemukan elemen penulis.
Muat situs https://quotes.toscrape.com/js/ di Chrome, klik kanan nama pembuatnya, dan klik Inspect. Ini harus memuat Alat Pengembang dengan elemen penulis yang disorot sebagai berikut:
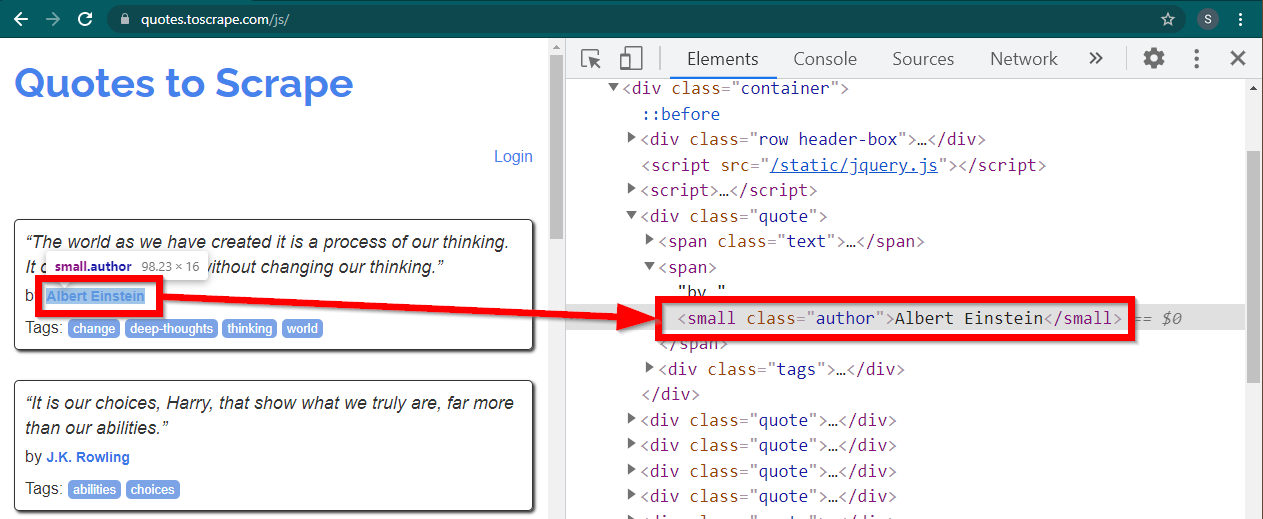
Ini adalah elemen small dengan atribut class disetel ke author .
< small class =" author " > Albert Einstein </ small >Selenium memungkinkan berbagai metode untuk menemukan elemen HTML. Metode-metode ini adalah bagian dari objek driver. Beberapa metode yang mungkin berguna di sini adalah sebagai berikut:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )Ada beberapa metode lain, mungkin berguna untuk skenario lain. Cara-cara tersebut adalah sebagai berikut:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) Mungkin metode yang paling berguna adalah find_element(By.CSS_SELECTOR) dan find_element(By.XPATH) . Salah satu dari dua metode ini harus dapat memilih sebagian besar skenario.
Mari kita modifikasi kodenya agar penulis pertama dapat dicetak.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()Bagaimana jika Anda ingin mencetak semua penulis?
Semua metode find_element memiliki padanannya - find_elements . Perhatikan pluralisasinya. Untuk menemukan semua penulis, cukup ubah satu baris:
elements = driver . find_elements ( By . CLASS_NAME , "author" )Ini mengembalikan daftar elemen. Kita cukup menjalankan loop untuk mencetak semua penulis:
for element in elements :
print ( element . text )Catatan: Kode lengkapnya ada di file kode Selenium_example.py.
Namun, jika Anda sudah nyaman dengan BeautifulSoup, Anda bisa membuat objek Beautiful Soup.
Seperti yang kita lihat pada contoh pertama, objek Beautiful Soup memerlukan HTML. Untuk situs statis web scraping, HTML dapat diambil menggunakan perpustakaan requests . Langkah selanjutnya adalah mengurai string HTML ini ke dalam objek BeautifulSoup.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )Yuk cari tahu cara mengikis website dinamis dengan BeautifulSoup.
Bagian berikut ini tetap tidak berubah dari contoh sebelumnya.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) HTML halaman yang dirender tersedia di atribut page_source .
soup = BeautifulSoup ( driver . page_source , "lxml" )Setelah objek sup tersedia, semua metode Sup Cantik dapat digunakan seperti biasa.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )Catatan: Kode sumber lengkap ada di Selenium_bs4.py
Browser Tanpa KepalaSetelah skrip siap, browser tidak perlu lagi terlihat saat skrip dijalankan. Browser bisa disembunyikan, dan script akan tetap berjalan dengan baik. Perilaku browser ini juga dikenal sebagai browser tanpa kepala.
Untuk menjadikan browser tanpa kepala, impor ChromeOptions . Untuk browser lain, tersedia kelas Opsinya sendiri.
from selenium . webdriver import ChromeOptions Sekarang, buat objek kelas ini, dan atur atribut headless ke True.
options = ChromeOptions ()
options . headless = TrueTerakhir, kirimkan objek ini saat membuat instance Chrome.
driver = Chrome ( ChromeDriverManager (). install (), options = options )Sekarang ketika Anda menjalankan skrip, browser tidak akan terlihat. Lihat file Selenium_bs4_headless.py untuk implementasi lengkap.
Memuat browser itu mahal—membutuhkan CPU, RAM, dan bandwidth yang sebenarnya tidak diperlukan. Saat sebuah situs web sedang di-scrap, datalah yang penting. Semua CSS, gambar, dan rendering tersebut tidak terlalu diperlukan.
Cara tercepat dan paling efisien untuk menyalin halaman web dinamis dengan Python adalah dengan menemukan lokasi sebenarnya di mana data tersebut berada.
Ada dua tempat di mana data ini dapat ditemukan:
<script>Mari kita lihat beberapa contoh.
Buka https://quotes.toscrape.com/js di Chrome. Setelah halaman dimuat, tekan Ctrl+U untuk melihat sumber. Tekan Ctrl+F hingga memunculkan kotak pencarian, cari Albert.
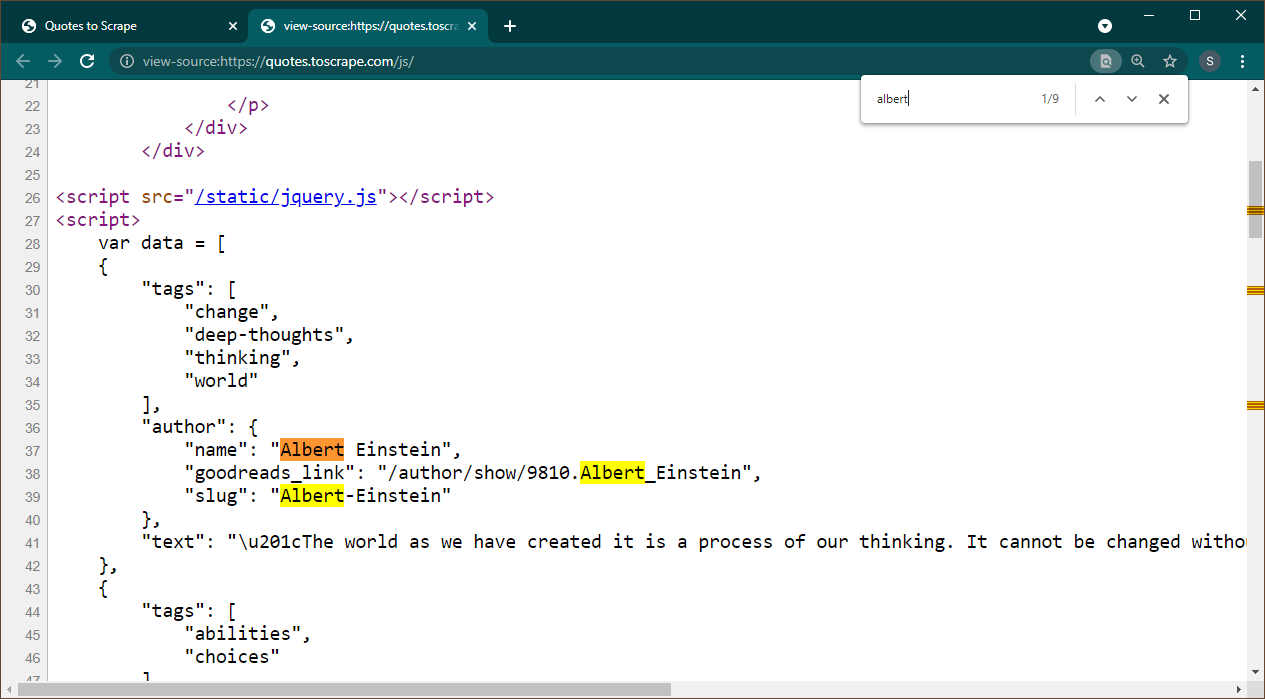
Kita dapat langsung melihat bahwa data tertanam sebagai objek JSON di halaman. Perhatikan juga bahwa ini adalah bagian dari skrip tempat data ini ditugaskan ke variabel data .
Dalam hal ini, kita bisa menggunakan perpustakaan Permintaan untuk mendapatkan halaman dan menggunakan Beautiful Soup untuk mengurai halaman dan mendapatkan elemen skrip.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) Perhatikan bahwa ada beberapa elemen <script> . Yang berisi data yang kita butuhkan tidak memiliki atribut src . Mari kita gunakan ini untuk mengekstrak elemen skrip.
script_tag = soup . find ( "script" , src = None )Ingatlah bahwa skrip ini berisi kode JavaScript lain selain data yang kami minati. Untuk alasan ini, kami akan menggunakan ekspresi reguler untuk mengekstrak data ini.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )Variabel data adalah daftar yang berisi satu item. Sekarang kita bisa menggunakan perpustakaan JSON untuk mengubah data string ini menjadi objek python.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )Outputnya adalah objek python:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................Daftar ini tidak dapat dikonversi ke format apa pun sesuai kebutuhan. Perhatikan juga bahwa setiap item berisi link ke halaman penulis. Artinya Anda dapat membaca tautan ini dan membuat laba-laba untuk mendapatkan data dari semua halaman ini.
Kode lengkap ini disertakan dalam data_in_same_page.py.
Situs dinamis pengikisan web dapat mengikuti jalur yang sangat berbeda. Terkadang data dimuat pada halaman terpisah sama sekali. Salah satu contohnya adalah Librivox.
Buka Alat Pengembang, buka Tab Jaringan dan filter berdasarkan XHR. Sekarang buka tautan ini atau cari buku apa saja. Anda akan melihat bahwa datanya adalah HTML yang tertanam di JSON.
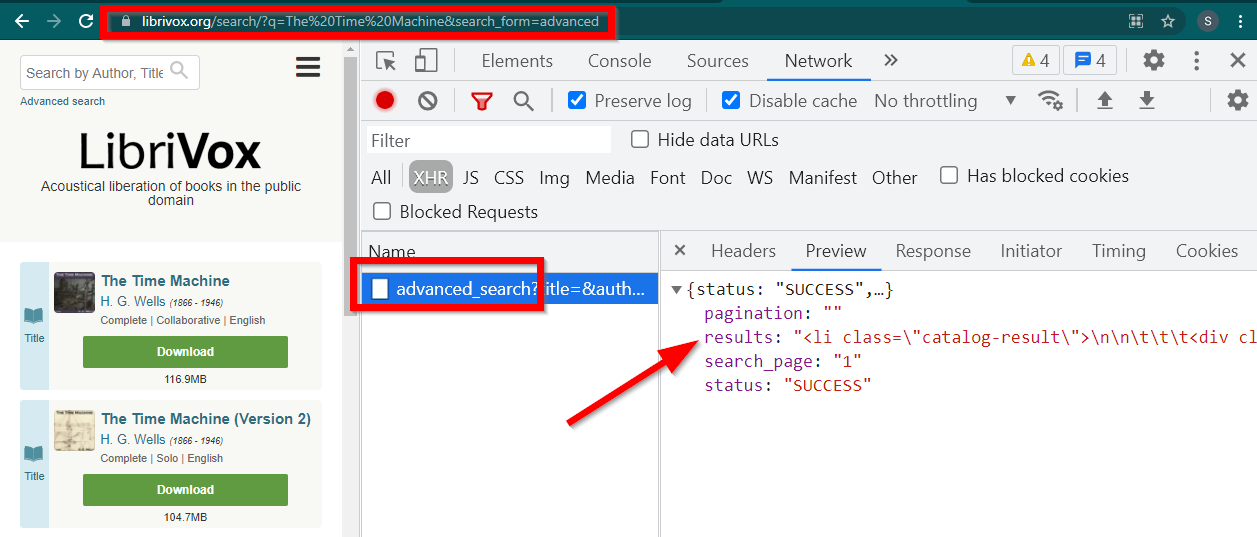
Perhatikan beberapa hal:
URL yang ditampilkan oleh browser adalah https://librivox.org/search/?q=...
Datanya ada di https://librivox.org/advanced_search?....
Jika Anda melihat header, Anda akan menemukan bahwa halaman advanced_search dikirimkan header khusus X-Requested-With: XMLHttpRequest
Berikut cuplikan untuk mengekstrak data ini:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )Kode lengkap disertakan dalam file librivox.py.


