disclosure backend static
1.0.0
Repo disclosure-backend-static adalah backend yang mendukung Open Disclosure California.
Hal ini dibuat dengan tergesa-gesa menjelang pemilu tahun 2016, dan dengan demikian direkayasa berdasarkan filosofi "selesaikan". Pada saat itu, kami telah merancang API dan membangun (sebagian besar) frontend; repo ini dibuat untuk mengimplementasikannya secepat mungkin.
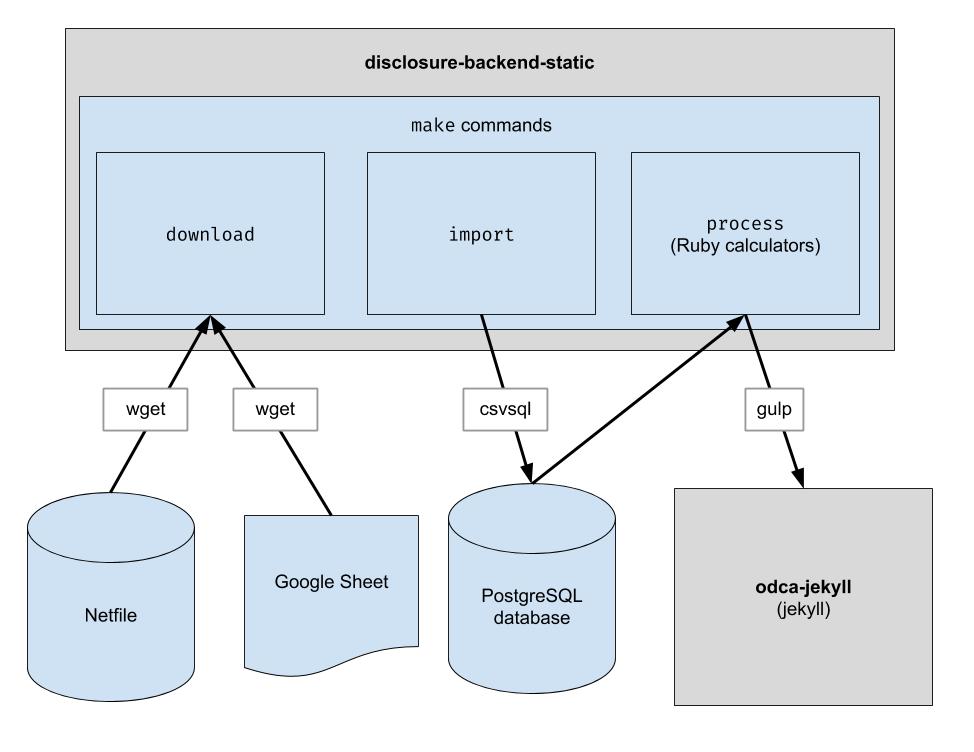
Proyek ini mengimplementasikan pipeline ETL dasar untuk mendownload data netfile Oakland, mendownload data CSV yang dikurasi manusia untuk Oakland, dan menggabungkan keduanya. Outputnya adalah direktori file JSON yang meniru struktur API yang ada sehingga tidak diperlukan perubahan kode klien.
.ruby-version ) Catatan: Anda tidak perlu menjalankan perintah ini untuk mengembangkan di frontend. Yang perlu Anda lakukan hanyalah mengkloning repositori yang berdekatan dengan repo frontend.
Jika Anda berencana mengubah kode backend, ikuti langkah-langkah berikut untuk menyiapkan semua dependensi pengembangan yang diperlukan, termasuk database PostgreSQL baru dan Python 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip alih-alih pip untuk memastikan Python 3 digunakan: python3 -m pip install ...
pip sistem Anda menunjuk ke Python 3, Anda dapat menggunakan pip secara langsung: pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
Repositori ini diatur untuk berfungsi dalam wadah di bawah Codespaces. Dengan kata lain, Anda dapat memulai lingkungan yang sudah diatur tanpa harus melakukan langkah-langkah instalasi apa pun yang diperlukan untuk menyiapkan lingkungan lokal. Ini dapat digunakan sebagai cara untuk memecahkan masalah kode sebelum diterapkan ke jalur produksi. Informasi berikut mungkin berguna untuk mulai menggunakan Codespaces:
Code dan klik tab Codespaces di dropdown/workspace ditampilkan di halaman web, yang akan terlihat familier jika Anda pernah bekerja dengan VS Code sebelumnyamake downloadpsql di terminal untuk terhubung ke servermake import akan mengisi database Postgresgit pushRepositori ini juga dikonfigurasi untuk dijalankan dalam kontainer Docker. Ini mirip dengan Codespaces kecuali Anda dapat menggunakan IDE dan pengaturan lokal apa pun yang Anda inginkan. Berikut cara mulai menggunakan Docker dengan VSCode:
Unduh file data mentah. Anda hanya perlu menjalankannya sesekali untuk mendapatkan data terbaru.
$ make download
Impor data ke dalam database untuk memudahkan pemrosesan. Anda hanya perlu menjalankan ini setelah Anda mengunduh data baru.
$ make import
Jalankan kalkulator. Semuanya ditampilkan ke folder "build".
$ make process
Secara opsional, indeks ulang keluaran build ke Algolia. (Pengindeksan ulang memerlukan variabel lingkungan ALGOLIASEARCH_APPLICATION_ID dan ALGOLIASEARCH_API_KEY).
$ make reindex
Jika Anda ingin menyajikan file JSON statis melalui server web lokal:
$ make run
Saat make import dijalankan, sejumlah tabel postgres dibuat untuk mengimpor data yang diunduh. Skema tabel ini didefinisikan secara eksplisit di direktori dbschema dan mungkin harus diperbarui di masa mendatang untuk mengakomodasi data di masa mendatang. Kolom yang menyimpan data string mungkin ukurannya tidak cukup besar untuk data selanjutnya. Misalnya, jika kolom nama menerima nama paling banyak 20 karakter dan di masa mendatang, kami memiliki data dengan panjang nama 21 karakter, impor data akan gagal. Jika ini terjadi, kita harus memperbarui file skema terkait di dbschema untuk mendukung lebih banyak karakter. Cukup lakukan perubahan dan jalankan kembali make import untuk memverifikasi bahwa itu berhasil.
Repositori ini digunakan untuk menghasilkan file data yang digunakan oleh website. Setelah make process dijalankan, direktori build dihasilkan berisi file data. Direktori ini dimasukkan ke dalam repositori dan kemudian diperiksa saat membuat situs web. Setelah melakukan perubahan kode, penting untuk membandingkan direktori build yang dihasilkan dengan direktori build yang dibuat sebelum kode diubah dan memverifikasi bahwa perubahan dari perubahan kode tersebut sesuai dengan yang diharapkan.
Karena perbandingan ketat terhadap seluruh konten direktori build akan selalu menyertakan perubahan yang terjadi secara independen dari perubahan kode apa pun, setiap pengembang harus mengetahui perubahan yang diharapkan ini agar dapat melakukan pemeriksaan ini. Untuk menghilangkan kebutuhan akan hal ini, file tertentu, bin/create-digests.py , menghasilkan intisari untuk data JSON di direktori build setelah mengecualikan perubahan yang diharapkan ini. Untuk mencari perubahan yang mengecualikan perubahan yang diharapkan ini, cukup cari perubahan di file build/digests.json .
Saat ini, berikut adalah perubahan yang diharapkan terjadi tanpa bergantung pada perubahan kode apa pun:
Perubahan yang diharapkan dikecualikan sebelum menghasilkan ringkasan data di direktori build . Logikanya dapat ditemukan di fungsi clean_data , ditemukan di file bin/create-digests.py . Setelah kode diubah sedemikian rupa sehingga perubahan yang diharapkan tidak ada lagi, pengecualian perubahan tersebut dapat dihapus dari clean_data . Misalnya, pembulatan pelampung tidak selalu sama setiap kali make process dijalankan, karena perbedaan lingkungan. Ketika kode diperbaiki sehingga pembulatan float sama selama datanya tidak berubah, panggilan round_float di clean_data dapat dihapus.
Skrip tambahan telah dibuat untuk menghasilkan laporan yang memungkinkan perbandingan total kandidat. Skripnya adalah bin/report-candidates.py dan menghasilkan build/candidates.csv dan build/candidates.xlsx . Laporan tersebut mencakup daftar semua kandidat dan total yang dihitung dengan berbagai cara sehingga jumlahnya harus sama.
Untuk memastikan bahwa perubahan skema database terlihat dalam permintaan tarik, skema postgres lengkap juga disimpan ke file schema.sql di direktori build . Karena direktori build secara otomatis dibangun kembali untuk setiap cabang di PR dan dikomit ke repositori, setiap perubahan pada skema yang disebabkan oleh perubahan kode akan menunjukkan perbedaan dalam file schema.sql saat meninjau PR.
Setiap metrik tentang seorang kandidat dihitung secara independen. Metriknya bisa berupa "total kontribusi yang diterima" atau sesuatu yang lebih kompleks seperti "persentase kontribusi yang kurang dari $100".
Saat menambahkan perhitungan baru, tempat pertama yang baik untuk memulai adalah Formulir 460 resmi. Apakah data yang Anda cari dilaporkan pada formulir tersebut? Jika demikian, Anda mungkin akan menemukannya di database Anda setelah proses impor. Ada juga beberapa form lain yang kita impor, seperti Form 496. (Ini adalah nama file di direktori input . Coba lihat.)
Setiap jadwal setiap formulir diimpor ke tabel postgres terpisah. Misalnya, Jadwal A Formulir 460 diimpor ke tabel A-Contributions .
Sekarang setelah Anda memiliki cara untuk menanyakan data, Anda harus membuat kueri SQL yang menghitung nilai yang ingin Anda dapatkan. Setelah Anda dapat mengekspresikan perhitungan Anda sebagai SQL, masukkan ke dalam file kalkulator seperti ini:
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID .candidate.save_calculation . Metode tersebut akan membuat serial argumen kedua sebagai JSON, sehingga dapat menyimpan segala jenis data.candidate.calculation(:your_thing) . Anda ingin menambahkan ini ke dalam respons API di file process.rb . Beginilah cara data mengalir melalui back end. Data keuangan diambil dari Netfile yang dilengkapi dengan Id Filer pemetaan Google Sheet untuk informasi surat suara seperti nama kandidat, kantor, surat suara, dll. Setelah data disaring, dikumpulkan, dan diubah, bagian depan menggunakannya dan membuat HTML statis ujung depan.
Selama Pemasangan Bundel
error: use of undeclared identifier 'LZMA_OK'
Mencoba:
brew unlink xz
bundle install
brew link xz
Selama make download
wget: command not found
Jalankan brew install wget .
Selama make import
Tampaknya ada masalah pada sistem Macintosh yang menggunakan Chip Apple.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
Coba yang berikut ini:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


