feathr
v1.0.0

Feathr adalah platform rekayasa data dan AI yang banyak digunakan dalam produksi di LinkedIn selama bertahun-tahun dan bersumber terbuka pada tahun 2022. Saat ini merupakan proyek di bawah LF AI & Data Foundation.
Baca pengumuman kami tentang Open Sourcing Feathr dan Feathr di Azure, serta pengumuman dari LF AI & Data Foundation.
Feathr memungkinkan Anda:
Feathr sangat berguna dalam pemodelan AI yang secara otomatis menghitung transformasi fitur Anda dan menggabungkannya ke data pelatihan Anda, menggunakan semantik yang tepat waktu untuk menghindari kebocoran data, dan mendukung perwujudan dan penerapan fitur Anda untuk digunakan secara online dalam produksi.
Cara termudah untuk mencoba Feathr adalah dengan menggunakan Feathr Sandbox yang merupakan wadah mandiri dengan sebagian besar kemampuan Feathr dan Anda akan produktif dalam 5 menit. Untuk menggunakannya, cukup jalankan perintah ini:
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0Dan Anda dapat melihat notebook jupyter quickstart Feathr:
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynbSetelah menjalankan notebook, semua fitur akan didaftarkan di UI, dan Anda dapat mengunjungi Feathr UI di:
http://localhost:8081Jika Anda ingin menginstal klien Feathr di lingkungan python, gunakan ini:
pip install feathrAtau gunakan kode terbaru dari GitHub:
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeathr memiliki integrasi asli dengan Databricks dan Azure Synapse:
Ikuti panduan penerapan Feathr ARM untuk menjalankan Feathr di Azure. Hal ini memungkinkan Anda dengan cepat memulai penerapan otomatis menggunakan templat Azure Resource Manager.
Jika Anda ingin menyiapkan semuanya secara manual, Anda dapat memeriksa panduan penerapan Feathr CLI untuk menjalankan Feathr di Azure. Hal ini memungkinkan Anda memahami apa yang sedang terjadi dan menyiapkan sumber daya satu per satu.
| Nama | Keterangan | Platform |
|---|---|---|
| Demo Taksi NYC | Buku catatan mulai cepat yang menampilkan cara menentukan, mewujudkan, dan mendaftarkan fitur dengan data sampel prediksi tarif taksi NYC. | Sinaps Azure, Databricks, Spark Lokal |
| Demo Taksi NYC Mulai Cepat Databricks | Buku catatan Quickstart Databricks dengan data sampel prediksi tarif taksi NYC. | Databricks |
| Penyematan Fitur | Contoh Feathr UDF menunjukkan cara menentukan dan menggunakan penyematan fitur dengan model Transformer terlatih dan data sampel ulasan hotel. | Databricks |
| Demo Deteksi Penipuan | Contoh untuk mendemonstrasikan Feature Store menggunakan berbagai sumber data seperti akun pengguna dan data transaksi. | Sinaps Azure, Databricks, Spark Lokal |
| Demo Rekomendasi Produk | Notebook contoh Feathr Feature Store dengan skenario rekomendasi produk | Sinaps Azure, Databricks, Spark Lokal |
Silakan baca Kemampuan Penuh Feathr untuk contoh lebih lanjut. Di bawah ini adalah beberapa yang dipilih:
Feathr menyediakan UI yang intuitif sehingga Anda dapat mencari dan menjelajahi semua fitur yang tersedia dan garis keturunannya yang sesuai.
Anda dapat menggunakan Feathr UI untuk mencari fitur, mengidentifikasi sumber data, melacak silsilah fitur, dan mengelola kontrol akses. Lihat demo langsung terbaru di sini untuk melihat apa yang Feathr UI dapat lakukan untuk Anda. Gunakan salah satu akun berikut ketika Anda diminta untuk login:
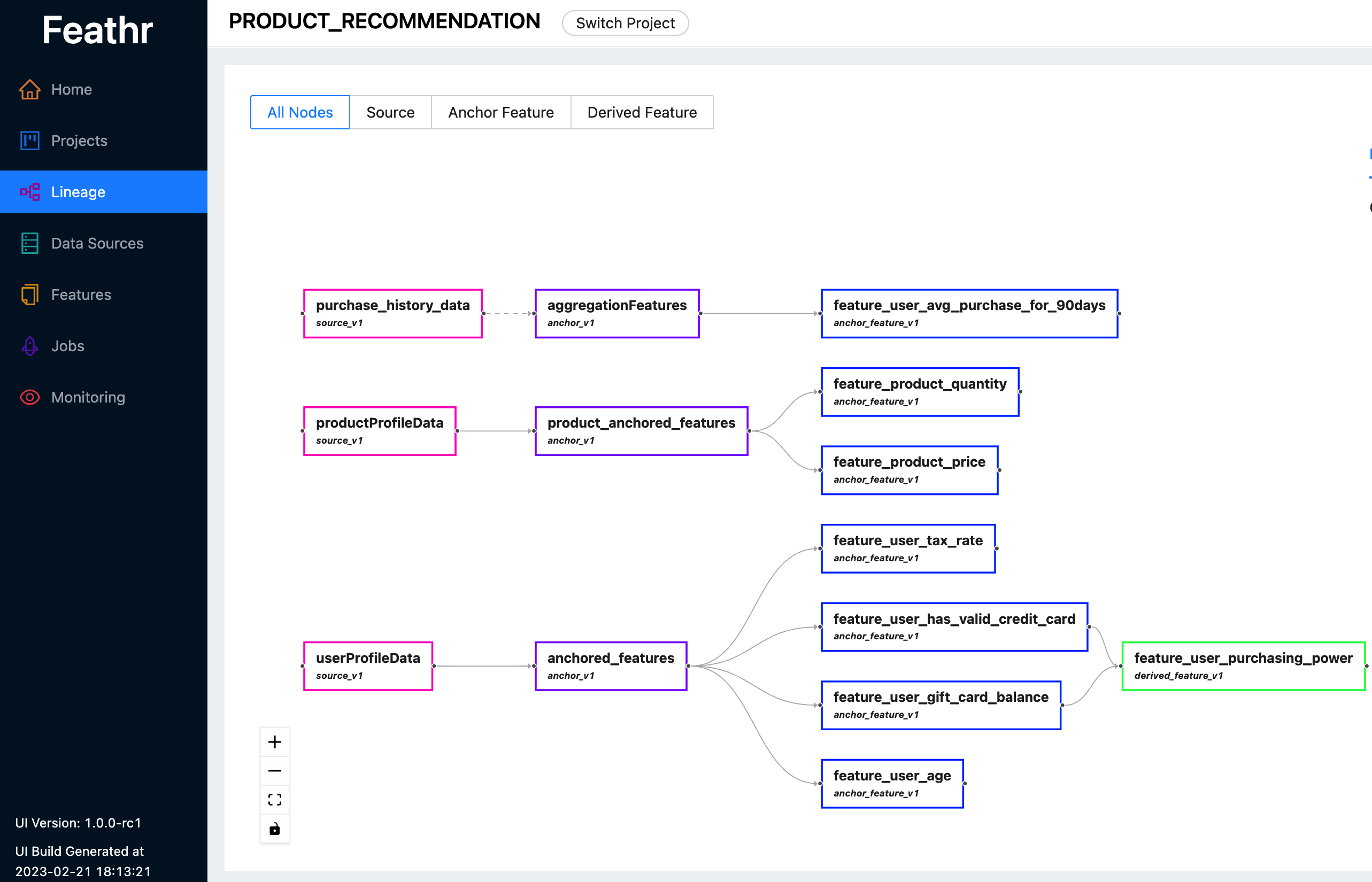
Untuk informasi lebih lanjut tentang Feathr UI dan registri di baliknya, silakan lihat Registri Fitur Feathr
Feathr memiliki UDF yang sangat dapat disesuaikan dengan integrasi PySpark dan Spark SQL asli untuk menurunkan kurva pembelajaran bagi ilmuwan data:
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )Baca Panduan Penyerapan Sumber Streaming untuk detail selengkapnya.
Baca Ketepatan Waktu dan Gabungan Waktu di Feathr untuk lebih jelasnya.
Ikuti panduan cepat Jupyter Notebook untuk mencobanya. Ada juga panduan memulai cepat pendamping yang berisi sedikit penjelasan lebih lanjut di buku catatan.
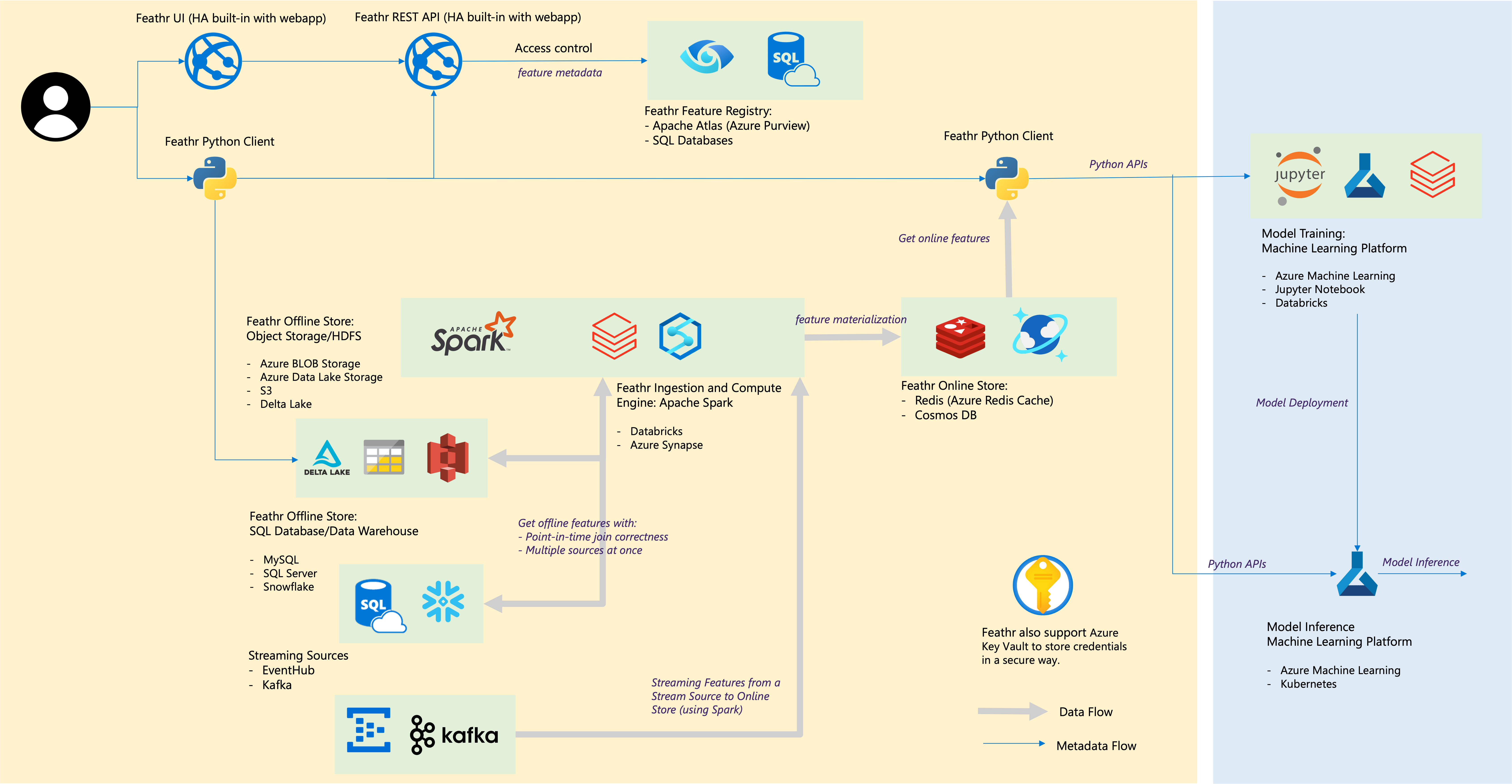
| Komponen bulu | Integrasi Awan |
|---|---|
| Toko offline – Toko Objek | Penyimpanan Blob Azure, Azure ADLS Gen2, AWS S3 |
| Toko offline – SQL | Azure SQL DB, Kumpulan SQL Khusus Azure Synapse, Azure SQL di VM, Snowflake |
| Sumber Streaming | Kafka, EventHub |
| Toko daring | Redis, Azure Cosmos DB |
| Fitur Registri dan Tata Kelola | Azure Purview, ANSI SQL seperti Azure SQL Server |
| Mesin Komputasi | Kumpulan Spark Azure Synapse, Databricks |
| Platform Pembelajaran Mesin | Pembelajaran Mesin Azure, Buku Catatan Jupyter, Buku Catatan Databricks |
| Format Berkas | Parket, ORC, Avro, JSON, Delta Lake, CSV |
| Kredensial | Gudang Kunci Azure |
Membangun untuk komunitas dan membangun oleh komunitas. Lihat Pedoman Komunitas.
Bergabunglah dengan saluran Slack kami untuk pertanyaan dan diskusi (atau klik tautan undangan).


